【论文阅读】Beyond OCR + VQA: 将OCR融入TextVQA的执行流程中形成更鲁棒更准确的模型
论文题目:Beyond OCR + VQA: Involving OCR into the Flow for Robust and Accurate TextVQA
论文链接:https://dl.acm.org/doi/abs/10.1145/3474085.3475606
一、任务概述
- 视觉问答任务(VQA):将图像和关于图像的自然语言问题作为输入,并生成自然语言答案作为输出。
- 文本视觉问答任务(TextVQA):面向文字识别的问答任务。
二、Baseline
2.1 Baseline 1: Look, Read, Reason & Answer (LoRRA):
- 2019年提出,推出标准数据集,原文地址:https://arxiv.org/abs/1904.08920v2
- 典型的TextVQA:将问题回答建模为分类任务,需要给定答案空间。
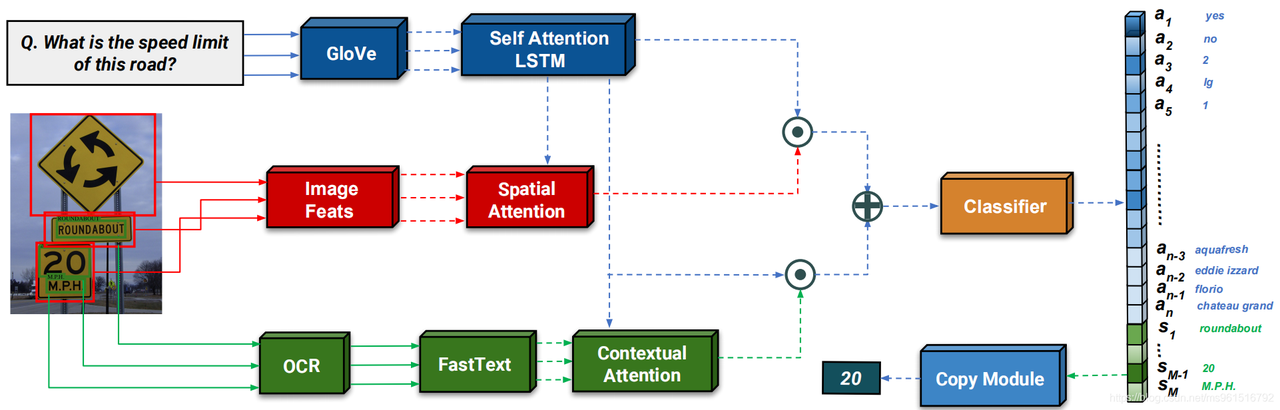
- 多模态嵌入:问题embedding、图像中的物体进行embedding、OCR的结果进行embedding(FastText做pre-train)
- 嵌入方式:
- 对问题进行GloVe Embedding,再通过LSTM得到问题嵌入 fQ(q),用于后续对图片特征以及OCR样本进行注意力加权平均。
- 将图像进行特征提取,提取的特征fI(v)与fQ(q)一起经过注意力机制得到加权的空间注意力,得到的结果与fQ(q)进行组合。
- OCR模块基于预训练模型(Faster RCNN + CTC)进行识别,识别出的结果fO(s)与fQ(q)一起经过注意力机制得到加权的空间注意力,得到的结果与fQ(q)进行组合。
- contact一起之后过分类器(MLP),分类的类别为问题空间a1……an 加上 OCR是识别出的词
