gerapy的初步使用(管理分布式爬虫)
一.简介与安装
Gerapy 是一款分布式爬虫管理框架,支持 Python 3,基于 Scrapy、Scrapyd、Scrapyd-Client、Scrapy-Redis、Scrapyd-API、Scrapy-Splash、Jinjia2、Django、Vue.js 开发。
特点:
更方便地控制爬虫运行 更直观地查看爬虫状态 更实时地查看爬取结果 更简单地实现项目部署 更统一地实现主机管理 更轻松地编写爬虫代码(几乎没用,感觉比较鸡肋)
安装:
pip install gerapy #gerapy 判断是否安装成功
F:\gerapy>gerapy
Usage:
gerapy init [--folder=<folder>]
gerapy migrate
gerapy createsuperuser
gerapy runserver [<host:port>]
二.使用
1.初始化项目
gerapy init #执行完毕之后,便会在当前目录下生成一个名字为 gerapy 的文件夹,接着进入该文件夹,可以看到有一个 projects 文件夹 #或者
gerapy init 指定的绝对目录 #这样会在指定的文件夹生成一个gerapy文件夹
2.初始化数据库
进入新生成的gerapy文件夹
cd 到gerapy目录
cd gerapy
gerapy migrate
3.运行gerapy服务
gerapy runserver
这要命令必须新生成的gerapy文件夹只用,否则以前创建的项目都看不奥到
4.访问gerapy界面
http://127.0.0.1:8000
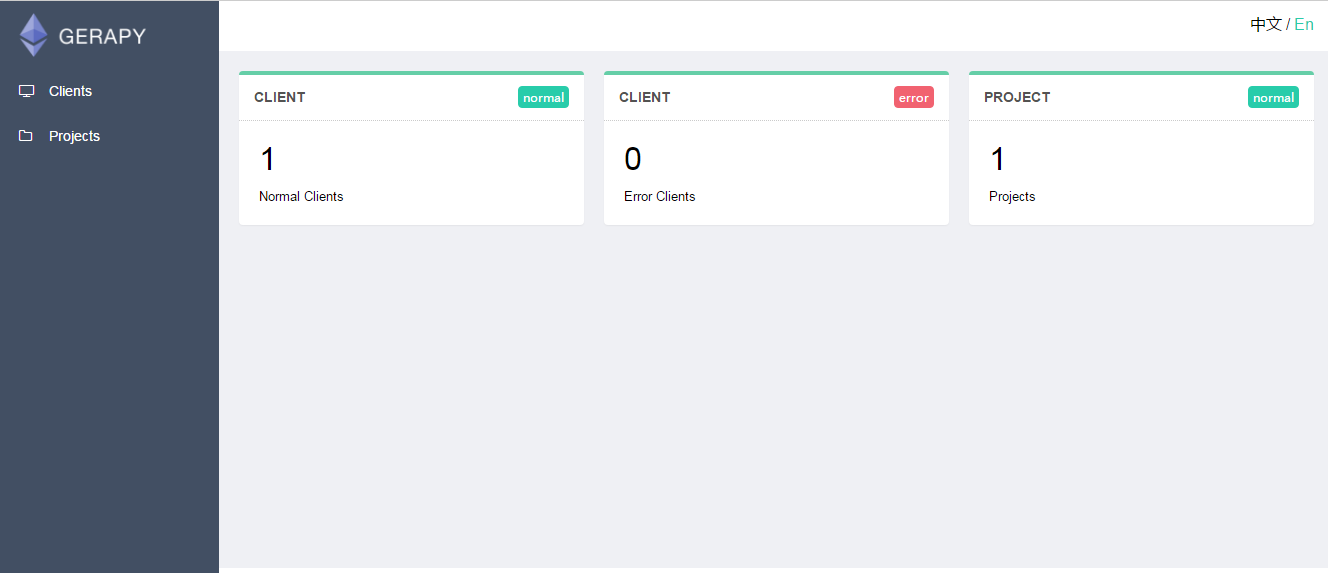
三.gerapy管理界面的使用
1.部署主机
就是配置我们scrapyd 远程服务.(指定远程服务器的ip和端口等等)
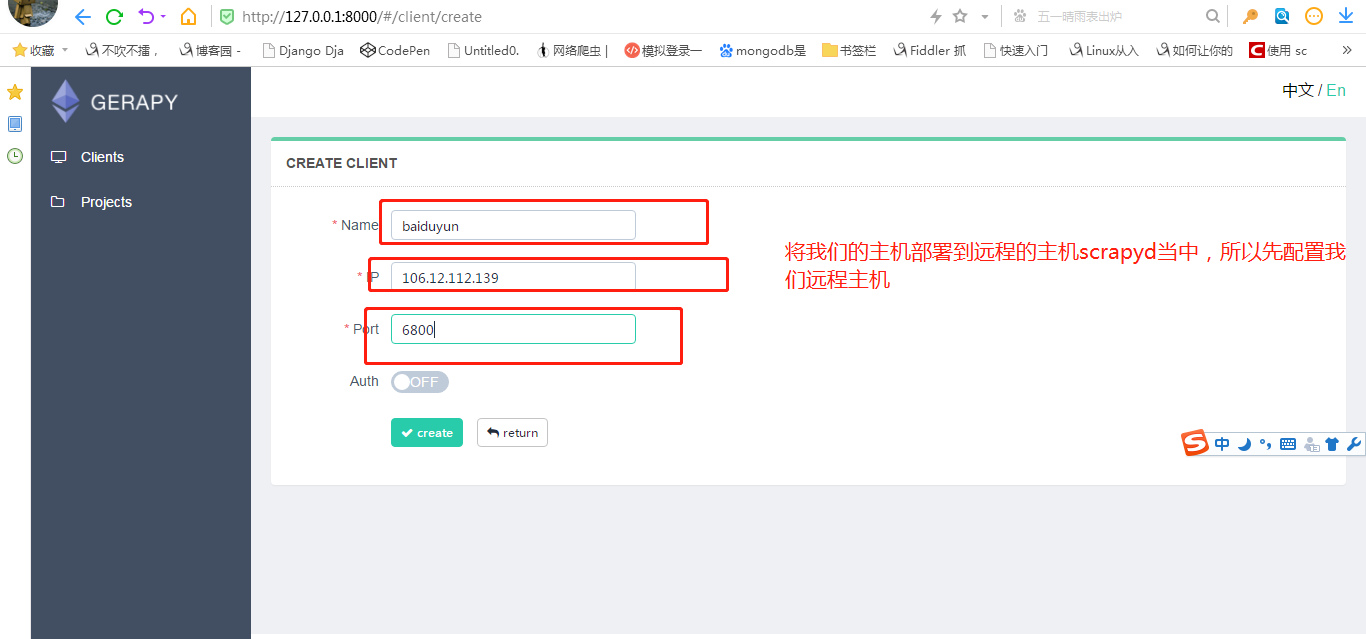
