简易数据分析 15 | Web Scraper 高级用法——CSS 选择器的使用

这是简易数据分析系列的第 15 篇文章。
年末事情比较忙,很久不更新了,后台一直有读者催更,我看了一些读者给我的私信,发现一些通用的问题,所以单独写篇文章,介绍一些 Web Scraper 的进阶用法。
今天我们就来学习一些 CSS 选择器的知识,辅助 Web Scraper 更好的定位要选择的元素。
一、定位 HTML 节点
HTML 是什么?它是一个网页的骨架,是最最基础的东西。比如说你现在看的这篇文章,其实就是一个网页,每一行字都是 HTML 里的一个 <p> 标签。
网页就是由一行一行的 HTML 标签垒起来的,所以我们用 Web Scraper 的 Selector 选择的元素,本质上都是 HTML 标签,都是一个一个的 HTML 节点。
使用 Web Scraper 的 Selector 自动选择元素时,有时候选的节点不准,抓不到数据,这时候就要我们手动调节 Selector 生成的代码。那么第一个问题就来了,如何在网页里定位我们需要的 HTML 节点?
我们按 F12 打开网页的调试面板时,调试面板左上角有个箭头,我们点击一下,等箭头变成蓝色时,移动到我们要抓取节点的位置,然后再点击一下,就会自动定位这个 HTML 节点的位置。
