Scrapy-Splash简介及验证码的处理(一)
在之前的博客中,我们学习了selenium的用法,它是一个动态抓取页面的方法,但是,动态抓取页面还有其他的方法,这里介绍Splash方法,并结合具体实例进行讲解。
一:Splash简介与准备
1.简介
Splash是一个JavaScript渲染服务,说到js大家肯定会想到网页,对的,Splash是Scrapy中支持JavaScrapy渲染的工具,是一个带有HTTP API的轻量级浏览器,可以进行动态渲染页面的抓取。
2.安装
Scrapy-Splash安装有两个方法,这里我们用Docker进行安装,因此首先要安装Docker(多容器技术,将应用和环境进行打包,形成一个独立的"应用",可以让每个应用隔离,适合于大规模爬虫系统),下载地址为:
https://docs.docker.com/docker-for-windows/install/
下载后安装,会出现 docker desktop requires Windows 10 Pro or Enterprise version 15063问题。
这个问题是windows10家庭版不支持Hyper-V,无法安装docker,需要下载docker toolbox安装。地址为:
http://mirrors.aliyun.com/docker-toolbox/windows/docker-toolbox/
也可以开启Hyper-V进行安装,这里就不具体说明了。
安装后打开cmd控制台,会有下面的结果,说明运行成功(安装的过程很麻烦,需要耐心):
下面就是用安装Scrapy-Splash了,安装的命令为:
docker run -p 8050:8050 scrapinghub/splash
这里的话,我在环境配置上出了问题,再bios中把Intel Virtualization Technology已经设置为enable,但是再运行docker时还是出现了问题,在外部的因特尔虚拟化技术已经打开了,但是却用不了virutualBox虚拟机。这里等到之后的博客,继续为大家讲解Splash。如果大家有知道原因的话,可以和我交流。

