Python 爬虫 爬取 煎蛋网 图片
今天, 试着爬取了煎蛋网的图片。
用到的包:
urllib.request
os
分别使用几个函数,来控制下载的图片的页数,获取图片的网页,获取网页页数以及保存图片到本地。过程简单清晰明了
直接上源代码:
import urllib.request
import os def url_open(url):
req = urllib.request.Request(url)
req.add_header('user-agent','Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36')
response = urllib.request.urlopen(url)
html = response.read() return html def get_page(url):
html = url_open(url).decode('utf-8') a = html.find('current-comment-page')+23
b = html.find(']',a) return html[a:b] def find_imgs(url):
html = url_open(url).decode('utf-8')
img_addrs = [] a = html.find('img src=') while a != -1:
b = html.find('.jpg',a ,a+255)
if b != -1:
img_addrs.append('https:'+html[a+9:b+4]) # 'img src='为9个偏移 '.jpg'为4个偏移
else:
b = a+9
a = html.find('img src=', b) return img_addrs def save_imgs(folder, img_addrs):
for each in img_addrs:
filename = each.split('/')[-1]
with open(filename, 'wb') as f:
img = url_open(each)
f.write(img)
print(img_addrs) def download_mm(folder = 'xxoo', pages = 5):
os.mkdir(folder)
os.chdir(folder) url = 'http://jandan.net/ooxx/'
page_num = int(get_page(url)) for i in range(pages):
page_num -= i
