Spring Cloud 全链路追踪实现
简介
在微服务架构下存在多个服务之间的相互调用,当某个请求变慢或不可用时,我们如何快速定位服务故障点呢?链路追踪的实现就是为了解决这一问题,本文采用Sleuth+Zipkin+RabbitMQ+ES+Kibana实现。
Spring Cloud Sleuth

Trace:从客户端请求到系统边界,再到系统边界返回客户端响应。
Span:每一次调用埋入一个调用记录,即为 “Span”,一系列有序的Span构成一个Trace。
Zipkin
Zipkin 是由Twitter公司开源的一个分布式追踪系统,用于收集服务的定时数据,实现数据的收集、存储、查找和展现。提供了可插拔的数据存储方式:In-Memory、MySql、Cassandra以及Elasticsearch。
RabbitMQ
RabbitMQ是一个开源的AMQP实现,服务器端用Erlang语言编写,支持多种客户端,用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性等方面表现不俗。
Elasticsearch
Elasticsearch(ES)是一个基于Lucene构建的开源、分布式、RESTful接口的全文搜索引擎。Elasticsearch还是一个分布式文档数据库,其中每个字段均可被索引,而且每个字段的数据均可被搜索,ES能够横向扩展至数以百计的服务器存储以及处理PB级的数据。可以在极短的时间内存储、搜索和分析大量的数据。
Kibana
Kibana可以为 Logstash 和 ElasticSearch 提供友好的日志分析 Web 界面,可以实现汇总、分析和搜索重要数据日志。
