sklearn KMeans聚类算法(总结)
基本原理
Kmeans是无监督学习的代表,没有所谓的Y。主要目的是分类,分类的依据就是样本之间的距离。比如要分为K类。步骤是:
- 随机选取K个点。
- 计算每个点到K个质心的距离,分成K个簇。
- 计算K个簇样本的平均值作新的质心
- 循环2、3
- 位置不变,距离完成
距离
Kmeans的基本原理是计算距离。一般有三种距离可选:
- 欧氏距离
\[d(x,u)=\sqrt{\sum_{i=1}^n(x_i-\mu_i)^2}
\] - 曼哈顿距离
\[d(x,u)=\sum_{i=1}^n(|x_i-\mu|)
\] - 余弦距离
\[cos\theta=\frac{\sum_{i=1}^n(x_i*\mu)}{\sqrt{\sum_i^n(x_i)^2}*\sqrt{\sum_1^n(\mu)^2}}
\]
inertia
每个簇内到其质心的距离相加,叫inertia。各个簇的inertia相加的和越小,即簇内越相似。(但是k越大inertia越小,追求k越大对应用无益处)
代码
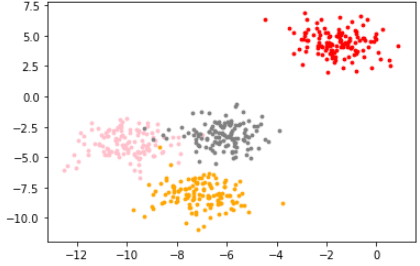
模拟数据:
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
X, y = make_blobs(n_samples=500, # 500个样本
n_features=2, # 每个样本2个特征
centers=4, # 4个中心
random_state=1 #控制随机性
)
画出图像:
color = ['red', 'pink','orange','gray']
fig, axi1=plt.subplots(1)
for i in range(4):
axi1.scatter(X[y==i, 0], X[y==i,1],
marker='o',
s=8,
c=color[i]
)
plt.show()
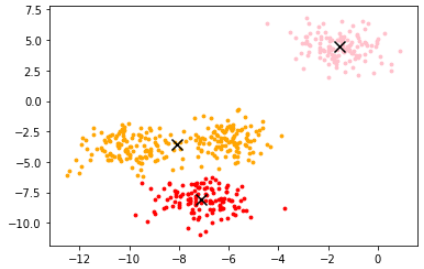
使用KMeans类建模:
from sklearn.cluster import KMeans
n_clusters=3
cluster = KMeans(n_clusters=n_clusters,random_state=0).fit(X)
也可先用fit, 再用predict,但是可能数据不准确。用于数据量较大时。
此时就可以查看其属性了:质心、inertia.
centroid=cluster.cluster_centers_
centroid # 查看质心
查看inertia:
inertia=cluster.inertia_
inertia
画出所在位置。
color=['red','pink','orange','gray']
fig, axi1=plt.subplots(1)
for i in range(n_clusters):
axi1.scatter(X[y_pred==i, 0], X[y_pred==i, 1],
marker='o',
s=8,
c=color[i])
axi1.scatter(centroid[:,0],centroid[:,1],marker='x',s=100,c='black')
sklearn KMeans聚类算法(总结)的更多相关文章
- 转载: scikit-learn学习之K-means聚类算法与 Mini Batch K-Means算法
版权声明:<—— 本文为作者呕心沥血打造,若要转载,请注明出处@http://blog.csdn.net/gamer_gyt <—— 目录(?)[+] ================== ...
- 一步步教你轻松学K-means聚类算法
一步步教你轻松学K-means聚类算法(白宁超 2018年9月13日09:10:33) 导读:k-均值算法(英文:k-means clustering),属于比较常用的算法之一,文本首先介绍聚类的理 ...
- 《数据挖掘导论》实验课——实验七、数据挖掘之K-means聚类算法
实验七.数据挖掘之K-means聚类算法 一.实验目的 1. 理解K-means聚类算法的基本原理 2. 学会用python实现K-means算法 二.实验工具 1. Anaconda 2. skle ...