下面请我们的老朋友——豆瓣电影TOP250,来演示一下如何定位。比如说我们想定位《肖申克的救赎》的电影名字,按照上面的步骤走一遍流程,动图如下:
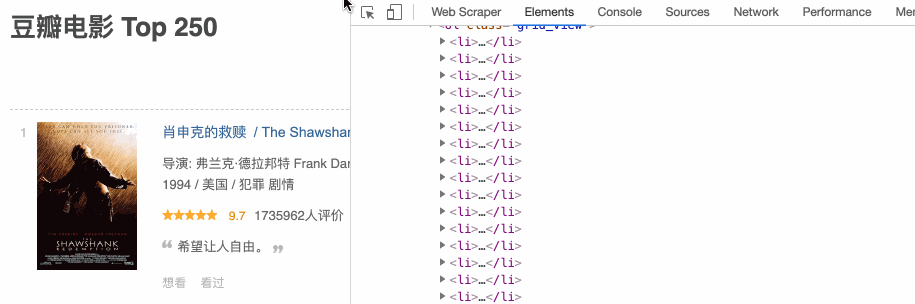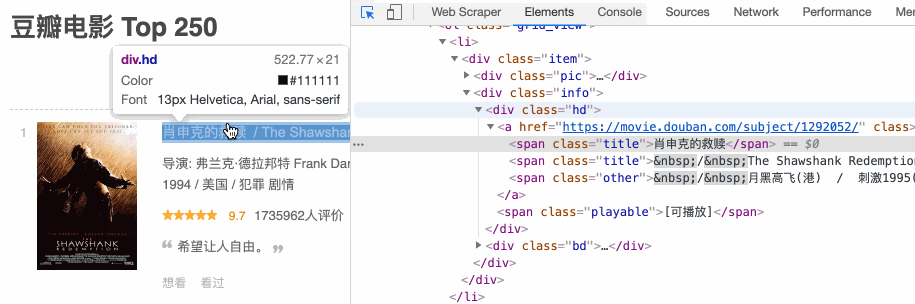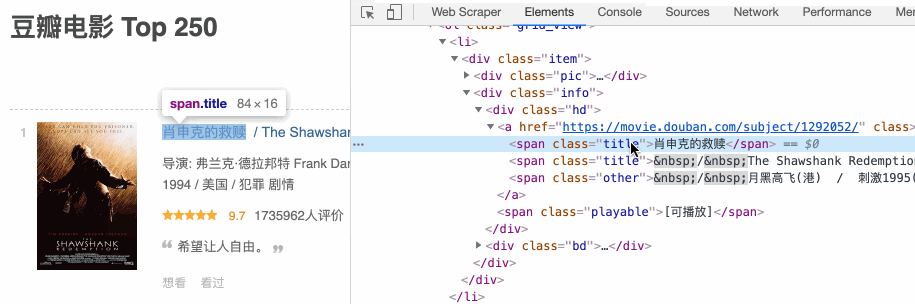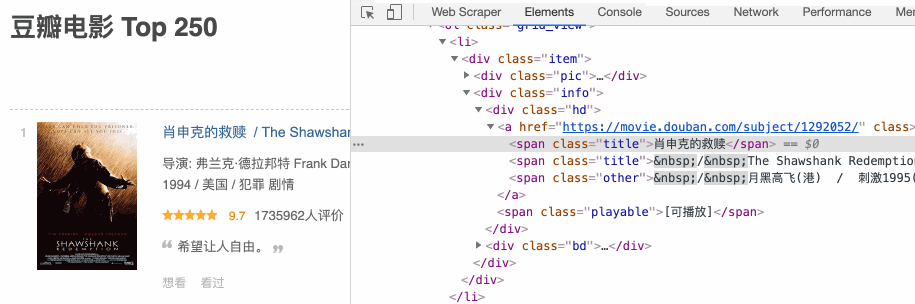
是不是非常的简单?借助这个小箭头,我们可以很轻松的定位 HTML 节点。
二、CSS 选择器
CSS 是个什么东西?先不要管它为什么叫 CSS,这不重要。我们只要关注 CSS 是干什么的就行了。
有一个非常形象的比喻:HTML 是骨架,CSS 是衣服。如果世界上只有 HTML,那网页就全是千篇一律的 word 文档了,只有加上 CSS 的修饰,才有现在绚丽多彩的网页。
CSS 干的活说起来也简单,比如说改个字号大小啊,加个背景颜色啊,加些网页特效啊,不过这些对于 Web Scraper 来说都不需要,因为 Web Scraper 是个爬虫工具,关注点是数据,而不是设计。
