ELK6.3版本安装部署
一、Elasticsearch 安装
1、部署系统以及环境准备
cat /etc/redhat-release
CentOS Linux release 7.4.1708 (Core)
uname -r
3.10.0-693.el7.x86_64 #Firewalld and selinux
systemctl stop firewalld
systemctl disable firewalld
sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
setenforce 0 sed -i 's/localhost.localdomain/ELK.localdomain/' /etc/hostname
hostnamectl set-hostname ELK.localdomain 安装jdk8以上版本
mkdir /application/
tar xf jdk-8u151-linux-x64.tar.gz -C /application/
ln -s /application/jdk1.8.0_151 /application/jdk
sed -i.ori '$a export JAVA_HOME=/application/jdk\nexport PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH\nexport CLASSPATH=.$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib:$JAVA_HOME/lib/tools.jar' /etc/profile
source /etc/profile java -version
java version "1.8.0_151"
Java(TM) SE Runtime Environment (build 1.8.0_151-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.151-b12, mixed mode) 2、部署elasticsearch6.3.2
采用压缩包解压缩安装方式启动服务
创建另外独立账户专供es使用
cd /usr/local
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.3.2.tar.gz
tar zxvf elasticsearch-6.3.2.tar.gz -C /application/
groupadd ela 创建ela组
useradd -g ela ela 创建ela用户,并且加入ela组
passwd ela 为ela用户设定登录密码 ln -s /application/elasticsearch-6.3.2/ /application/elasticsearch
chown -R ela.ela /application/elasticsearch 配置文件
grep -n '^[a-Z]' /application/elasticsearch/config/elasticsearch.yml
17:cluster.name: elk
23:node.name: node-1
33:path.data: /home/elkdata
37:path.logs: /var/log/elasticsearch
42:bootstrap.memory_lock: true
54:network.host: 0.0.0.0
58:http.port: 9200
88:http.cors.enabled: true
89:http.cors.allow-origin: "*" mkdir /home/elkdata/ -p
chown -R ela.ela /home/elkdata/
mkdir /var/log/elasticsearch -p
chown -R ela.ela /var/log/elasticsearch/ vim /etc/security/limits.conf #增加以下行
* soft nofile 65536
* hard nofile 131072
ela soft memlock unlimited
ela hard memlock unlimited 让设置生效重启系统或者另外开一个终端 vim /etc/sysctl.conf
#增加一行
vm.max_map_count = 655360
sysctl -p 检查文件权限是否是ela用户
ls -l /application/elasticsearch-6.3.2/
ls -l /application/elasticsearch/
ls -l /application/elasticsearch/config/jvm.options 切换到ela用户,-d后台运行
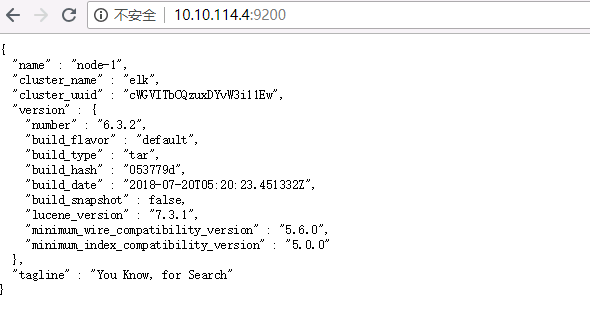
[ela@elk elasticsearch-6.3.2]$ ./bin/elasticsearch -d [ela@elk elasticsearch-6.3.2]$ netstat -ntpl|grep 9200
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
tcp6 0 0 :::9200 :::* LISTEN 147438/java
二、Kibana安装
#下载
cd /usr/local/src
wget https://artifacts.elastic.co/downloads/kibana/kibana-6.3.2-linux-x86_64.tar.gz
#解压
tar xzvf kibana-6.3.2-linux-x86_64.tar.gz ln -s /application/kibana-6.3.2-linux-x86_64 /application/kibana vim /application/kibana/config/kibana.yml
#端口
server.port: 5601 #服务器IP
server.host: "10.10.114.4" #elasticsearch服务器
elasticsearch.url: "http://10.10.114.4:9200" 启动
nohup bin/kibana & 查看端口占用命令
netstat -apn |grep 5601
#杀掉进程
kill -9 进程号
浏览器访问:http://ip:5601
kibana-6.3.0版本以后新增index索引不支持常用的正则匹配了,只能使用【*】

三、Logstash安装
另外一台10.10.114.2安装Logstash
mkdir /application/
tar xf jdk-8u151-linux-x64.tar.gz -C /application/
ln -s /application/jdk1.8.0_151 /application/jdk