二:验证码的识别(1)
现在,许多网站都用各种各样的措施进行反爬虫,其中一项就是用验证码。而且验证码现在已经发展得有很多种,而且交互式验证码已经越来越流行,需要鼠标操作的也越来越多,这也造成爬虫的工作越发艰难,下面就先介绍如何用python识别常见的一种图形验证码。
图形验证码的识别
图形验证码是最早的验证码,很常见,一般有字母和数字组成,我们先保存网上的一些验证码图片,如下:
(1)使用的识图技术
OCR技术:光学字符识别,是指通过扫描字符·,然后通过形状将其翻译成电子文本的过程。
(2)识图用到的库
tesserocr库:Python的一个OCR识别库,是对tesseract做的一层封装,因此需要先安装tesseract,然后安装tesserocr,安装过程这里就不详讲了。
(3)识图方法实现
import tesserocr
from PIL import Image
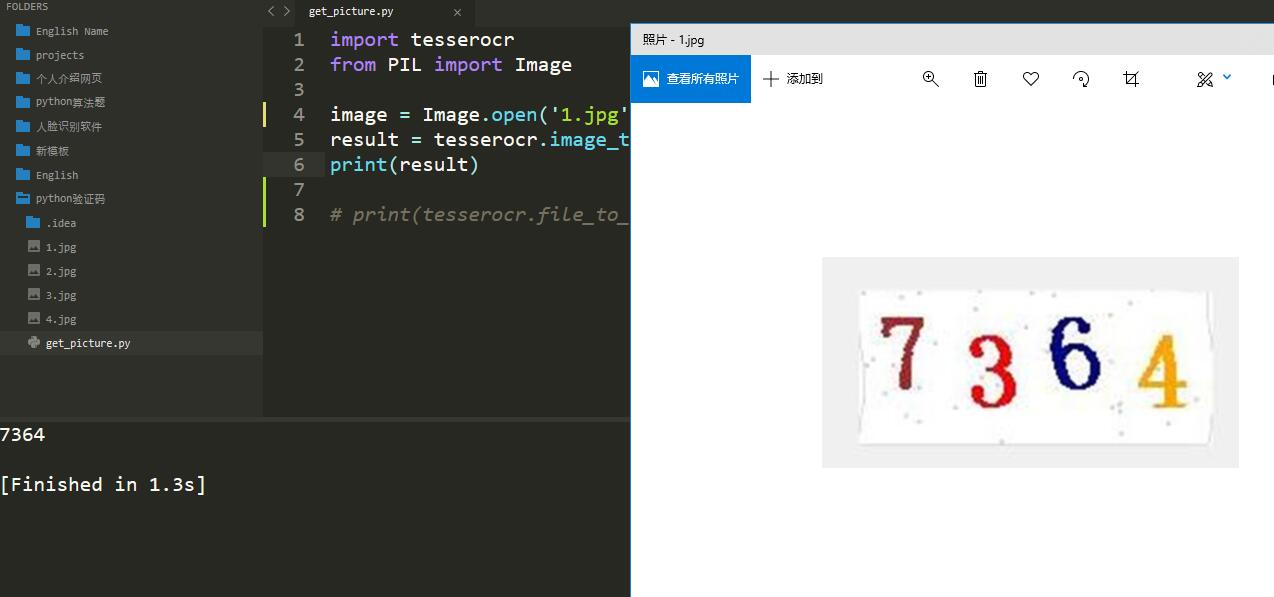
image = Image.open('1.jpg')
result = tesserocr.image_to_text(image)
print(result)
识别前后的图片和结果如下:
还有其他方法也可以识别验证码,就是用file_to_text()方法直接将图片文件转化为字符串,我们换张图片如下:
print(tesserocr.file_to_text('2.jpg'))
识别前后的图片和结果如下:
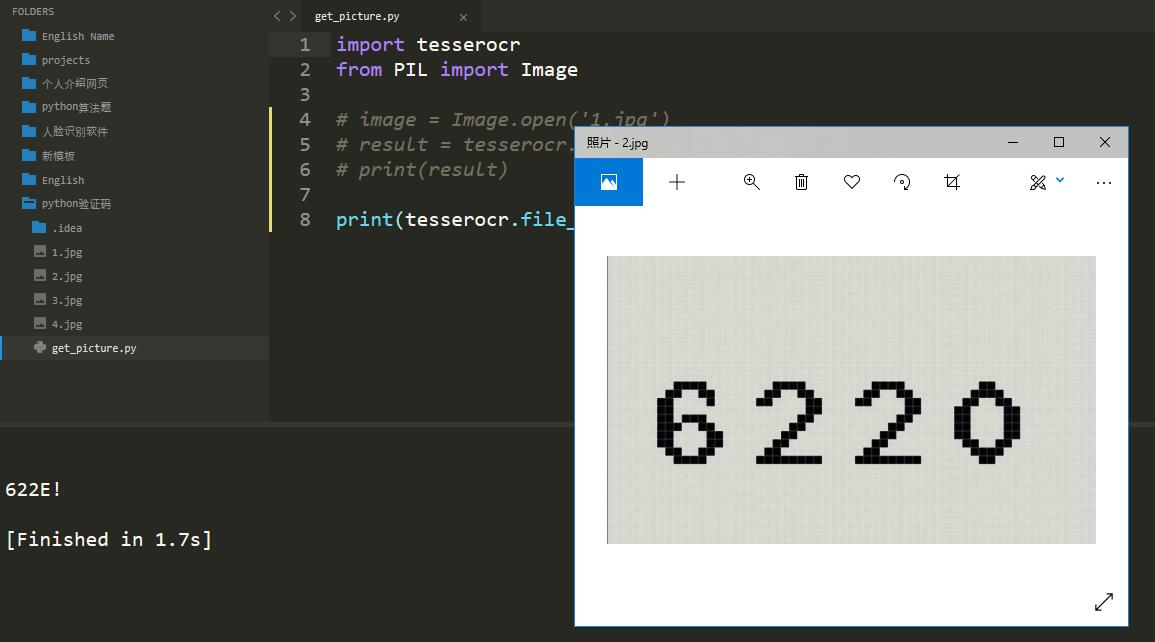
我们看到识别的结果和我们想要的有所区别,但其实是线条阻挡了,在下面的博客中会介绍如何处理。
其他的验证码识别如下:

Scrapy-Splash简介及验证码的处理(一)的更多相关文章
- 爬虫基础(五)-----scrapy框架简介
---------------------------------------------------摆脱穷人思维 <五> :拓展自己的视野,适当做一些眼前''无用''的事情,防止进入只关 ...