CSS 里用来装饰的特性我们是用不到的,但是 CSS 里的选择器我们还是用得到的。Web Scraper 里用来选择元素的 Selector,背后依赖的的技术就是 CSS 选择器。
CSS 选择器,官方定义了 50 多种,但是经过我的实践总结,Web Scraper 用的最多的只有 6 种,掌握这 6 种选择器,就可以解决 99% 的选择问题。
为了学习方便,我这里创建了一个简单的网页,专门用于 CSS 选择器的教学。
网页结构非常简单,用几个标签描述了一个五口之家:父亲、母亲、姐姐、哥哥和弟弟,还有一把玩具枪。我们就通过这个网页来学习 CSS 选择器。
1.标签选择器
在这个家庭里,如果我想把所有的家庭成员选中,观察网页结构,你会发现五个人都被 <p> 标签包住了,所以我们直接在 Selector 中输入字符 p,就可以选择所有的家庭成员:
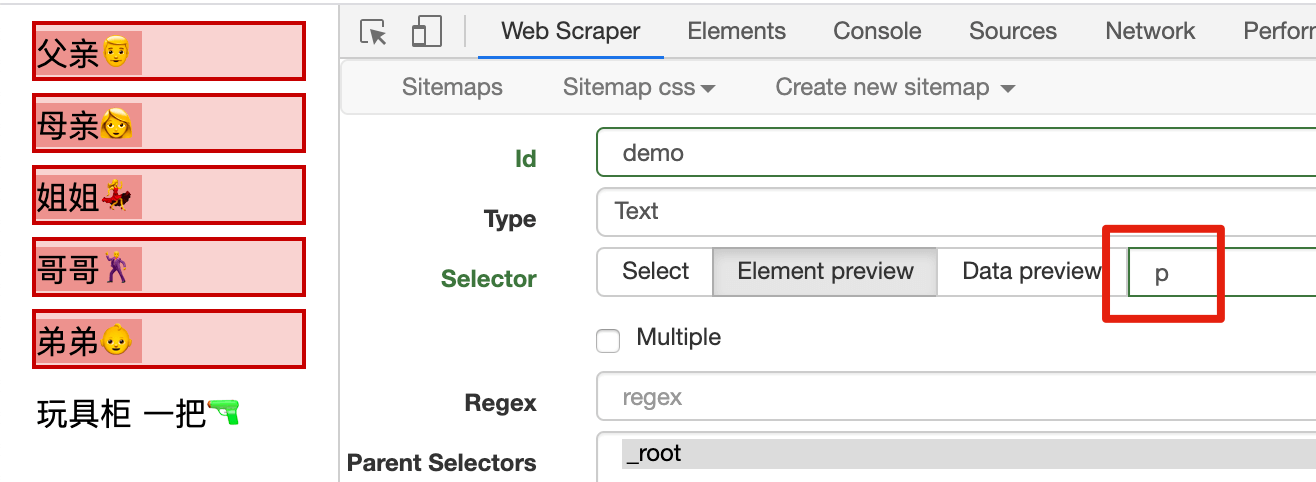
同理,如果我们要选择玩具枪,发现它被 <span> 标签包裹着,我们输入 span,就能选择玩具枪:
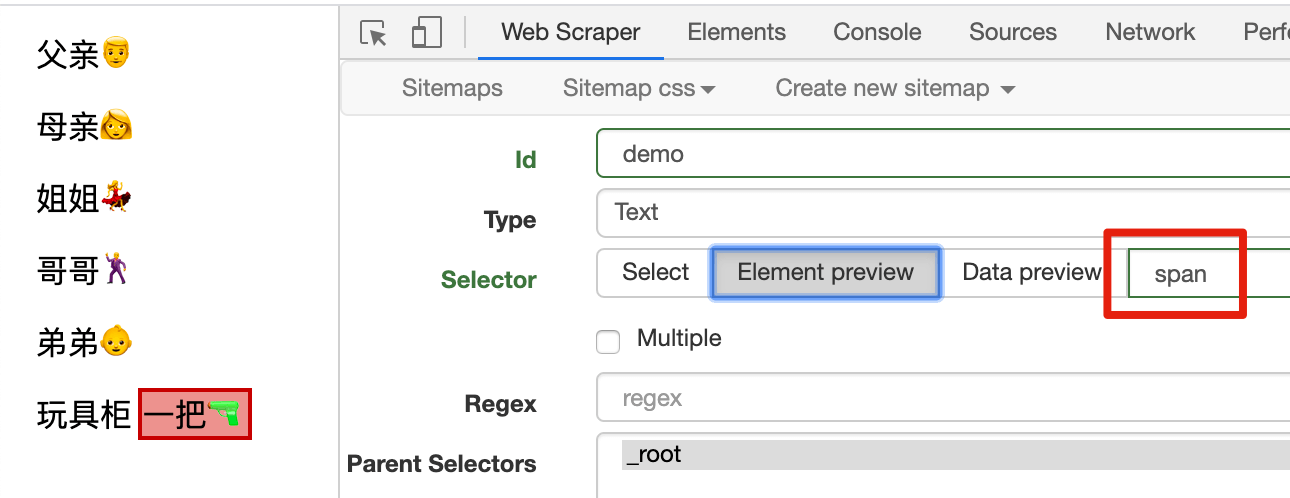
2.class 选择器