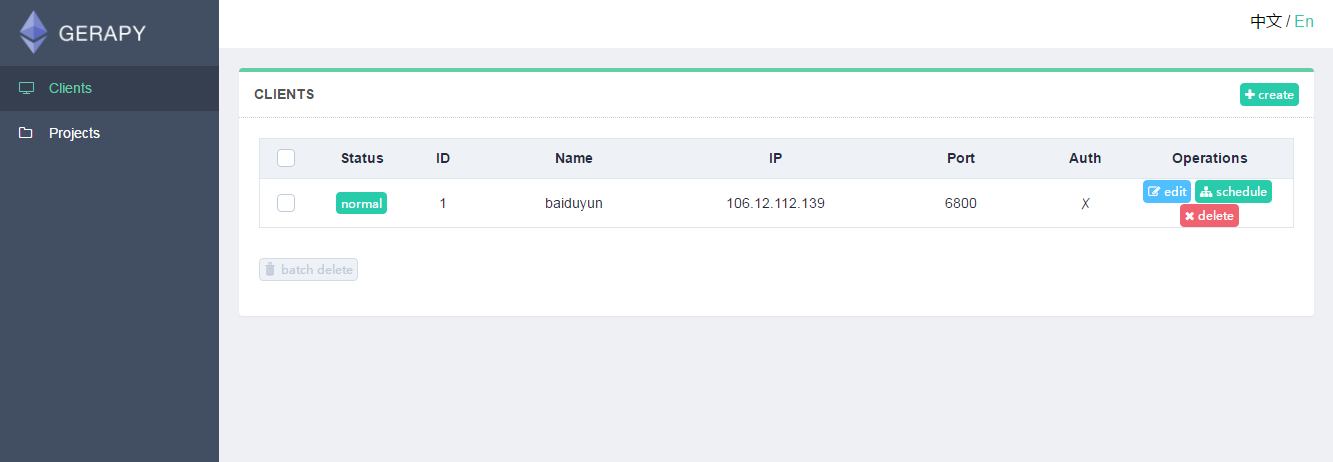
需要添加 IP、端口,以及名称,点击创建即可完成添加,点击返回即可看到当前添加的 Scrapyd 服务列表
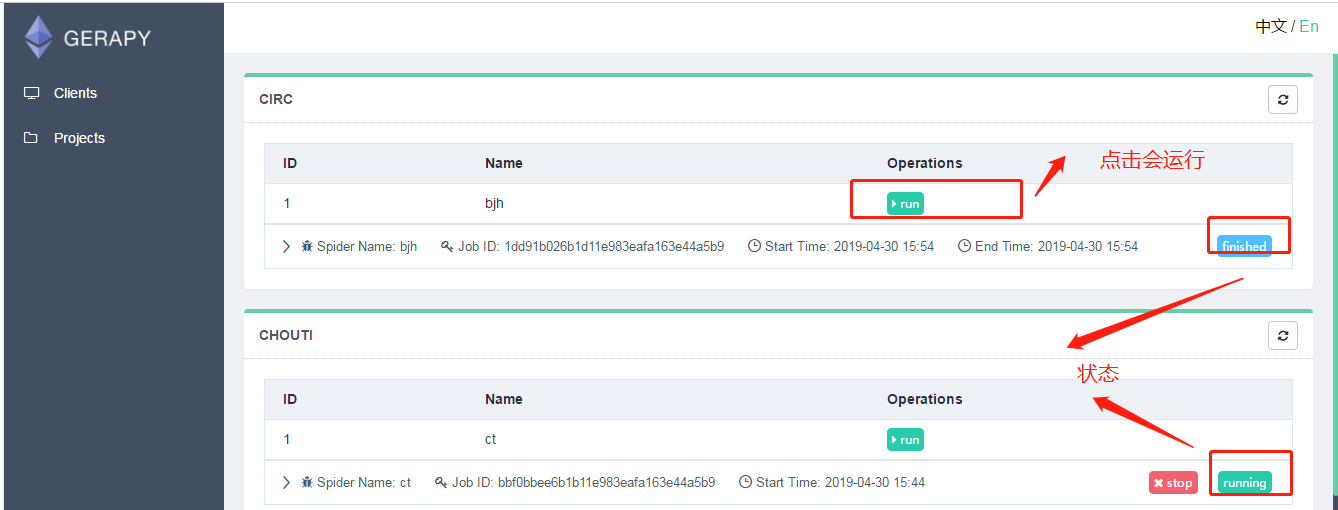
如果想执行爬虫,就点击调度.然后运行.
前提是: 我们配置的scrapyd中,已经发布了 爬虫.
Gerapy 与 scrapyd 有什么关联吗?
我们仅仅使用scrapyd是可以调用scrapy进行爬虫. 只是 需要使用命令行开启爬虫
curl http://127.0.0.1:6800/schedule.json -d project=工程名 -d spider=爬虫名
· 使用Greapy就是为了将使用命令行开启爬虫变成 “小手一点”. 我们在gerapy中配置了scrapyd后,不需要使用命令行,可以通过图形化界面直接开启爬虫.
