Python数据科学手册-机器学习:朴素贝叶斯分类
朴素贝叶斯模型
朴素贝叶斯模型是一组非常简单快速的分类方法,通常适用于维度非常高的数据集。因为运行速度快,可调参数少。是一个快速粗糙的分类基本方案。
naive Bayes classifiers
贝叶斯分类
朴素贝叶斯分类器建立在贝叶斯分类方法的基础上。数学基础是贝叶斯定理。 一个描述统计量条件概率关系的公式。
在贝叶斯分类中,我们希望确定一个具有某些特征的样本 属于 某类标签的概率。 通常记为 P(L|特征)
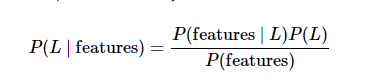
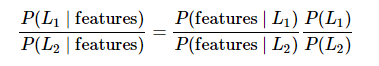
需要确定俩种标签,定义为L1和L2. 计算俩个标签的后验概率的比值
现在需要一种模型。帮我们计算每个标签的P(特征|Li).这种模型被称为生成模型。
因为它可以训练处生成输入数据的假设随机过程(概率分布)
为每中标签设置生成模型 是贝叶斯分类器训练过程的主要部分。
之所以称为朴素 。是因为 如果对每种标签的生成模型进行非常简单的假设,就能找到每种类型 生成模型的近似解,然后就可以使用贝叶斯分类。
不同类型的朴素贝叶斯分类器是有对数据的不同假设决定的。
高斯朴素贝叶斯
Gaussian naive Bayes 。 假设每个标签的数据都服从简单的高斯分布。
原始数据如下:
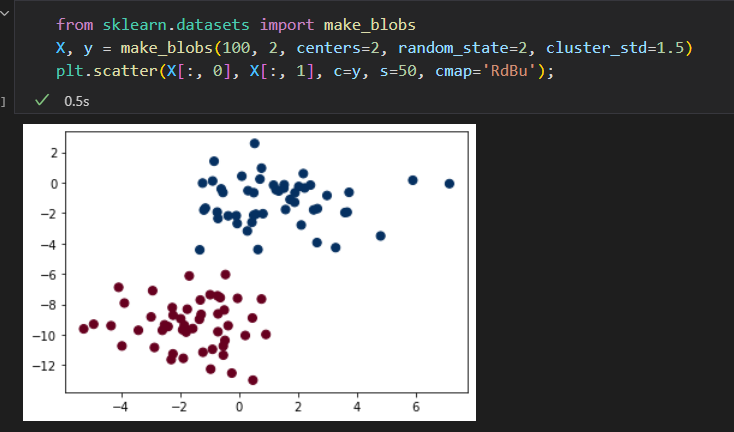
假设数据服从高斯分布,且变量无协方差 (线性无关)
只需要找出每个标签的所有样本点均值 和 标准差。再定义一个高斯分布。就可以拟合模型了。
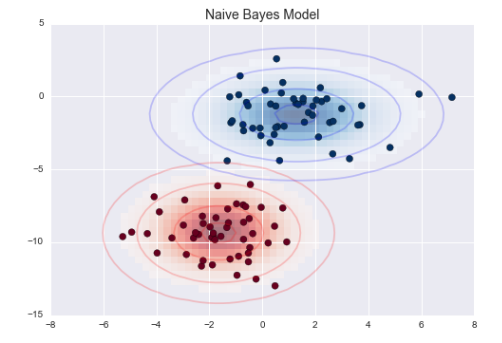