实现
1、Zipkin服务端
创建zipkin-server项目(也可到官方网站:https://zipkin.io/下载jar包直接使用)
依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-server</artifactId>
<version>2.11.</version>
</dependency>
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-autoconfigure-ui</artifactId>
<version>2.11.</version>
</dependency>
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-autoconfigure-collector-rabbitmq</artifactId>
<version>2.11.</version>
</dependency>
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-autoconfigure-storage-elasticsearch-http</artifactId>
<version>2.8.</version>
</dependency>
配置
spring:
application:
name: zipkin-server
server:
port:
eureka:
client:
serviceUrl:
defaultZone: http://localhost:8088/eureka/
instance:
prefer-ip-address: true
management:
metrics:
web:
server:
auto-time-requests: false
zipkin:
collector:
rabbitmq:
addresses: 192.168.233.128
port:
username: zipkin
password: zipkin
virtual-host: vh1
queue: zipkin
storage:
StorageComponent: elasticsearch
type: elasticsearch
elasticsearch:
hosts: 192.168.233.171:
cluster: elasticsearch
index: zipkin
index-shards:
index-replicas:
启动类
@SpringBootApplication
@EnableEurekaClient
@EnableZipkinServer
public class ZipkinServerApplication {
public static void main(String[] args) {
SpringApplication.run(ZipkinServerApplication.class, args);
}
}
访问 http://localhost:8033/zipkin/