2.2 Baseline 2:M4C
- 主贡献:提出了迭代预测的解码方式,但我们更关注特征表示的部分
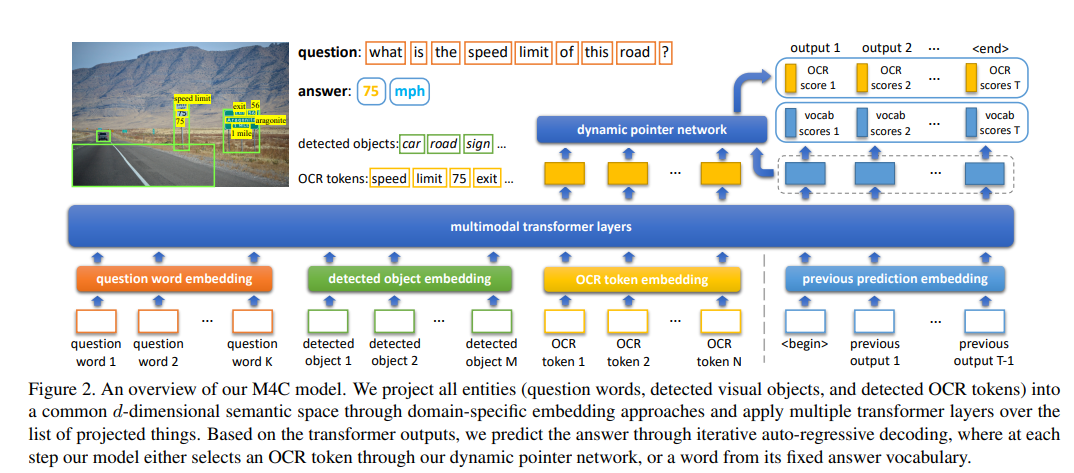
- Question embedding:BERT-base模型的encoder,但只用前3层,得到矩阵shape=(K, d)
- Detected object embedding:Faster-RCNN + Position,shape=(M, d)
- 融合方式:Linear + LayerNorm
- OCR token embedding 由四部分组成:
: 300维的FastText文本特征
: Faster RCNN特征,和detected object的获取方式一样
: 604维的Pyramidal Histogram of Characters(PHOC)特征
: 4维的位置特征,计算方式和detected object一样
- 融合方式:前三个特征过linear后做layernorm,position单独融合,再加起来
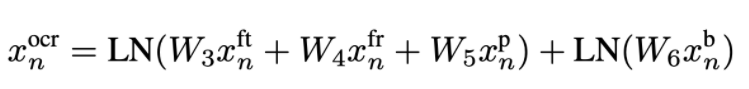
三、Motivation
- OCR的错误识别会较大程度影响多模态信息之间的交互(即fA的过程)
- 因为在表征空间中需要copy OCR识别的token,OCR的错误会较严重的影响解码器的性能(哪怕另两个分支完全准确也没法正确的输出)
四、Method
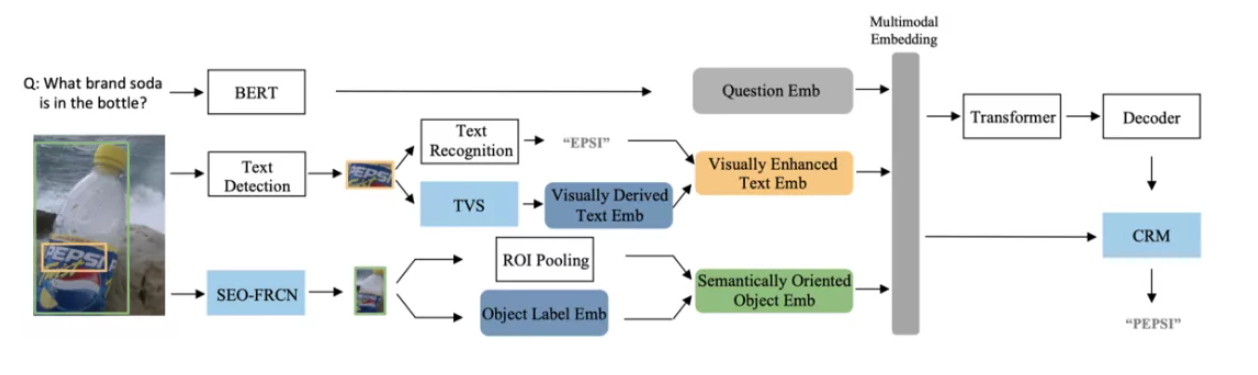
4.1 Contribution
- 增强特征表示的鲁棒性:减小OCR错误和物体识别错误对推理的影响
- 增强解码器的鲁棒性:在答案预测模块提出一个上下文感知的答案修正模块(CRM)对“复制”的答案词进行校正。
4.2 Architectural Details—— 视觉增强的文字表征模块 TVS (OCR增强)