2.部署项目
我们就可以把我们写好的爬虫文件放在生成的文件夹gerapy下projects内,然后刷新网页就可以发现项目就在里边了
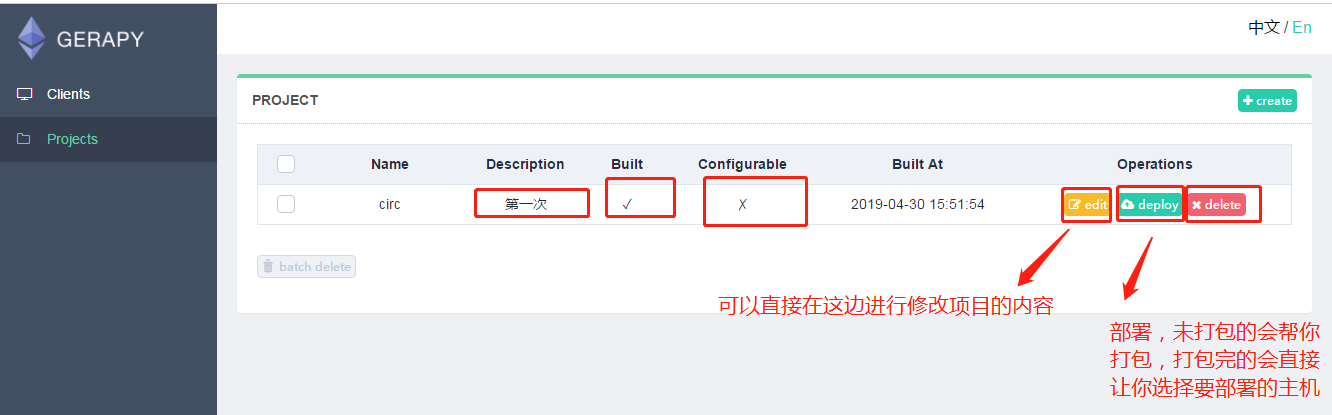
然后我们点击部署按钮就可以进行打包和部署了,描述是自定义的,这个只会在gerapy上显示,然后会提示我们打包成功,同时左侧会显示打包的结果和打包的名称。
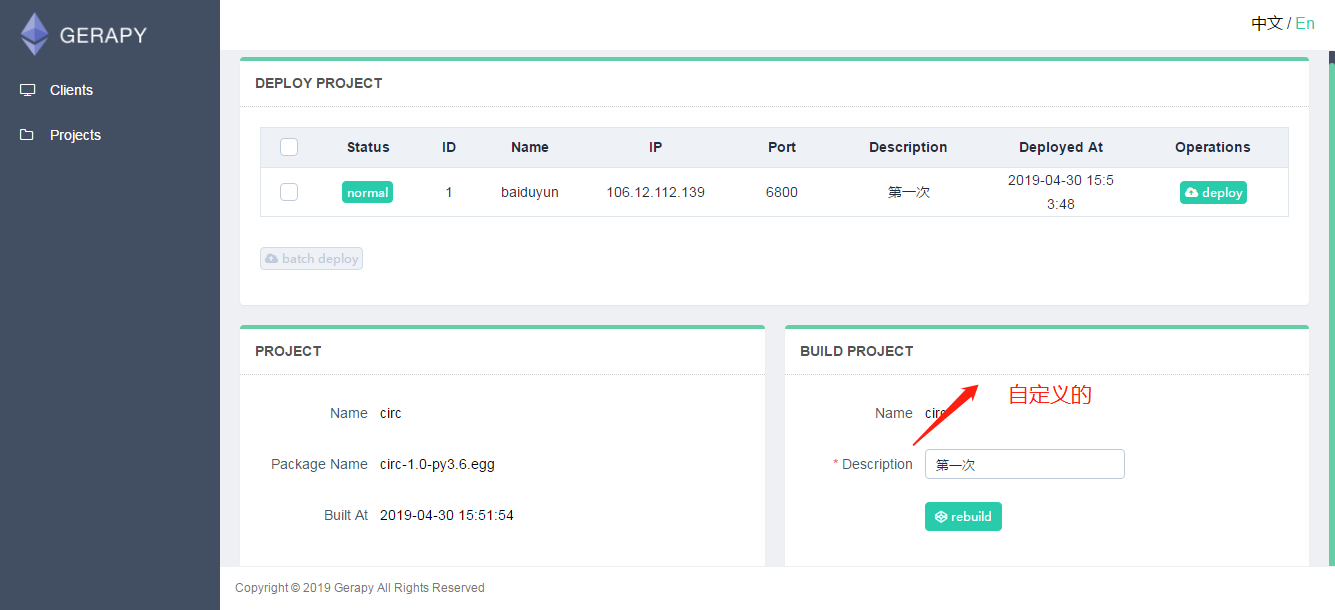
打包成功后我们就可以在进行部署了,如果有多个主机的话,我们就需要选择部署的主机,点击后边部署按钮,也可以同时批量选择主机进行部署。
然后我们就可以在主机的项目页面点击主机,看到爬虫的运行状态,并且不用在cmd中输入命令,通过点击就可以让爬虫
运行,停止,并且查看运行状态。
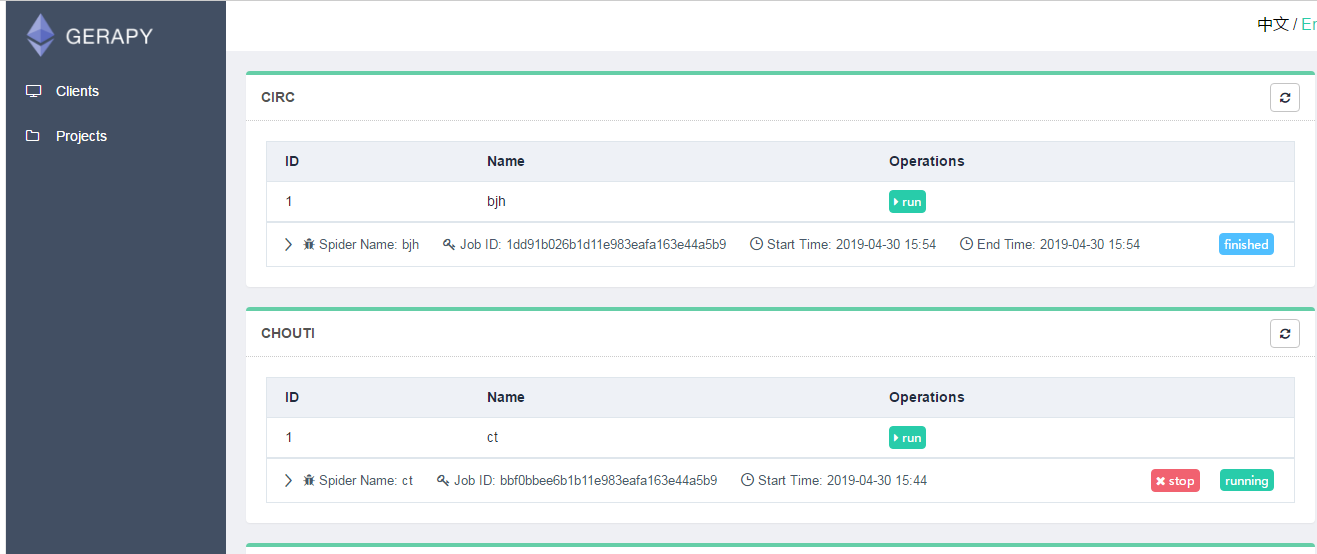
最后,gerapy也支持在其网页上自建爬虫项目,具体这里就不介绍了。
gerapy的初步使用(管理分布式爬虫)的更多相关文章
- gerapy+scrapyd组合管理分布式爬虫
Scrapyd是一款用于管理scrapy爬虫的部署和运行的服务,提供了HTTP JSON形式的API来完成爬虫调度涉及的各项指令.Scrapyd是一款开源软件,代码托管于Github上. 点击此链接h ...
- scrapydweb的初步使用(管理分布式爬虫)
https://github.com/my8100/files/blob/master/scrapydweb/README_CN.md 一.安装配置 1.请先确保所有主机都已经安装和启动 Scrapy ...
- Scrapy+Scrapy-redis+Scrapyd+Gerapy 分布式爬虫框架整合
简介:给正在学习的小伙伴们分享一下自己的感悟,如有理解不正确的地方,望指出,感谢~ 首先介绍一下这个标题吧~ 1. Scrapy:是一个基于Twisted的异步IO框架,有了这个框架,我们就不需要等待 ...