2、Zipkin客户端
依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
配置
spring:
sleuth:
sampler:
probability: 1.0
zipkin:
sender:
type: RABBIT
rabbitmq:
addresses: 192.168.233.128
port:
username: zipkin
password: zipkin
virtual-host: vh1
3、测试:
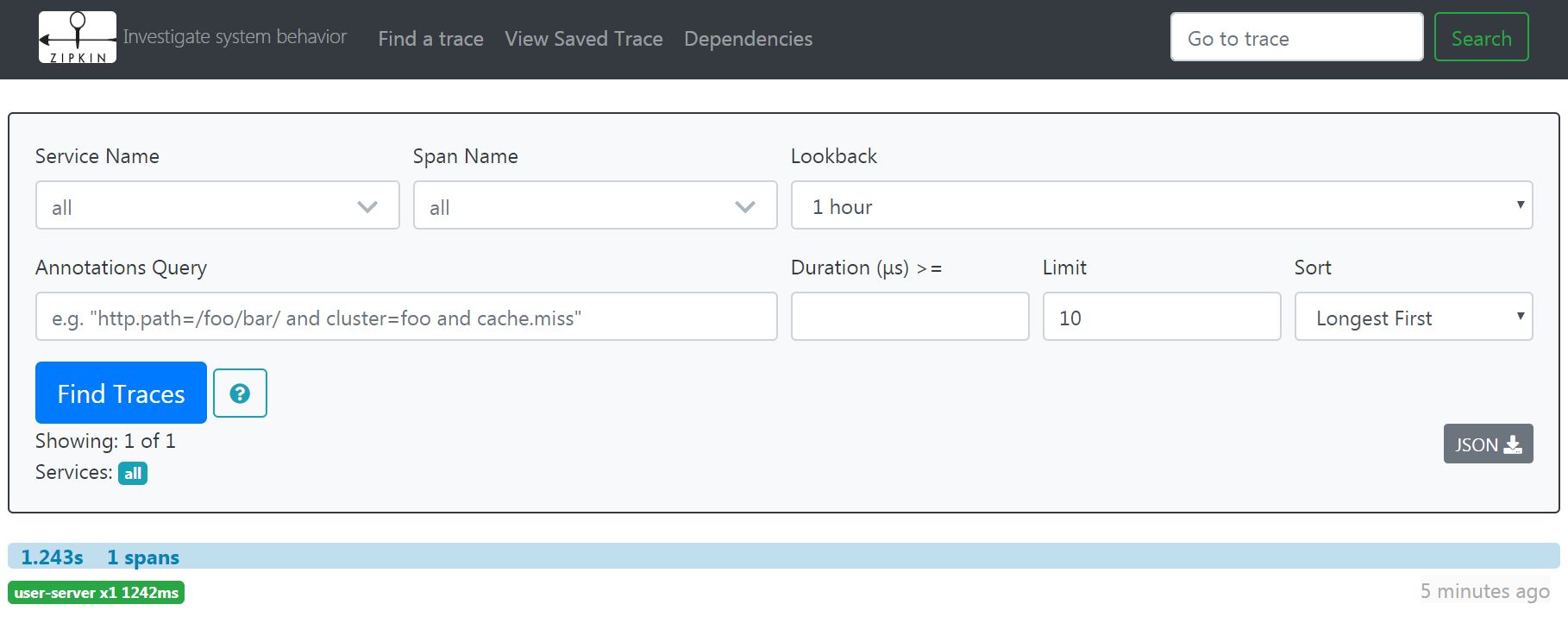
访问zipkin客户端服务,如我本地user-server http://localhost:8061/user/findAll

点“Find Traces”,看一下zipkin服务端
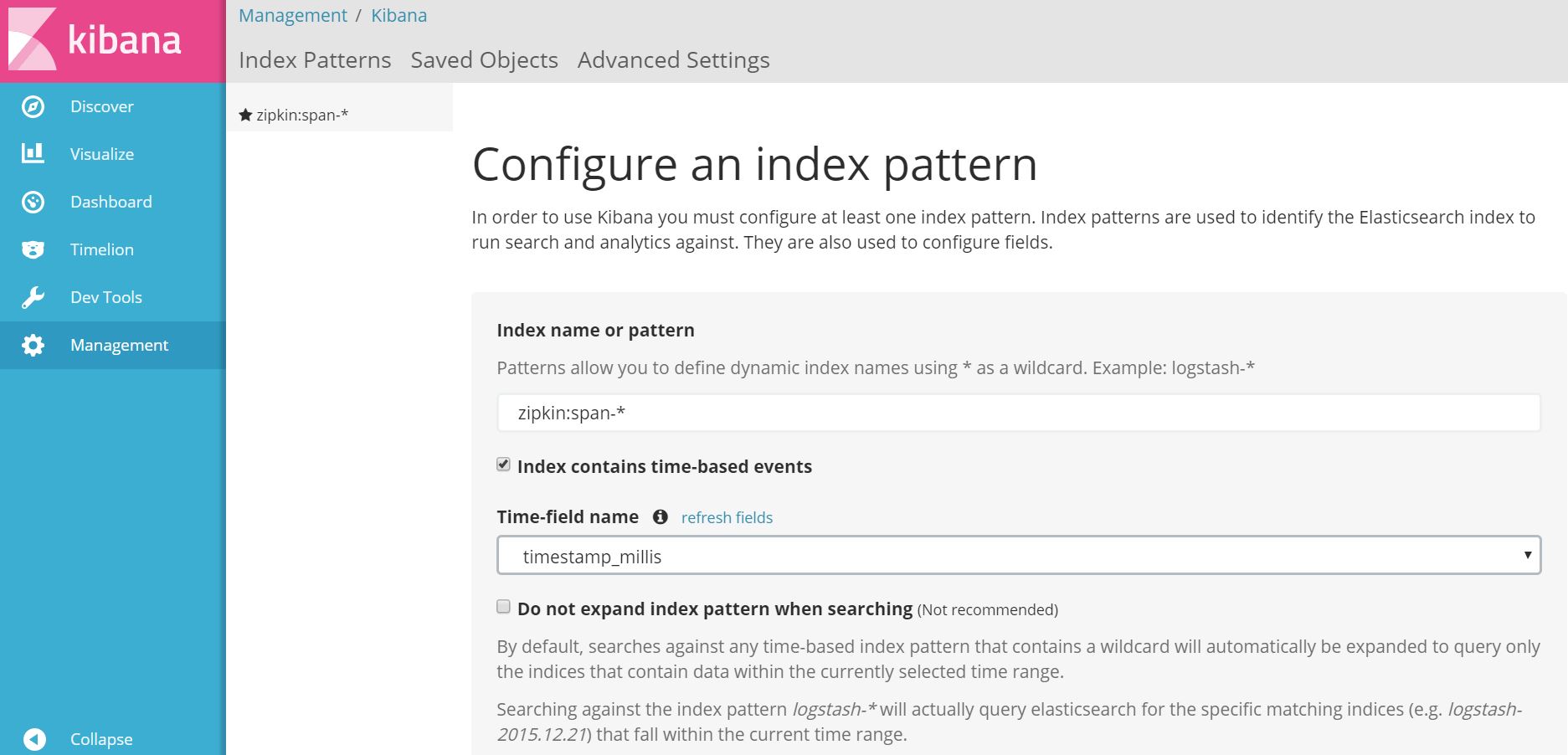
访问 http://192.168.233.171:5601 ,看一下Kibana,配置一个index pattern
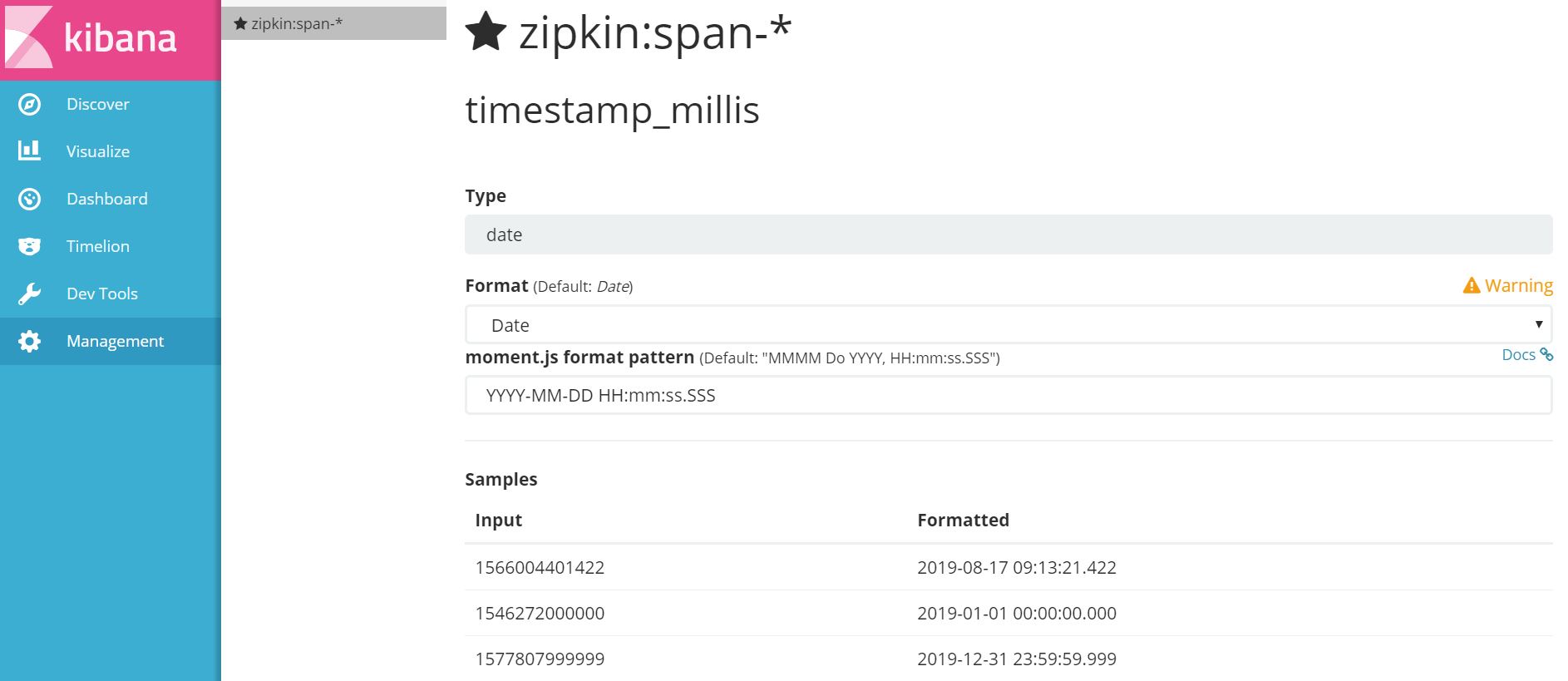
修改默认时间格式
看一下效果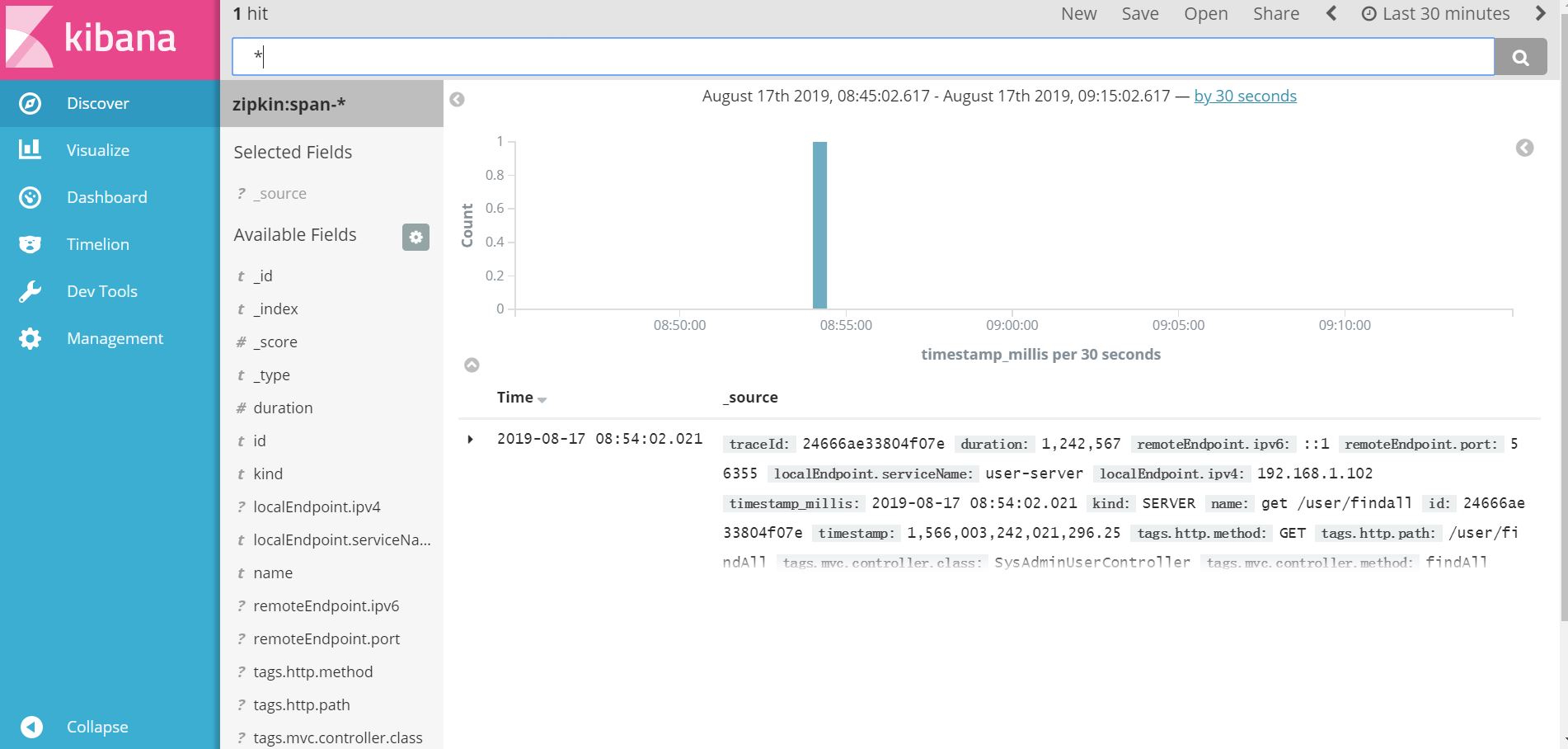
注:之前的图片不清楚,后来重新更新了图片,因此,图片上的时间会晚于文章时间。
Spring Cloud 全链路追踪实现的更多相关文章
- Spring Cloud全链路追踪实现(Sleuth+Zipkin+RabbitMQ+ES+Kibana)