我们想选择父母怎么办?观察发现,父母的 <p> 标签上,有着 class="parent" 这个属性,我们可以利用 CSS 的 class 选择器,所以我们输入 .parent(注意: parent 前面有个小数点「.」),表示选中所有的有着 class="parent" 属性的标签,在这个例子里就可以选中父母:
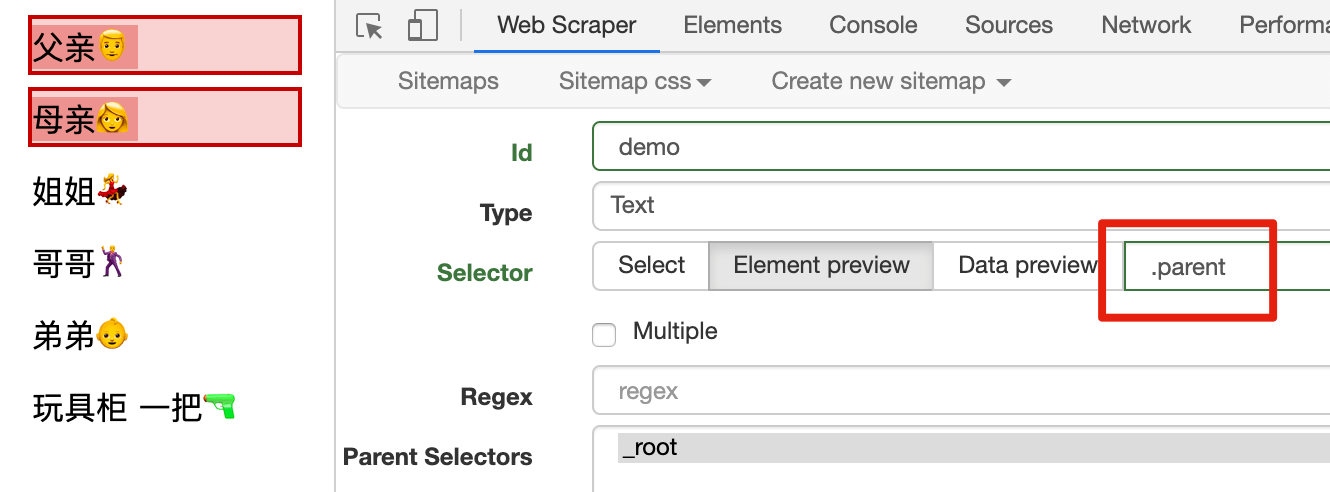
当然,你也可以输入 p.parent,表示选中所有的有着 class="parent" 属性的 <p> 标签,一样可以选中父母。
3.id 选择器
如果你想选中玩具枪,除了前面直接输入 span,我们观察可以发现,span 上还有一个 id="toy" 属性。我们可以利用 CSS 选择器里的 id 选择器,可以输入 #toy(注意: toy 前面有个井号「#」),选中玩具枪:
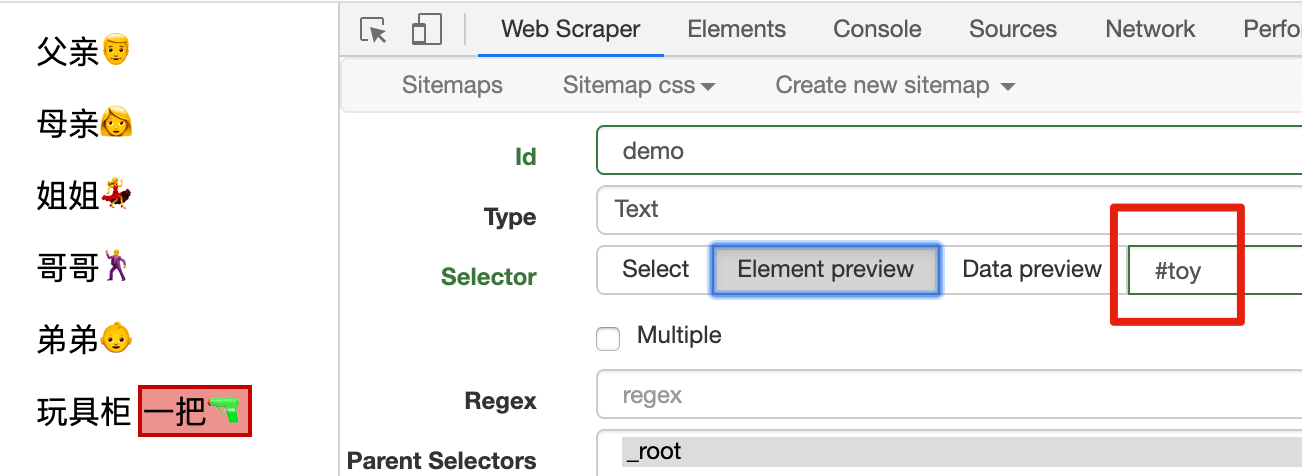
4.属性选择器
HTML 是一个非常自由的文档,除了官方提供的一些属性,例如 class 和 id,我们还可以加一些自定义的属性。
比如说姐姐和哥哥,两个人都在跳舞,观察法相两个人的 <p> 标签上都加入了 dance 属性,所以我们可以通过输入 p[dance],通过属性选择这两个人:
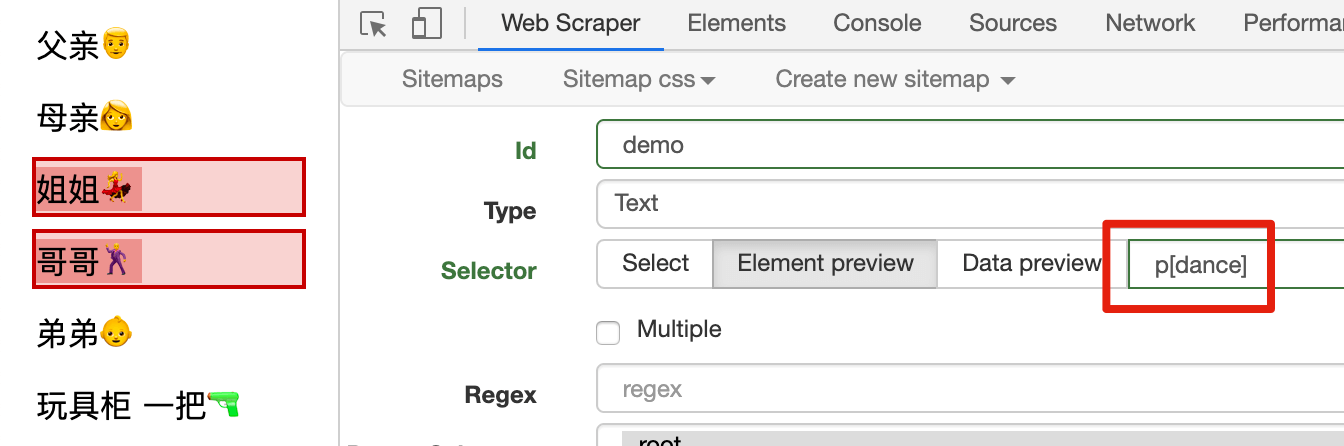
其实前面的 class 选择器和 id 选择器,还可以写成 p[class=parent],span[id=toy],道理都是一样的。
5.后代元素选择器
HTML 是一个可以互相嵌套的文档结构,我们可以先确定父元素的位置,然后再在父元素里定位子元素。
举一个简单的例子,在前面定位玩具枪时,我们可以通过 id 选择器定位,也可以通过 span 元素定位,如果我们想通过父元素来定位该怎么做呢?
这时候后代元素选择器就该出场了。我们先通过 div.family 选择父元素,然后通过 div.family span 选择玩具枪(注意:div.family 和 span 中间的空格不能丢):
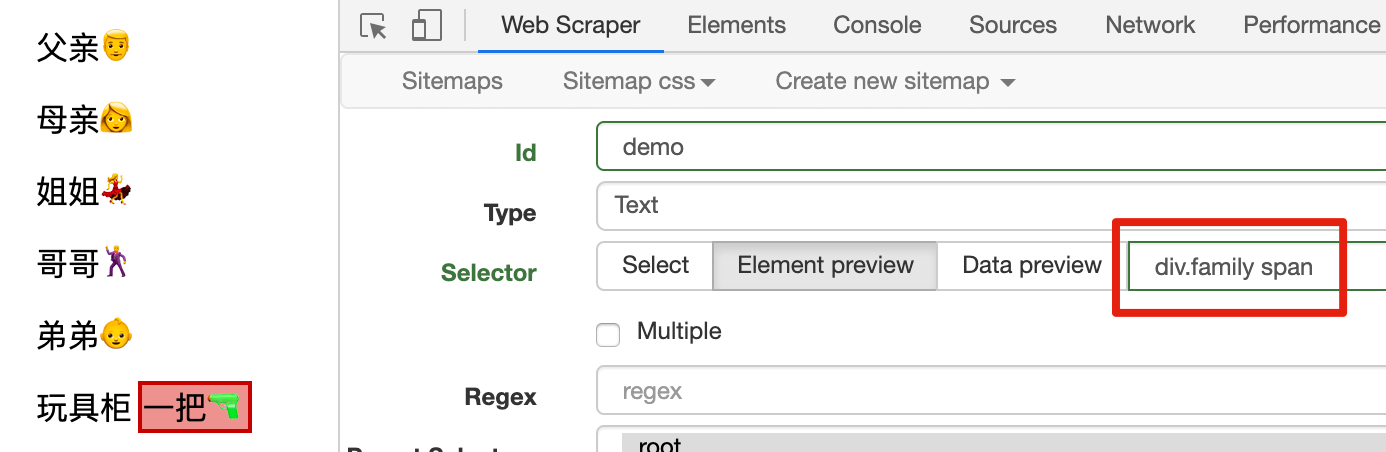
同理,div.family div span,div.family span#toy 都可以选中玩具枪。
6.直接指定子元素位置
:nth-of-type(n) 是一个非常有用的元素选择器,我们可以通过它直接指定元素。
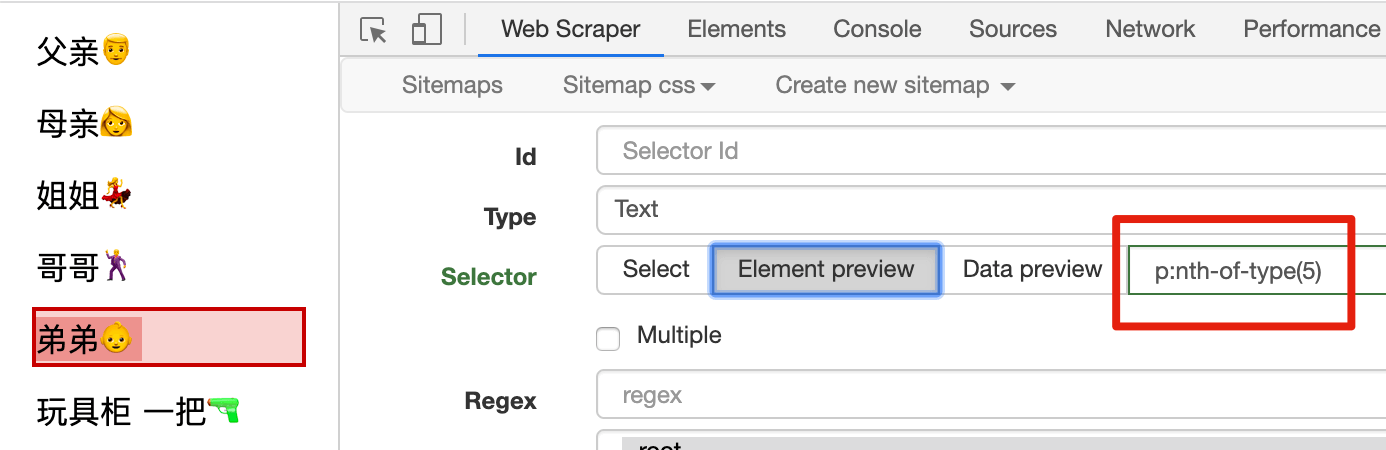