- K-Means 聚类算法
K-Means 概念定义: K-Means 是一种基于距离的排他的聚类划分方法. 上面的 K-Means 描述中包含了几个概念: 聚类(Clustering):K-Means 是一种聚类分析(Clus ...
- k-means聚类算法python实现
K-means聚类算法 算法优缺点: 优点:容易实现缺点:可能收敛到局部最小值,在大规模数据集上收敛较慢使用数据类型:数值型数据 算法思想 k-means算法实际上就是通过计算不同样本间的距离来判断他 ...
- K-Means 聚类算法原理分析与代码实现
前言 在前面的文章中,涉及到的机器学习算法均为监督学习算法. 所谓监督学习,就是有训练过程的学习.再确切点,就是有 "分类标签集" 的学习. 现在开始,将进入到非监督学习领域.从经 ...
- Kmeans聚类算法原理与实现
Kmeans聚类算法 1 Kmeans聚类算法的基本原理 K-means算法是最为经典的基于划分的聚类方法,是十大经典数据挖掘算法之一.K-means算法的基本思想是:以空间中k个点为中心进行聚类,对 ...
- 机器学习六--K-means聚类算法
机器学习六--K-means聚类算法 想想常见的分类算法有决策树.Logistic回归.SVM.贝叶斯等.分类作为一种监督学习方法,要求必须事先明确知道各个类别的信息,并且断言所有待分类项都有一个类别 ...
- 沙湖王 | 用Scipy实现K-means聚类算法
沙湖王 | 用Scipy实现K-means聚类算法 用Scipy实现K-means聚类算法
随机推荐
- RabbitMQ消息队列帮助类
调用 //消息队列发消息 MqConfigInfo config = new MqConfigInfo(); config.MQExChange = "DrawingOutput" ...
- 吴裕雄--天生自然C++语言学习笔记:C++ 动态内存
栈:在函数内部声明的所有变量都将占用栈内存. 堆:这是程序中未使用的内存,在程序运行时可用于动态分配内存. 可以使用特殊的运算符为给定类型的变量在运行时分配堆内的内存,这会返回所分配的空间地址.这种运 ...
- vue学习(十二)vue全家桶 Vue-router&Vuex
一 vue-router的安装 二 vue-router的基本使用 三 命名路由 四 动态路由的匹配和路由组件的复用 一 vue-router的安装 NPM npm install vue-route ...
- python--txt文件处理
1.打开文件的模式主要有,r.w.a.r+.w+.a+ file = open('test.txt',mode='w',encoding='utf-8') file.write('hello,worl ...
- eclipse导入maven工程,右键没有build path和工程不能自动编译解决方法
原文链接:https://blog.csdn.net/wusunshine/article/details/52506389 eclipse导入maven工程,右键没有build path解决方法: ...
- spring boot 环境配置(profile)切换
Spring Boot 集成教程 Spring Boot 介绍 Spring Boot 开发环境搭建(Eclipse) Spring Boot Hello World (restful接口)例子 sp ...
- Tomcat解压版Windows配置(运行环境非开发环境)
tomcat官网下载的9.0.19,解压后目录如下: java官网下载的jre8 (8u131),目录如下(应该是下载的解压版): 打开tomcat9.0.19根目录下的RUNNING.txt,里面有 ...
- promise 核心 几个小问题
1.如何改变pending的壮体 抛出异常.pending变为rejected // throw new Error('fail') 内部抛出异常也这样 reason为抛出的error resol ...
- VUE中的MVVM模式
1.传统MVP模式:业务逻辑相关的控制层 M:模型层,ajax请求 V:dom层,视图 P:控制器.js代码之类的 2.MVVM MVVM模式主要操作数据层,代码减少量是MVP的30%甚至70%
- Ubuntu16.04上安装cudnn教程和opencv
https://blog.csdn.net/wang15061955806/article/details/80791112 Ubuntu16.04上安装cudnn教程 2018年06月24日 14: ...