sed -i.ori '$a export JAVA_HOME=/application/jdk\nexport PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH\nexport CLASSPATH=.$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib:$JAVA_HOME/lib/tools.jar' /etc/profile
source /etc/profile tar xf logstash-6.3.2.tar.gz -C /application/
ln -s /application/logstash-6.3.2 /application/logstash #收集IIS日志为例
cd /application/logstash/
mkdir conf && cd conf
cat IIS.conf
input {
beats {
port => ""
codec => json
}
} filter {
if [message] =~ "^#" { drop {} }
grok {
match =>{"message" => "%{TIMESTAMP_ISO8601:timestamp} %{IPORHOST:s_ip} %{WORD:request_method} %{NOTSPACE:uripath} %{NOTSPACE:uri-query} %{NUMBER:port} - %{IPORHOST:c_ip} %{NOTSPACE:agent} %{NOTSPACE:referer} %{NUMBER:status} %{NUMBER:sc_bytes} %{NUMBER:cs_bytes} %{NUMBER:time}" }
}
date {
match => ["timestamp","YYYY-MM-dd HH:mm:ss"]
}
mutate {
remove_field => ["message","beat","_id","host","@version","_score","tags"]
}
} output {
elasticsearch {
hosts => ["10.10.114.4:9200"]
index => "logstash-iis-%{+YYYY.MM.dd}"
} stdout {
codec => rubydebug
}
} 首先来测试配置文件是否可用,使用-f标志指定配置文件。 /application/logstash/bin/logstash -f conf/IIS.conf --config.test_and_exit --config.test_and_exit,会测试你配置文件的正确性,并给出错误信息. 如果可用,会输出 OK ,之后可以通过下面的命令来启动logstash /application/logstash/bin/logstash -f conf/IIS.conf & 查看端口
netstat -ntpl|grep 5044
客户端安装Filebeat
windows下直接解压缩后filebeat-6.3.2-windows-x86_64
修改filebeat.yml文件
filebeat.inputs: - type: log
encoding: GBK #编码格式
enabled: true paths:
- D:\ApplicationLogs\*\*\* #收集日志的路径 output.logstash:
hosts: ["10.10.114.2:5044"] #直接写到logstash
可以在cmd下测试执行、可以查看到传输的日志文件
/路径/filebeat.exe -c filebeat.yml -e
head插件安装
Elasticsearch6.x版本不能使用命令直接安装head插件
修改配置文件/etc/elasticsearch/elasticsearch.yml增加参数
# 增加参数,使head插件可以访问es
http.cors.enabled: true
http.cors.allow-origin: "*" 下载head插件
cd /usr/local/src
wget https://github.com/mobz/elasticsearch-head/archive/master.zip
unzip master.zip
mv elasticsearch-head-master/ /application/
安装node
wget https://npm.taobao.org/mirrors/node/latest-v4.x/node-v4.4.7-linux-x64.tar.gz
tar -zxvf node-v4.4.7-linux-x64.tar.gz
修改环境变量/etc/profile添加 export NODE_HOME=/application/node-v4.4.7-linux-x64
export PATH=$PATH:$NODE_HOME/bin
export NODE_PATH=$NODE_HOME/lib/node_modules
设置生效
source /etc/profile
安装grunt
cd /application/elasticsearch-head-master
npm install -g grunt-cli 检查是否安装成功
[root@elk elasticsearch]# grunt -version
grunt-cli v1.3.1
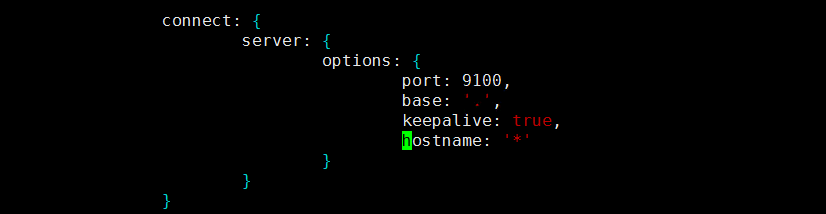
修改head插件源码/application/elasticsearch-head-master/Gruntfile.js
hostname是新增的,不要忘记原有的true后面加,符号
修改连接地址/application/elasticsearch-head-master/_site/app.js

下载运行head必要的文件(放置在文件夹/tmp下)
cd /tmp
wget https://github.com/Medium/phantomjs/releases/download/v2.1.1/phantomjs-2.1.1-linux-x86_64.tar.bz2
yum -y install bzip2
运行head
cd /application/elasticsearch-head-master
npm install
后台启动
grunt server &
web页面验证
可以查看到node1节点

最简单的做法就是直接在谷歌浏览器添加应用程序
ELK6.3版本安装部署的更多相关文章
- ELK7.11.2版本安装部署及ElastAlert告警相关配置
文档开篇,我还是要说一遍,虽然我在文档内容中也会说好多遍,但是希望大家不要嫌我墨迹: 请多看官方文档,请多看命令行报错信息,请多看日志信息,很多时候它们比百度.比必应.比谷歌有用: 请不要嫌麻烦,打开 ...