简介 在微服务架构下存在多个服务之间的相互调用,当某个请求变慢或不可用时,我们如何快速定位服务故障点呢?链路追踪的实现就是为了解决这一问题,本文采用Sleuth+Zipkin+RabbitMQ+ES+ ...
- spring cloud 服务链路追踪 skywalking 6.1
随着微服务架构的流行,服务按照不同的维度进行拆分,一次请求往往需要涉及到多个服务.互联网应用构建在不同的软件模块集上,这些软件模块,有可能是由不同的团队开发.可能使用不同的编程语言来实现.有可能布在了 ...
- 基于SLF4J的MDC机制和Dubbo的Filter机制,实现分布式系统的日志全链路追踪
原文链接:基于SLF4J的MDC机制和Dubbo的Filter机制,实现分布式系统的日志全链路追踪 一.日志系统 1.日志框架 在每个系统应用中,我们都会使用日志系统,主要是为了记录必要的信息和方便排 ...
- 全链路追踪traceId,ThreadLocal与ExecutorService
关于全链路追踪traceId遇到线程池的问题,做过架构的估计都遇到过,现在以写个demo,总体思想就是获取父线程traceId,给子线程,子线程用完移除掉. mac上的chrome时不时崩溃,写了一大 ...
- go微服务框架kratos学习笔记九(kratos 全链路追踪 zipkin)
目录 go微服务框架kratos学习笔记九(kratos 全链路追踪 zipkin) zipkin使用demo 数据持久化 go微服务框架kratos学习笔记九(kratos 全链路追踪 zipkin ...