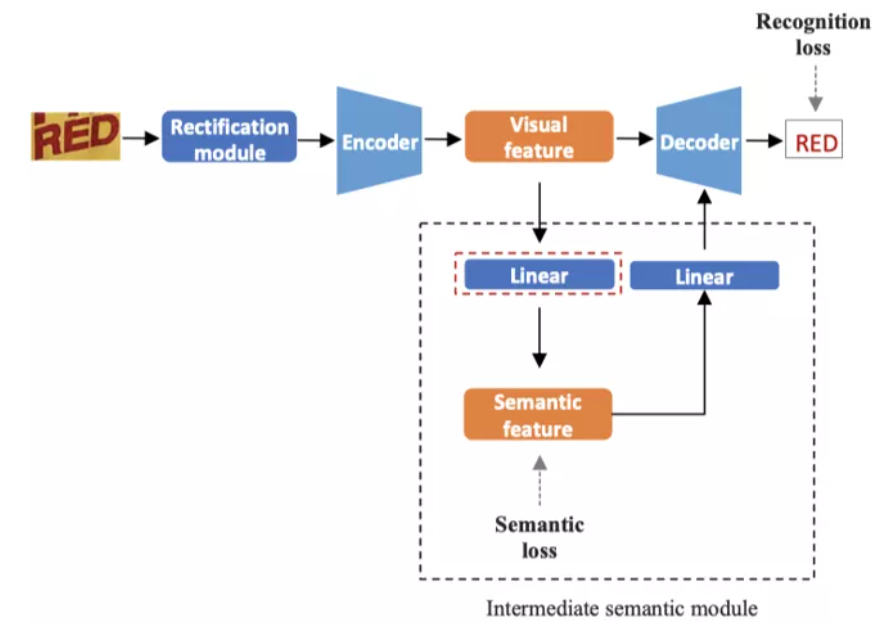
- method:
- 文字图像矫正模块
- 编码模块:45层ResNet+ 2层Bi-LSTM
- 解码模块:单层 注意力机制的GRU
- 中间语义模块:根据文字视觉信息预测语义信息
- train:利用外部数据集训练(SynthText + Synth90K)
- loss: OCR识别损失+语义损失
- 语义损失由真实和预测的语义特征向量间的余弦距离计算得到
- 优势:
- 通过语义损失的监督,编码模块能产生与文字解码更相关的视觉特征
- TVS为直接由文字图像的视觉特性获得语义表示提供可能。
- 整网中推理,OCR token details(n个文本框):
: TVS的视觉特征
- 融合方式:
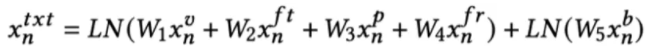
4.3 Architectural Details—— 语义导向的物体表征 SEO-FRCN(Visual增强)

- method:传统的Faster RCNN,在解码环节增加一个分支来 预测物体类别的embedding
- 物体类别embedding的gt 时物体类别名称的语义特征。
- train:使用Visual Genome数据集,backbone resnet101 预训练,新分支fine tune
- loss:RPN loss + 四分支loss
- 优势:能够拉近相似物体的图像相似度(例如 traffic light和traffic sign)
- 整网中推理,Visual token details(m个物体):
:视觉特征
- 特征融合:
4.3 Architectural Details——上下文感知的答案修正 CRM (解码结果增强)

- method:在推理阶段,对于”直接复制OCR结果”进行改进。