比如说我们想选择弟弟,你会发现之前介绍的 5 种方法,都没办法直接选中他。这时候用 :nth-of-type(n) 就非常的简单了:弟弟是所有 p 标签的第 5 个元素,所以用 p:nth-of-type(5) 就可以直接选中。
三、实战
上文的知识密度还是有些大的,熟练使用还是需要一些刻意练习。我们这次就用多种姿势选择豆瓣电影的评分。
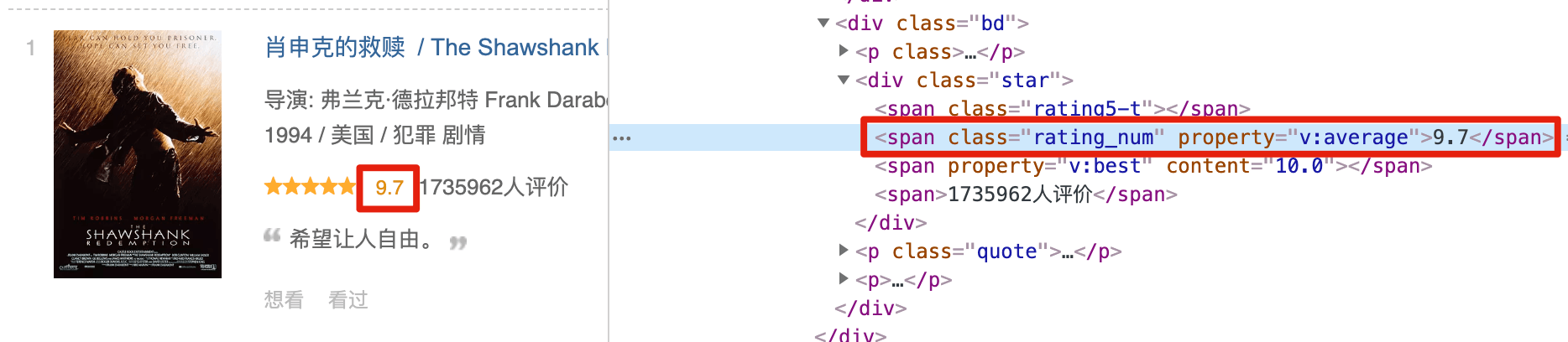
首先我们可以使用 class 选择器。输入 span.rating_num,选择评分:
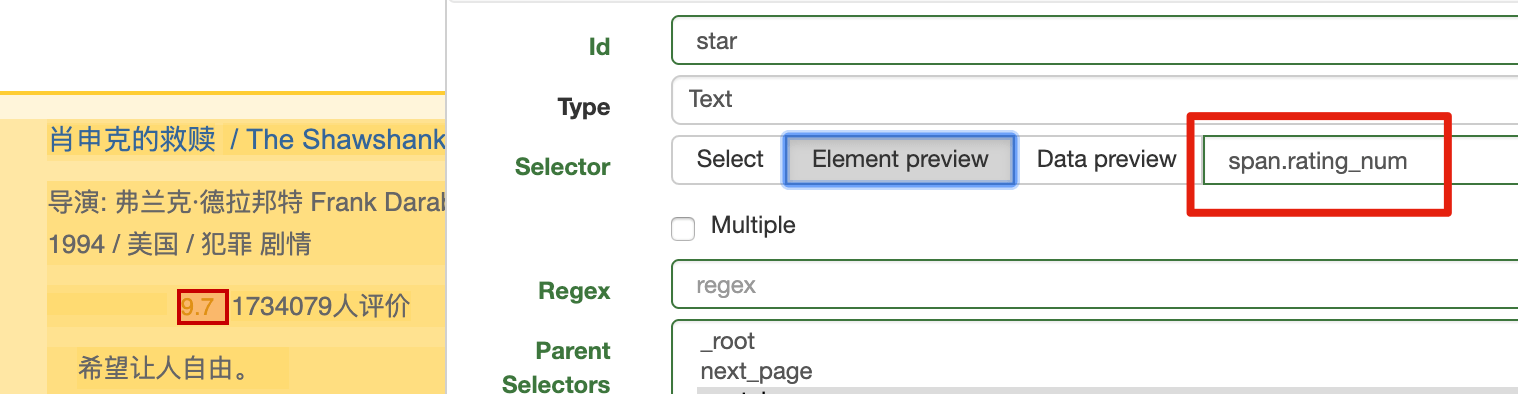
然后我们可以试试属性选择器,定位 property="v:average" 这个自定义属性。输入 span[property='v:average'],选择评分:

我们还可以利用后代元素选择器定位子元素,然后直接指定子元素位置。输入 div.star span:nth-of-type(2) ,选择评分:

这个只是一次小小的实战练习,如果要较好的掌握,还需要多加练习。有时间的话还可以去
https://www.runoob.com/cssref/css-selectors.html
这个网页看看本文没有介绍的其他 CSS 选择器,说不定就在项目中用到了。
四、推荐阅读
5.联系我