- 跟繁琐的命令行说拜拜!Gerapy分布式爬虫管理框架来袭!
背景 用 Python 做过爬虫的小伙伴可能接触过 Scrapy,GitHub:https://github.com/scrapy/scrapy.Scrapy 的确是一个非常强大的爬虫框架,爬取效率高 ...
- scrapyd部署、使用Gerapy 分布式爬虫管理框架
Scrapyd部署爬虫项目 GitHub:https://github.com/scrapy/scrapyd API 文档:http://scrapyd.readthedocs.io/en/stabl ...
- 第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理
第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理 1.映射(mapping)介绍 映射:创建索引的时候,可以预先定义字 ...
- 四十三 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理
1.映射(mapping)介绍 映射:创建索引的时候,可以预先定义字段的类型以及相关属性elasticsearch会根据json源数据的基础类型猜测你想要的字段映射,将输入的数据转换成可搜索的索引项, ...
- Python分布式爬虫原理
转载 permike 原文 Python分布式爬虫原理 首先,我们先来看看,如果是人正常的行为,是如何获取网页内容的. (1)打开浏览器,输入URL,打开源网页 (2)选取我们想要的内容,包括标题,作 ...
- 基于Python,scrapy,redis的分布式爬虫实现框架
原文 http://www.xgezhang.com/python_scrapy_redis_crawler.html 爬虫技术,无论是在学术领域,还是在工程领域,都扮演者非常重要的角色.相比于其他 ...
随机推荐
- Google AdWords 广告排名首选项
排名首选项目标:了解 AdWords 广告客户可怎样为其广告设置排名首选项. 排名首选项简介 通过排名首选项,用户可以告诉 Google 他们希望其广告在给定网页上的所有 AdWords 广告中所处的 ...
- Windows下安装Redis及php的redis拓展教程
一.安装前必读 Windows 64位操作系统 Redis 安装包(版本3.0.5,截止2017-05-29最新redis版本为3.2.9) 注意事项: 1.在window下如果你还需安装php的re ...
- CI框架下的PHP增删改查总结
controllers下的 cquery.php文件 <?php class CQuery extends Controller { //构造函数 function CQuery() { par ...
- 从Objective-C到Swift,你必须会的(三)init的顺序
Objective-C的构造函数吧,就最后return一个self.里头你要初始化了什么都可以.在Swift的init函数里把super.init放在前面,然后再初始化你代码里的东西就会报错了. 所以 ...
- 个人项目-词频统计(语言:C++)
词频统计 (个人项目) 要求 (1). 实现一个控制台程序,给定一段英文字符串,统计其中各个英文单词(4字符以上含4字符)的出现频率. 附加要求:读入一段文本文件,统计该文本文件中单词的频率. (2) ...
- linux下svn服务器的搭建
网上的教程实在是太恶心了,不是太老,就是有问题,刚参考的一篇文章也有问题.自己记录下来,以后用就方便了,现在一边重新安装一遍,一边记录.笔者亲测,今天是5月29号深夜. linux用的是centos6 ...
- Elasticsearch中的索引管理和搜索常用命令总结
添加一个index,指定分片是3,副本是1 curl -XPUT "http://10.10.110.125:9200/test_ods" -d' { "settings ...
- Wpf Page间跳转传参数 And Window To Page
这段时间用到Wpf,页面间的跳转网上有不少的示例,但是有些已经不能用了,尤其是页面间的传参问题更是一大堆,但正确的解决方案却没有几个,或者说写的不清楚,让人走了很多弯路,查看官方文档后发现了正确的姿势 ...
- C#多边形求角——实例说
前段时间有写过一个计算多边形角度的代码,这里给它整理整理,留给自己也送给萌新. 看左下图,这是一个多环的多边形,一个外环(内部为多边形内部区域),一个内环(外部为多边形内部区域),同时多边形中任意一个 ...
- ES6学习之ES5之后新增的字符串方法
1.字符串模板:用法:`${变量名}` (好像是C#6.0中也引入了类似的方法.C#中的用法:$"我是{变量名}" ---> $"我叫{name}" ,相 ...