- OEMCC 13.2 集群版本安装部署
之前测试部署过OEMCC 13.2单机,具体可参考之前随笔: OEMCC 13.2 安装部署 当时环境:两台主机,系统RHEL 6.5,分别部署OMS和OMR: OMS,也就是OEMCC的服务端 IP ...
- Solr版本安装部署指南
一.依赖包 1. JDK 1.6以上 2. solr-4.3.0.tgz 3. Tomcat或者jetty(注意,solr包中本身就含有jetty的启动相关内容):apache-tomcat-7 ...
- SkyWorking基础:6.2版本安装部署
就在今天,SkyWorking发布了6.2版本. 概述 什么是SkyWorking SkyWalking是观察性分析平台和应用性能管理系统. 提供分布式追踪.服务网格遥测分析.度量聚合和可视化一体化解 ...
- Lepus监控之安装部署
PHP和Python都是跨平台的语言,所以理论上系统应该可以支持在不同的平台上运行.但是由于时间和精力以及资源有限,目前天兔系统只测试完善了Centos/RedHat系统的支持.我们目前提供的技术支持 ...
- 安装部署Apache Hadoop (本地模式和伪分布式)
本节内容: Hadoop版本 安装部署Hadoop 一.Hadoop版本 1. Hadoop版本种类 目前Hadoop发行版非常多,有华为发行版.Intel发行版.Cloudera发行版(CDH)等, ...
- Redis (一)Redis简介、安装部署
Redis是一个开源的,先进的 key-value 存储可用于构建高性能,可扩展的 Web 应用程序的解决方案. 既然是key-value,对于Java开发来说更熟悉的是Map集合.那就有问题了,有M ...
- 比Ansible更吊的自动化运维工具,自动化统一安装部署自动化部署udeploy 1.0 版本发布
新增功能: 逻辑与业务分离,完美实现逻辑与业务分离,业务实现统一shell脚本开发,由框架统一调用. 并发多线程部署,不管多少台服务器,多少个服务,同时发起线程进行更新.部署.启动. 提高list规则 ...
- Hive环境的安装部署(完美安装)(集群内或集群外都适用)(含卸载自带mysql安装指定版本)
Hive环境的安装部署(完美安装)(集群内或集群外都适用)(含卸载自带mysql安装指定版本) Hive 安装依赖 Hadoop 的集群,它是运行在 Hadoop 的基础上. 所以在安装 Hive 之 ...
随机推荐
- Javascript判断图片是否存在
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/stri ...
- A - 无聊的游戏 HDU - 1525(博弈)
A - 无聊的游戏 HDU - 1525 疫情当下,有两个很无聊的人,小A和小B,准备玩一个游戏,玩法是这样的,从两个自然数开始比赛.第一个玩家小A从两个数字中的较大者减去两个数字中较小者的任何正倍数 ...
- MFC 工具栏ToolBar
一.创建工具栏 1.在MFC工程,找到“资源视图”界面,右键添加资源,选择Toolbar,点击新建: 2.修改工具条属性: 3.添加工具: 新建ToolBar后,会自动生成一个工具,编辑ID后,工具条 ...
- DALI 48V驱动
DALI-CC-30W-48V技术手册 产品名称:DALI-CC-30W-48V 支持协议:IEC 62386-101:2018,IEC 62386-102:2018,IEC 62386-207:20 ...
- Scratch 怎么打开SB文件怎么打开
扩展名是.sb( )的文件均可以用匹配版本的scratch或比匹配版本高的scratch打开,列表如下:类型 可打开.sb ···1.4(1.3).sb2 ···2.0.sb3··· 3.0或3.0b ...
- Java第十三天,内部类
内部类 一.①成员内部类.②局部内部类(包含③匿名内部类) 1.内部类用外部类属性和方法的时候,可以随意进行访问. 2.外部类用内部类属性和方法的时候,需要通过内部类对象访问. 3.在编译成class ...
- Linux 文件管理篇(二 目录信息)
其它在线帮助文档 usr/share/doc root用户的相关信息 etc/passwd 用户密码 etc/shadow 所有用户群组 etc/group 返 ...
- 深入理解智能指针之shared_ptr(一)
本文基于C++标准库源码分析shared_ptr,旨在搞清楚shared_ptr是什么,线程安全性等,目标能够安全的使用智能指针. (一)shared_ptr是一个类. 首先可以确定的是shared_ ...
- pgsql中json格式数组查询结果变成了字符串
场景复原 最近使用到了json的数组,用来存储多个文件的值,发现在连表查询的时候返回结果变成了字符串. { "id": "repl-placeholder-007&quo ...
- CSS两种盒子模型:cntent-box和border-box
cntent-box 平时普通盒子模型,padding,border盒子会变大,向外扩展border-box 特殊盒子模型,padding,border盒子会变大,向内扩展