因为文章发在各大平台上,账号较多不能及时回复评论和私信,有问题可关注公众号 ——「卤代烃实验室」,关注上车防失联。

简易数据分析 15 | Web Scraper 高级用法——CSS 选择器的使用的更多相关文章
- Web Scraper 高级用法——抓取属性信息 | 简易数据分析 16
这是简易数据分析系列的第 16 篇文章. 这期课程我们讲一个用的较少的 Web Scraper 功能--抓取属性信息. 网页在展示信息的时候,除了我们看到的内容,其实还有很多隐藏的信息.我们拿豆瓣电影 ...
- Web Scraper 翻页——控制链接批量抓取数据(Web Scraper 高级用法)| 简易数据分析 05
这是简易数据分析系列的第 5 篇文章. 上篇文章我们爬取了豆瓣电影 TOP250 前 25 个电影的数据,今天我们就要在原来的 Web Scraper 配置上做一些小改动,让爬虫把 250 条电影数据 ...
- 简易数据分析 04 | Web Scraper 初尝--抓取豆瓣高分电影
这是简易数据分析系列的第 4 篇文章. 今天我们开始数据抓取的第一课,完成我们的第一个爬虫.因为是刚刚开始,操作我会讲的非常详细,可能会有些啰嗦,希望各位不要嫌弃啊:) 有人之前可能学过一些爬虫知识, ...
