Python Scrapy 爬取煎蛋网妹子图实例(二)
上篇已经介绍了 图片的爬取,后来觉得不太好,每次爬取的图片 都在一个文件下,不方便区分,且数据库中没有爬取的时间标识,不方便后续查看 数据时何时爬取的,所以这里进行了局部修改
修改一:修改爬虫执行方式
之前爬虫的执行 是通过在终端输入命令:scrapy crawl spiderName 执行
缺点:
1、需要记住并输入命令;
2、需要在终端切换到爬虫上一级目录下执行。
创建执行入口
如图
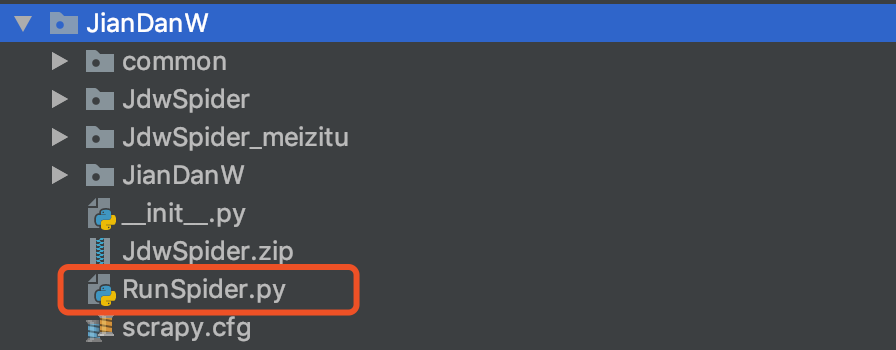
代码如下
# FileName : RunSpider.py
# Author : Adil
# DateTime : 2018/12/4 2:51 PM
# SoftWare : PyCharm from scrapy.crawler import CrawlerProcess
from scrapy.utils.project import get_project_settings process = CrawlerProcess(get_project_settings()) # 此处添加 执行爬虫 名字,具体可以查看 源码
process.crawl('JdwSpider') process.start()
修改二:修改图片存放路径
之前是在执行路径下依照spiderName 创建了一个文件夹,用来存放图片。
缺点:
1、每次执行爬虫所有图片都会存放在该文件下,日积月累,图片会越来越多,不方便查找和归类
创建新的文件路径
根据爬取日期创建文件进而分类,方便查看不同时间对应的爬取结果
展示结果如下:

修改三:数据增加爬取时间
如图,方便以爬取时间进行区分爬取内容。
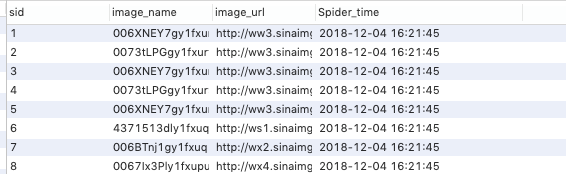
最后修改后代码如下:
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import os
import urllib
import time
import common.DBHandle as DBHandle class JiandanwPipeline(object): def __init__(self):
'''
初始化文件路径及 爬取时间
'''
# 获取当前路径
currentPath = os.getcwd()
# 拼接图片存放路径
file_path = os.path.join(currentPath, 'JdwSpider')
# 增加 按日期创建文件
localTime = time.localtime(time.time())
localTimeStrs = time.strftime("%Y-%m-%d %H:%M:%S", localTime)
# 再次拼接路径
file_path = os.path.join(file_path, localTimeStrs)
if not os.path.exists(file_path):
os.makedirs(file_path)
# 初始化 两个 变量,方便 后面的 方法使用
self.file_path = file_path
self.localTimeStrs = localTimeStrs
# 数据库连接 这里的 数据库信息,因为是本地数据库,后面如果是公司数据库 不方便透露的话,可以存放到配置文件中
host = '127.0.0.1'
username = 'adil'
password = 'helloyyj'
database = 'AdilTest'
port = 3306
# 实例化 数据库 连接
self.DbHandle = DBHandle.DataBaseHandle(host, username, password, database, port) def process_item(self, item, spider):
''' 爬虫文件数据处理函数 ''' # 这里是一页 算一个 item ,所以如果 将 文件信息 写在这里,会导致一页创建一次,所以 放在初始化函数内进行
# # 获取当前路径
# currentPath = os.getcwd()
# # 拼接图片存放路径
# file_path = os.path.join(currentPath, spider.name)
#
# # 增加 按日期创建文件
# localTime = time.localtime(time.time())
# localTimeStrs = time.strftime("%Y-%m-%d %H:%M:%S", localTime)
# # 再次拼接路径
# file_path = os.path.join(file_path, localTimeStrs)
#
# if not os.path.exists(file_path):
# os.makedirs(file_path) for image_url in item['image_urls']:
# 截图图片链接
list_name = image_url.split('/')
# 获取图片名称
file_name = list_name[len(list_name) - 1] # 图片名称
# 补全图片路径
path_name = os.path.join(self.file_path,file_name)
# 获取有效的url 因为 image_url = //wx4.sinaimg.cn/mw600/66b3de17gy1fxo6jis4iej21ma0u0x6r.jpg
image_url = 'http:' + image_url
# 此处执行 数据库插入,将 图片名称、url 插入到数据库 注意 这里的 values('占位符 一定要用 引号引起来,要不然执行不成功,血的教训')
sql = "insert into JdwSpider(image_name,image_url,Spider_time) values ('%s','%s','%s')" % (file_name,image_url,self.localTimeStrs)
# 如果不执行插入,可以注释改该行代码
self.DbHandle.insertDB(sql) # 图片保存
with open(path_name, 'wb') as file_writer:
conn = urllib.request.urlopen(image_url) # 下载图片
# 保存图片
file_writer.write(conn.read())
file_writer.close() return item def close_spider(self,spider):
''' 定义爬虫结束处理函数 此处会在 爬虫结束后执行该方法 '''
# 关闭数据库,
print('****'*50)
print('数据库关闭')
self.DbHandle.closeDb()
Python Scrapy 爬取煎蛋网妹子图实例(二)的更多相关文章
- Python Scrapy 爬取煎蛋网妹子图实例(一)
前面介绍了爬虫框架的一个实例,那个比较简单,这里在介绍一个实例 爬取 煎蛋网 妹子图,遗憾的是 上周煎蛋网还有妹子图了,但是这周妹子图变成了 随手拍, 不过没关系,我们爬图的目的是为了加强实战应用,管 ...