page_url = url + 'page-'+ str(page_num) + '#comments'
img_addrs = find_imgs(page_url)
save_imgs(folder, img_addrs) if __name__ == '__main__':
download_mm()
其中在主函数download_mm()中,将pages设置在了5面。
本来设置的是10,但是在程序执行的过程中。出现了404ERROR错误
即imgae_url出现了错误。尝试着在save_img()函数中加入了测试代码:print(img_addrs),
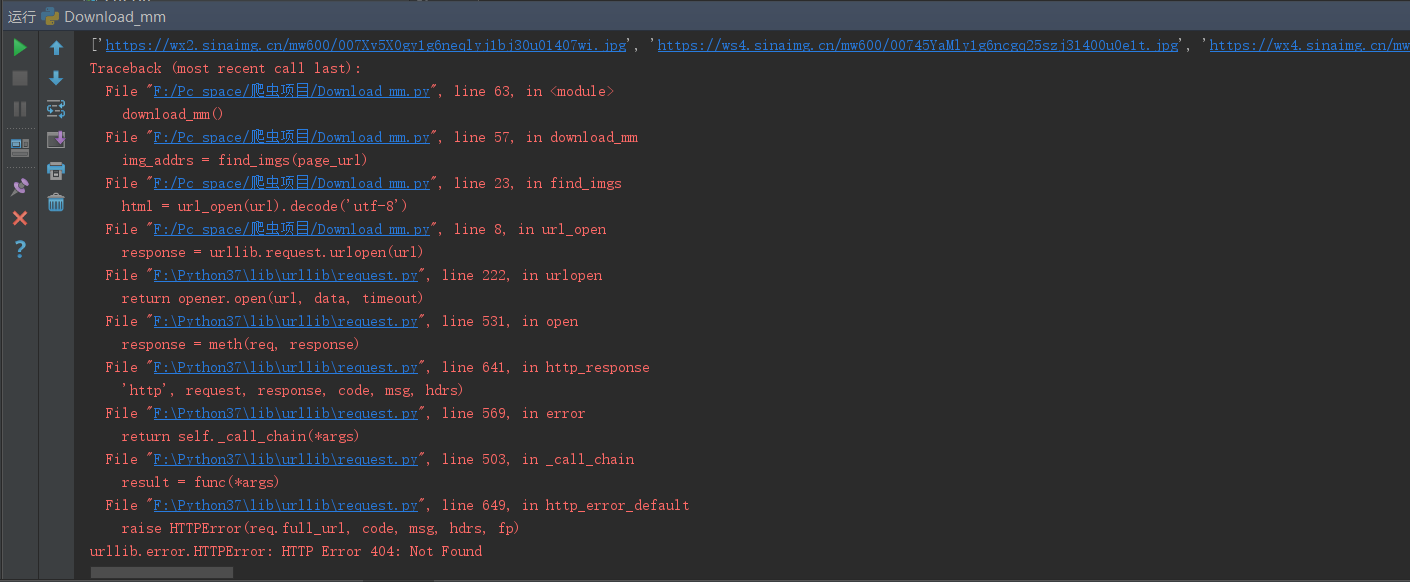
想到会不会是因为后面页数的图片,img_url的格式出现了改变,导致404,所以将pages改成5,
再次运行,结果没有问题,图片能正常下载:
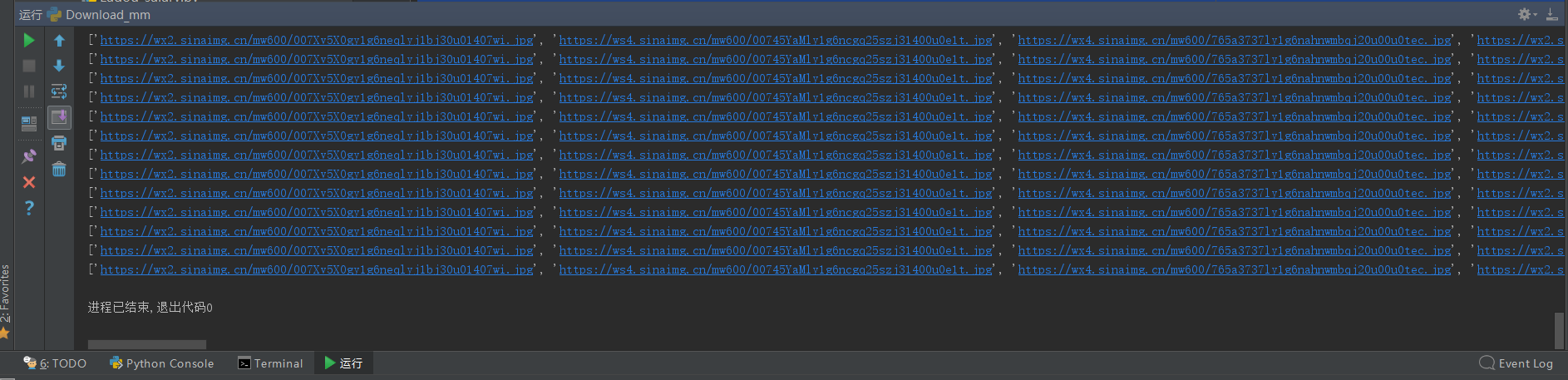
仔细观察发现,刚好是在第五面的图片往后,出现了不可下载的问题(404)。 所以在煎蛋网上,我们直接跳到第6面查看图片的url。

上图是后5面的图片url,下图是前5面的图片url

而源代码中,寻找的图片url为使用find()函数,进行定为<img src=‘’> <.jpg>中的图片url,所以后5面出现的a href 无法匹配,即出现了404 ERROR。如果想要下载后续的图片,需要重新添加一个url定位
即在find中将 img src 改成 a href,偏移量也需要更改。
总结:
使用find()来定位网页标签确实太过low,所以以后在爬虫中要尽量使用正则表达式和Beautifulsoup包来提高效率,而这两项我还不是特别熟,所以需要更多的训练。
Python 爬虫 爬取 煎蛋网 图片的更多相关文章
- python爬虫–爬取煎蛋网妹子图片
前几天刚学了python网络编程,书里没什么实践项目,只好到网上找点东西做. 一直对爬虫很好奇,所以不妨从爬虫先入手吧. Python版本:3.6 这是我看的教程:Python - Jack -Cui ...
- python爬虫爬取煎蛋网妹子图片
import urllib.request import os def url_open(url): req = urllib.request.Request(url) req.add_header( ...
- python3爬虫爬取煎蛋网妹纸图片(上篇)
其实之前实现过这个功能,是使用selenium模拟浏览器页面点击来完成的,但是效率实际上相对来说较低.本次以解密参数来完成爬取的过程. 首先打开煎蛋网http://jandan.net/ooxx,查看 ...