- skywalking与pinpoint全链路追踪方案对比
由于公司目前有200多微服务,微服务之间的调用关系错综复杂,调用关系人工维护基本不可能实现,需要调研一套全链路追踪方案,初步调研之后选取了skywalking和pinpoint进行对比; 选取skyw ...
- Node.js 应用全链路追踪技术——[全链路信息获取]
全链路追踪技术的两个核心要素分别是 全链路信息获取 和 全链路信息存储展示. Node.js 应用也不例外,这里将分成两篇文章进行介绍:第一篇介绍 Node.js 应用全链路信息获取, 第二篇介绍 N ...
- 【AWS】使用X-Ray做AWS云上全链路追踪监控系统
功能 AWS X-Ray 是一项服务,收集应用程序所请求的相关数据,并提供用于查看.筛选和获取数据洞察力的工具,以确定问题和发现优化的机会. 对于任何被跟踪的对您应用程序的请求,不仅可以查看请求和响应 ...
- Spring Cloud 分布式链路跟踪 Sleuth + Zipkin + Elasticsearch【Finchley 版】
随着业务越来越复杂,系统也随之进行各种拆分,特别是随着微服务架构的兴起,看似一个简单的应用,后台可能很多服务在支撑:一个请求可能需要多个服务的调用:当请求迟缓或不可用时,无法得知是哪个微服务引起的,这 ...
随机推荐
- Delphi - cxGrid内容xlsx、xls、csv格式导出
.xls格式导出,uses中添加cxGridExportLink 代码如下: function SaveToExcel(gridMain: TcxGrid; FileName: string): st ...
- Android Studio安卓学习笔记(一)安卓与Android Studio运行第一个项目
一:什么是安卓 1.Android是一种基于Linux的自由及开放源代码的操作系统. 2.Android操作系统最初由AndyRubin开发,主要支持手机. 3.Android一词的本义指“机器人”, ...
- Codeforces Round #381 (Div. 2) C. Alyona and mex(无语)
题目链接 http://codeforces.com/contest/740/problem/C 题意:有一串数字,给你m个区间求每一个区间内不含有的最小的数,输出全部中最小的那个尽量使得这个最小值最 ...
- Kafka源码分析及图解原理之Producer端
一.前言 任何消息队列都是万变不离其宗都是3部分,消息生产者(Producer).消息消费者(Consumer)和服务载体(在Kafka中用Broker指代).那么本篇主要讲解Producer端,会有 ...
- Day003_linux基础_系统启动过程及系统安装后优化
Linux系统启动过程: 打开电源开关开机 BIOS自检 MBR引导 grub内核菜单选择 加载内核kernel 运行init进程,系统初始化 然后读取/etc/inittab 配置文件,当前系统所在 ...
- NOIP要炸?
今天起床,翻我的群,突然看见一条消息: “NOIP要被禁赛了!” 莫名奇妙啊...... 于是我就进去看了看,网上疯传,搞得跟真的一样,差点吓到我了. 但好在每个人心中都有一个阿Q,会精神胜利法,于是 ...
- netcore 基于 DispatchProxy 实现一个简单Rpc远程调用
前言 netcore 发布以来,一直很关注netcore的进程.目前在公司负责的网站也历经波折的全部有.net framework 4.0 全部切换到netcore 2.2 版本中.虽然过程遇到的坑不 ...
- Android图片的缩放效果
一.概述 Android 图片要实现:手势滑动,双击变大,多点触控的效果. 其实是有一定难度的,我们需要用Matrix ,GestureDetector 等等需要完成一个复杂的逻辑才能实现,然而今天我 ...
- pageable多字段排序问题
Sort sort = new Sort(Sort.Direction.DESC, "createdate") .and(new Sort(Sort.Direction.AES, ...
- 简易数据分析 12 | Web Scraper 翻页——抓取分页器翻页的网页
这是简易数据分析系列的第 12 篇文章. 前面几篇文章我们介绍了 Web Scraper 应对各种翻页的解决方法,比如说修改网页链接加载数据.点击"更多按钮"加载数据和下拉自动加载 ...