每个椭圆曲线表示每个标签的高斯生成模型。 越靠近椭圆中心的可能性越大。
通过每种类型的生成模型,可以计算出任意数据点的似然估计 P (特征|L1) 。
然后根据贝叶斯定理计算出 后验概率比值, 从而确定每个数据点可能性最大的标签。
评估器 GaussianNB实现:
预测标签:
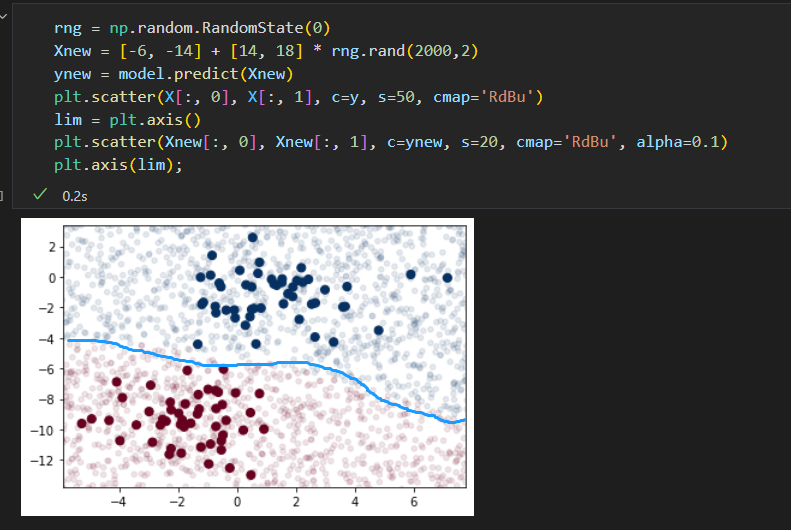
可以在分类结果中看到一条稍显 弯曲 的边界
通常:高斯朴素贝叶斯的边界 是二次方曲线。
多项式朴素贝叶斯
假设特征是由一个简单多项式分布 生成的。 多项分布式可以描述 各种类型样本 出现次数的概率。
- 文本分类
特征:分类文本的单词出现次数。
执行了15分钟。。。淦。
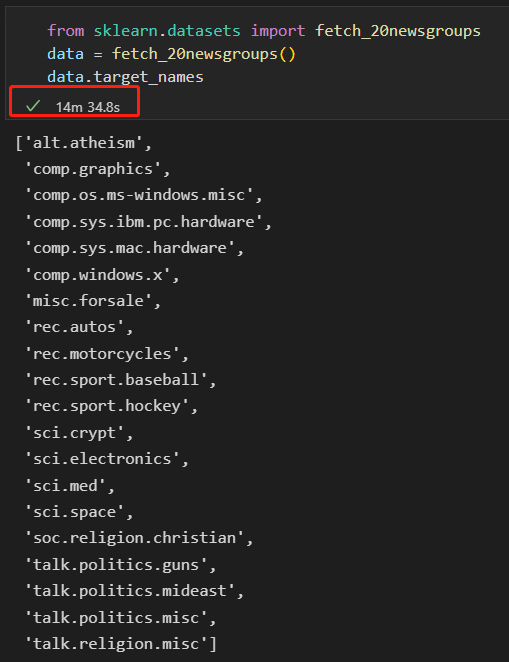
选择四类新闻,下载训练集和测试集
看其中一篇新闻:

为了让这些数据能用于机器学习,需要将每个字符串的内容转换成数值向量。
将模型应用到训练数据上。
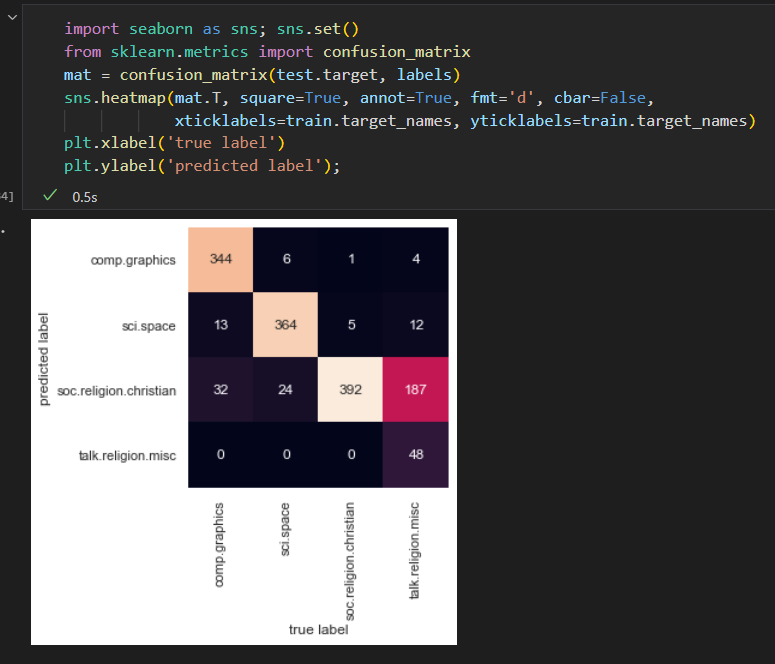
用混淆矩阵 统计 结果。
Python数据科学手册-机器学习:朴素贝叶斯分类的更多相关文章
- Python数据科学手册-机器学习介绍
机器学习分为俩类: 有监督学习 supervised learning 和 无监督学习 unsupervised learning 有监督学习: 对数据的若干特征与若干标签之间 的关联性 进行建模的过 ...
- Python数据科学手册-机器学习:线性回归
朴素贝叶斯是解决分类任务的好起点,线性回归是解决回归任务的好起点. 简单线性回归 将数据拟合成一条直线. y = ax + b , a 是斜率, b是直线截距 原始数据如下: 使用LinearRegr ...