- 简易数据分析 07 | Web Scraper 抓取多条内容
这是简易数据分析系列的第 7 篇文章. 在第 4 篇文章里,我讲解了如何抓取单个网页里的单类信息: 在第 5 篇文章里,我讲解了如何抓取多个网页里的单类信息: 今天我们要讲的是,如何抓取多个网页里的多 ...
- 简易数据分析 08 | Web Scraper 翻页——点击「更多按钮」翻页
这是简易数据分析系列的第 8 篇文章. 我们在Web Scraper 翻页--控制链接批量抓取数据一文中,介绍了控制网页链接批量抓取数据的办法. 但是你在预览一些网站时,会发现随着网页的下拉,你需要点 ...
- 简易数据分析 09 | Web Scraper 自动控制抓取数量 & Web Scraper 父子选择器
这是简易数据分析系列的第 9 篇文章. 今天我们说说 Web Scraper 的一些小功能:自动控制 Web Scraper 抓取数量和 Web Scraper 的父子选择器. 如何只抓取前 100 ...
- 简易数据分析 10 | Web Scraper 翻页——抓取「滚动加载」类型网页
这是简易数据分析系列的第 10 篇文章. 友情提示:这一篇文章的内容较多,信息量比较大,希望大家学习的时候多看几遍. 我们在刷朋友圈刷微博的时候,总会强调一个『刷』字,因为看动态的时候,当把内容拉到屏 ...
- 简易数据分析 11 | Web Scraper 抓取表格数据
这是简易数据分析系列的第 11 篇文章. 今天我们讲讲如何抓取网页表格里的数据.首先我们分析一下,网页里的经典表格是怎么构成的. First Name 所在的行比较特殊,是一个表格的表头,表示信息分类 ...
- 简易数据分析 12 | Web Scraper 翻页——抓取分页器翻页的网页
这是简易数据分析系列的第 12 篇文章. 前面几篇文章我们介绍了 Web Scraper 应对各种翻页的解决方法,比如说修改网页链接加载数据.点击"更多按钮"加载数据和下拉自动加载 ...
随机推荐
- HZOJ Silhouette
转化一下题意:给出矩阵每行每列的最大值,求满足条件的矩阵个数. 先将A,B按从大到小排序,显然没有什么影响.如果A的最大值不等于B的最大值那么无解否则一定有解. 考虑从大到小枚举A,B中出现的数s,那 ...
- Nuxt.js打造旅游网站第2篇_首页开发
页面效果: 1.初始化默认布局 nuxtjs提供了一个公共布局组件layouts/default.vue,该布局组件默认作用于所有页面,所以我们可以在这里加上一些公共样式,在下一小结中还会导入公共组件 ...
- oracle函数 SUM([distinct|all]x)
[功能]统计数据表选中行x列的合计值. [参数]all表示对所有的值求合计值,distinct只对不同的值求合计值,默认为all 如果有参数distinct或all,需有空格与x(列)隔开. [参数] ...
- 05Dockerfile简介
Dockerfile是一个用于构建Docker镜像的文本文件,其中包含了创建Docker镜像的全部指令.基于这些指令,可以使用"docker build"命令来创建镜像. 一:用 ...
- Python基础:03序列:字符串、列表和元组
一:序列 1:连接操作符(+) 这个操作符允许把一个序列和另一个相同类型的序列做连接,生成新的序列.语法如下:sequence1 + sequence2 该表达式的结果是一个包含sequence1和s ...
- Flask学习之十三 日期和时间
英文博客地址:http://blog.miguelgrinberg.com/post/the-flask-mega-tutorial-part-xiii-dates-and-times 中文翻译地址: ...
- 模板—LCT
#include<iostream> #include<cstring> #include<cstdio> #define LL long long using n ...
- behavior planning——inputs to transition functions
the answer is that we have to pass all of the data into transition function except for the previous ...
- 上传图片保存到MySql数据库并显示--经验证有效
以下方法仅供参考,只是介绍下这一种方法而已.欢迎指正!! 前台(image.html): 1<html> 2<head> 3<title>上传图片</tit ...
- LRJ 3-7
#define _CRT_SECURE_NO_WARNINGS #include <cstdio> int main() { int T; int m, n; ][]; // 4 < ...