- 如果解码的输出指向图像中的文字,则将它视作一个候选词,利用输入的问题、其他文字信息和相关物体信息进行文字修正。
- 使用多个OCR模块输出多个预测结果作为候选集,选出得分最高的结果作为最后的输出。
- 组成:Transformer进行上下文信息融合 + linear&sigmoid 二分类器
- training:如果候选集的结果与gt相同则为1,不同则为0,构建训练数据。二分类预测一个相关分数,最小化交叉熵损失进行训练。
五、Experiment
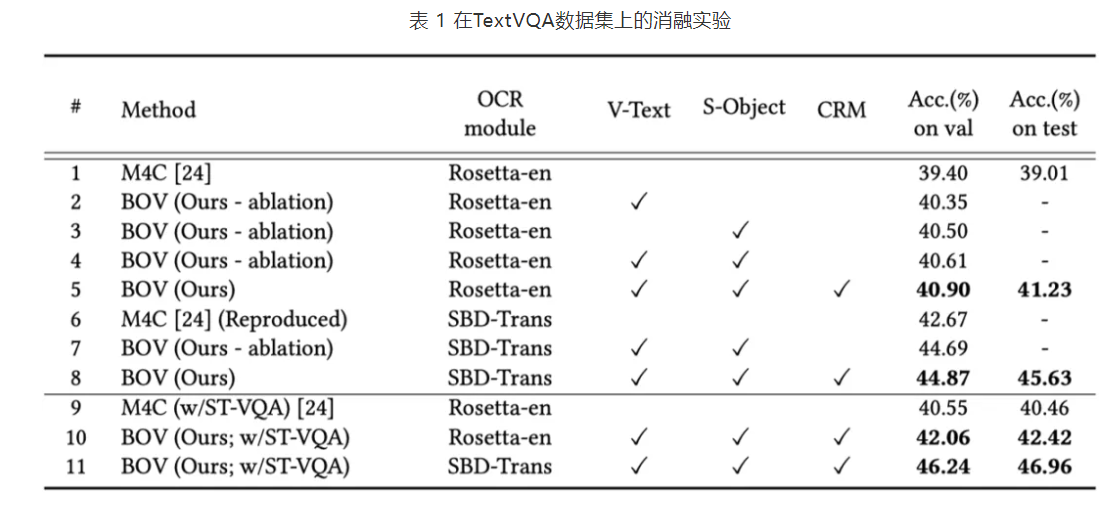
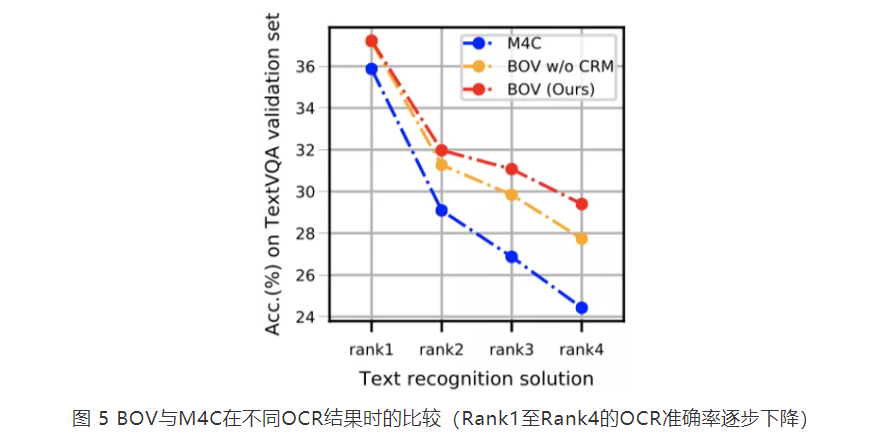
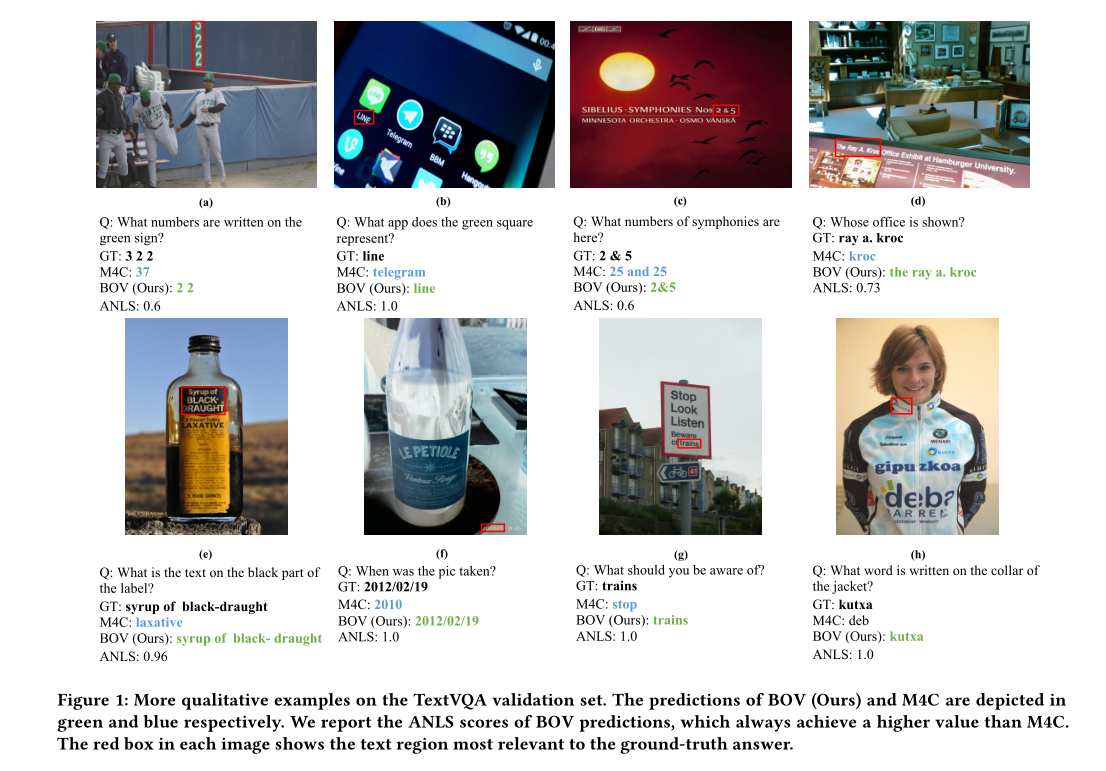
六、结论
- 将OCR融入TextVQA的前向处理流程,构建了一个鲁棒且准确的TextVQA模型
参考博客
【论文阅读】Beyond OCR + VQA: 将OCR融入TextVQA的执行流程中形成更鲁棒更准确的模型的更多相关文章
- 论文阅读:Face Recognition: From Traditional to Deep Learning Methods 《人脸识别综述:从传统方法到深度学习》
论文阅读:Face Recognition: From Traditional to Deep Learning Methods <人脸识别综述:从传统方法到深度学习> 一.引 ...
- 论文阅读(Xiang Bai——【CVPR2015】Symmetry-Based Text Line Detection in Natural Scenes)
Xiang Bai--[CVPR2015]Symmetry-Based Text Line Detection in Natural Scenes 目录 作者和相关链接 方法概括 创新点和贡献 方法细 ...