- Python数据科学手册-机器学习: k-means聚类/高斯混合模型
前面学习的无监督学习模型:降维 另一种无监督学习模型:聚类算法. 聚类算法直接冲数据的内在性质中学习最优的划分结果或者确定离散标签类型. 最简单最容易理解的聚类算法可能是 k-means聚类算法了. ...
- Python数据科学手册-机器学习: 流形学习
PCA对非线性的数据集处理效果不太好. 另一种方法 流形学习 manifold learning 是一种无监督评估器,试图将一个低维度流形嵌入到一个高纬度 空间来描述数据集 . 类似 一张纸 (二维) ...
- Python数据科学手册-机器学习: 主成分分析
PCA principal component analysis 主成分分析是一个快速灵活的数据降维无监督方法, 可视化一个包含200个数据点的二维数据集 x 和 y有线性关系,无监督学习希望探索x值 ...
- Python数据科学手册-机器学习: 决策树与随机森林
无参数 算法 随机森林 随机森林是一种集成方法,集成多个比较简单的评估器形成累计效果. 导入标准程序库 随机森林的诱因: 决策树 随机森林是建立在决策树 基础上 的集成学习器 建一颗决策树 二叉决策树 ...
- Python数据科学手册-机器学习: 支持向量机
support vector machine SVM 是非常强大. 灵活的有监督学习算法, 可以用于分类和回归. 贝叶斯分类器,对每个类进行了随机分布的假设,用生成的模型估计 新数据点 的标签.是属于 ...
- Python数据科学手册-机器学习之特征工程
特征工程常见示例: 分类数据.文本.图像. 还有提高模型复杂度的 衍生特征 和 处理 缺失数据的填充 方法.这个过程被叫做向量化.把任意格式的数据 转换成具有良好特性的向量形式. 分类特征 比如房屋数 ...
- Python数据科学手册-机器学习之模型验证
模型验证 model validation 就是在选择 模型 和 超参数 之后.通过对训练数据进行学习.对比模型对 已知 数据的预测值和实际值 的差异. 错误的模型验证方法. 用同一套数据训练 和 评 ...
随机推荐
- 【FAQ】华为帐号服务报错 907135701的常见原因总结和解决方法
很多开发者在接入华为帐号服务时,经常会出现907135701的报错.根据官网文档说明,错误码907135701表示: 这个错误码在安卓和鸿蒙上都会出现,导致该报错的原因有很多,开发者可以按照下面几点进 ...
- JDBCToolsV3 :DAO
编写文件和步骤 ①,bean模块:数据类Course,包含数据的class,封装数据类型; ②,DAO:1)定义对数据的操作接口,及规定标准(包含怎样的操作).例如:CourseDAO数据库操作的接口 ...
- llinux的mysql数据库完全卸载
https://blog.csdn.net/qq_41829904/article/details/92966943https://www.cnblogs.com/javahr/p/9245443.h ...
- springboot动态读取properties 和yml的配置
properties使用PropertiesLoaderUtils,yml使用YamlPropertySourceLoader application.properties microsoft.def ...
- TMS320F280049 ADC 模块学习
1. 功能概述 2. 总体框图 block diagram 3. 可配置内容灵活分配到各个模块 或 某次转换中 4. 时钟配置 ADC 模块直接分频于系统最高时钟 5. SOC 机制 6. 如 ...
- 管正雄:基于预训练模型、智能运维的QA生成算法落地
分享嘉宾:管正雄 阿里云 高级算法工程师 出品平台:DataFunTalk 导读:面对海量的用户问题,有限的支持人员该如何高效服务好用户?智能QA生成模型给业务带来的提效以及如何高效地构建算法服务,为 ...
- 【ASP.NET Core】选项模式的相关接口
在 .NET 中,配置与选项模式其实有联系的(这些功能现在不仅限于 ASP.NET Core,而是作为平台扩展来提供,在其他.NET 项目中都能用).配置一般从多个来源(上一篇水文中的例子,记得否?) ...
- 如何用WebGPU流畅渲染百万级2D物体?
大家好~本文使用WebGPU和光线追踪算法,从0开始实现和逐步优化Demo,展示了从渲染500个2D物体都吃力到流畅渲染4百万个2D物体的优化过程和思路 目录 需求 成果 1.选择渲染的算法 2.实现 ...
- C#基础语法之-泛型
泛型:一共7个知识点 1.引入泛型,延迟声明 2.如何声明和使用泛型 3.泛型的好处和原理 4.泛型类,泛型方法,泛型接口,泛型委托 5.泛型约束 6.协变,逆变 7.泛型缓存 一.为啥会出现泛型,有 ...
- YII http缓存
http禁止缓存原理 header('Expires: 0'); header('Last-Modified: '. gmdate('D, d M Y H:i:s') . ' GMT'); heade ...