- Python Scrapy 爬取煎蛋网妹子图实例(一)
前面介绍了爬虫框架的一个实例,那个比较简单,这里在介绍一个实例 爬取 煎蛋网 妹子图,遗憾的是 上周煎蛋网还有妹子图了,但是这周妹子图变成了 随手拍, 不过没关系,我们爬图的目的是为了加强实战应用,管 ...
- scrapy从安装到爬取煎蛋网图片
下载地址:https://www.lfd.uci.edu/~gohlke/pythonlibs/pip install wheelpip install lxmlpip install pyopens ...
- python3爬虫爬取煎蛋网妹纸图片(下篇)2018.6.25有效
分析完了真实图片链接地址,下面要做的就是写代码去实现了.想直接看源代码的可以点击这里 大致思路是:获取一个页面的的html---->使用正则表达式提取出图片hash值并进行base64解码--- ...
- Python Scrapy 爬取煎蛋网妹子图实例(二)
上篇已经介绍了 图片的爬取,后来觉得不太好,每次爬取的图片 都在一个文件下,不方便区分,且数据库中没有爬取的时间标识,不方便后续查看 数据时何时爬取的,所以这里进行了局部修改 修改一:修改爬虫执行方式 ...
- python爬取煎蛋网图片
``` py2版本: #-*- coding:utf-8 -*-#from __future__ import unicode_literimport urllib,urllib2,timeimpor ...
- selenium爬取煎蛋网
selenium爬取煎蛋网 直接上代码 from selenium import webdriver from selenium.webdriver.support.ui import WebDriv ...
随机推荐
- Java获取两个日期之间的所有日期集合
1.返回Date的list private List<Date> getBetweenDates(Date start, Date end) { List<Date> resu ...
- Spring MVC+ajax进行信息验证
本文是一个ajax结合Spring MVC使用的入门,首先我们来了解一下什么是Ajax AJAX 不是新的编程语言,而是一种使用现有标准的新方法.AJAX 最大的优点是在不重新加载整个页面的情况下,可 ...
- cobbler高可用方案
一.环境准备 主网IP 私网IP 主机名 角色 VIP 10.203.178.125 192.168.10.2 cnsz22VLK12919 主 10.203.178.137,192.168.10.1 ...
- Redis集群增加节点和删除节点
本文主要是承接上一篇文章Redis集群的离线安装成功以后,我们如何进行给集群增加新的主从节点(集群扩容)以及如何从集群中删除节点(集群缩容),也就是集群的伸缩,集群伸缩的原理是控制虚拟槽和数据在节点之 ...
- Java中各种引用(Reference)解析
目录 1,引用类型 2, FinalReference 2.1, Finalizer 3, SoftReference 4, WeakReference 5, PhantomReference 6, ...
- apache ignite系列(三):数据处理(数据加载,数据并置,数据查询)
使用ignite的一个常见思路就是将现有的关系型数据库中的数据导入到ignite中,然后直接使用ignite中的数据,相当于将ignite作为一个缓存服务,当然ignite的功能远不止于此,下面以 ...
- django学之路01--环境安装和pycharm运行django项目
1. 环境安装 1).virtualenv安装 C:\Users\Administrator>pip install virtualenv Collecting virtualenv Using ...
- [3]尝试用Unity3d制作一个王者荣耀(持续更新)->选择英雄-(中)
如果已经看过本章节:目录传送门:这是目录鸭~ 上节内容写了Actor管理器,那么这一节让我们先创建一个角色.(此章节开始加速...) 1.制作角色展示AssetBundle: 提取农药某个展示模型(S ...
- 配置hibernate访问mysql
在之前搭建spring mvc项目这篇的基础上继续集成,引入hibernate支持 一.添加jar包引用 修改pom.xml文件,加入: <dependency> <groupId& ...
- Falsk中的Request、Response
Flask 中的Response 1.HTTPResponse('helloword') "helloword" from flask import Flask # 实例化Flas ...