- scrapy splash 之一二
scrapy splash 用来爬取动态网页,其效果和scrapy selenium phantomjs一样,都是通过渲染js得到动态网页然后实现网页解析, selenium + phantomjs ...
- 爬虫开发7.scrapy框架简介和基础应用
scrapy框架简介和基础应用阅读量: 1432 scrapy 今日概要 scrapy框架介绍 环境安装 基础使用 今日详情 一.什么是Scrapy? Scrapy是一个为了爬取网站数据,提取结构性数 ...
- scrapy+splash 爬取京东动态商品
作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3159 splash是容器安装的,从docker官网上下载windows下的 ...
- scrapy架构简介
一.scrapy架构介绍 1.结构简图: 主要组成部分:Spider(产出request,处理response),Pipeline,Downloader,Scheduler,Scrapy Engine ...
- Python scrapy爬取带验证码的列表数据
首先所需要的环境:(我用的是Python2的,可以选择python3,具体遇到的问题自行解决,目前我这边几百万的数据量爬取) 环境: Python 2.7.10 Scrapy Scrapy 1.5.0 ...
- Scrapy+splash报错 Connection was refused by other side
报错信息如下: Traceback (most recent call last): File "/usr/local/lib/python3.7/site-packages/scrap ...
- Scrapy 框架简介
Scrapy 框架 介绍 Scrapy一个开源和协作的框架,其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的,使用它可以以快速.简单.可扩展的方式从网站中提取所需的数据.但目前Scrapy的 ...
- 爬虫(九)scrapy框架简介和基础应用
概要 scrapy框架介绍 环境安装 基础使用 一.什么是Scrapy? Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍.所谓的框架就是一个已经被集成了各种功能 ...
随机推荐
- Python、PyCharm、django环境搭建
本文又名—— 响应式页面——从无到有(一) 事情是这样的,期末小组作业,需要我把大佬们写的页面搞成响应式的,但是我连py都没用过,只好现学…… 文章目录 一.前言 1.1 环境介绍 1.2 前期尝试 ...
- Redis之自问自答
Q:Redis客户端的批处理大量数据请求时,如何优化请求速率? A:管道技术:Redis是基于客户端-服务端模型的TCP请求/响应服务,且是阻塞式的,客户端需要等待服务端处理完数据后返回状态,才能继续 ...
- [20190918]关于函数索引问题.txt
[20190918]关于函数索引问题.txt 1.环境:SCOTT@test01p> @ ver1PORT_STRING VERSION BA ...
- 访问rabbitmq-server失败
测试项目正常运行突然访问不了,各项目启动失败,查看日志发现是RabbitMQ拒绝连接. 重启后依然失败,看var/log/rabbitmq/startup_err 发现什么错误信息也没有,后查看磁盘空 ...
- docker容器跨服务器的迁移的方法
docker的备份方式有export和save两种. export是当前的状态,针对的是容器,docker save 是针对镜像images. export 找出要备份容器的ID ? 1 2 3 [r ...
- [PHP] PDO对象与mysql的连接超时
在php中每一个new的PDO对象,都会去连接mysql,都会创建一条tcp连接.当pdo对象赋予的变量是一个的时候,那么他只会保持一个tcp连接,没有被引用的对象连接会直接断掉.如果不对这个对象进行 ...
- Mybatis逆向工程中的 mybatis-generator:generate 代码生成器的使用
使用逆向工程可以根据数据库的表名字生成pojo层(实体类),mapper层(dao层,直接与底层的XML中映射相关),XML(映射执SQL语句) 下面请看具体生成步骤 1. 点击generatorCo ...
- C++中的异常处理(下)
array.h #ifndef _ARRAY_H_ #define _ARRAY_H_ #include <stdexcept> using namespace std; template ...
- 动态内存的分配(new delete malloc free)
new和malloc的区别是什么?-new关键字是C++的一部分,在所有的C++编译器中都被支持-malloc是由C库提供的函数,在某些系统开发中是不能调用的-new以具体类型为单位进行内存分配-ma ...
- [PHP] Laravel5.5 使用 laravel-cors 实现 Laravel 的跨域配置
Laravel5.5 使用 laravel-cors 实现 Laravel 的跨域配置 最开始的时候,我使用的是路由中间件的方式,但是发现中间件不起作用 这是之前使用的方式: 'cros' => ...