- python爬虫–爬取煎蛋网妹子图片
前几天刚学了python网络编程,书里没什么实践项目,只好到网上找点东西做. 一直对爬虫很好奇,所以不妨从爬虫先入手吧. Python版本:3.6 这是我看的教程:Python - Jack -Cui ...
- python爬虫爬取煎蛋网妹子图片
import urllib.request import os def url_open(url): req = urllib.request.Request(url) req.add_header( ...
- Python 爬虫 爬取 煎蛋网 图片
今天, 试着爬取了煎蛋网的图片. 用到的包: urllib.request os 分别使用几个函数,来控制下载的图片的页数,获取图片的网页,获取网页页数以及保存图片到本地.过程简单清晰明了 直接上源代 ...
- Python 爬取煎蛋网妹子图片
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Date : 2017-08-24 10:17:28 # @Author : EnderZhou (z ...
- selenium爬取煎蛋网
selenium爬取煎蛋网 直接上代码 from selenium import webdriver from selenium.webdriver.support.ui import WebDriv ...
- python3爬虫爬取煎蛋网妹纸图片(上篇)
其实之前实现过这个功能,是使用selenium模拟浏览器页面点击来完成的,但是效率实际上相对来说较低.本次以解密参数来完成爬取的过程. 首先打开煎蛋网http://jandan.net/ooxx,查看 ...
- scrapy从安装到爬取煎蛋网图片
下载地址:https://www.lfd.uci.edu/~gohlke/pythonlibs/pip install wheelpip install lxmlpip install pyopens ...
- 爬虫实例——爬取煎蛋网OOXX频道(反反爬虫——伪装成浏览器)
煎蛋网在反爬虫方面做了不少工作,无法通过正常的方式爬取,比如用下面这段代码爬取无法得到我们想要的源代码. import requests url = 'http://jandan.net/ooxx' ...
随机推荐
- 11: python中的轻量级定时任务调度库:schedule
1.1 schedule 基本使用 1.schedule 介绍 1. 提到定时任务调度的时候,相信很多人会想到芹菜celery,要么就写个脚本塞到crontab中. 2. 不过,一个小的定时脚本,要用 ...
- python简说(七)元组,集合
一.元组 元组也是一个list,但是它的值不能改变 定义元组的时候,只有一个元素,后面得加逗号 oracle_info = (123,) 二.集合 1.集合天生就可以去重,集合是无序的 2.#交集 r ...
- Codeforces 817C Really Big Numbers - 二分法 - 数论
Ivan likes to learn different things about numbers, but he is especially interested in really big nu ...
- linux 压缩工具
gzip gunzip zcat bzip2 bunzip2 bzcat xz unxz xzcat a: gzip 用法 # gzip file 压缩文件 不会保留源文件 直接生成 file.g ...
- tar+nc传输文件的使用
- CSS的再一次深入(更新中···)
全面我们学了6个选择器,今天再来学习两个选择器,分别是通配符选择器和并集选择器: 1.通配符选择器: *{ } 表示body里所有的标签都被选中 2.并集选择器: 选中的标签之间用逗号隔开,表示这几个 ...
- Python 正则表达式学习
摘要 在正则表达式中,如果直接给出字符,就是精确匹配. {m,n}? 对于前一个字符重复 m到 n 次,并且取尽可能少的情况 在字符串'aaaaaa'中,a{2,4} 会匹配 4 个 a,但 a{2, ...
- Pollard Rho大质数分解学习笔记
目录 问题 流程 代码 生日悖论 end 问题 给定n,要求对n质因数分解 普通的试除法已经不能应用于大整数了,我们需要更快的算法 流程 大概就是找出\(n=c*d\) 如果\(c\)是素数,结束,不 ...
- R t-test cor.test
a = c(175, 168, 168, 190, 156, 181, 182, 175, 174, 179)b = c(185, 169, 173, 173, 188, 186, 175, 174, ...
- 深度学习 目标检测算法 SSD 论文简介
深度学习 目标检测算法 SSD 论文简介 一.论文简介: ECCV-2016 Paper:https://arxiv.org/pdf/1512.02325v5.pdf Slides:http://w ...