- 论文阅读笔记四十七:Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression(CVPR2019)
论文原址:https://arxiv.org/pdf/1902.09630.pdf github:https://github.com/generalized-iou 摘要 在目标检测的评测体系中,I ...
- 【论文阅读】Learning Spatial Regularization with Image-level Supervisions for Multi-label Image Classification
转载请注明出处:https://www.cnblogs.com/White-xzx/ 原文地址:https://arxiv.org/abs/1702.05891 Caffe-code:https:// ...
- 【论文阅读】Deep Mutual Learning
文章:Deep Mutual Learning 出自CVPR2017(18年最佳学生论文) 文章链接:https://arxiv.org/abs/1706.00384 代码链接:https://git ...
- 【阅读SpringMVC源码】手把手带你debug验证SpringMVC执行流程
✿ 阅读源码思路: 先跳过非重点,深入每个方法,进入的时候可以把整个可以理一下方法的执行步骤理一下,也可以,理到某一步,继续深入,回来后,接着理清除下面的步骤. ✿ 阅读本文的准备工作,预习一下Spr ...
- 论文阅读(Weilin Huang——【AAAI2016】Reading Scene Text in Deep Convolutional Sequences)
Weilin Huang--[AAAI2016]Reading Scene Text in Deep Convolutional Sequences 目录 作者和相关链接 方法概括 创新点和贡献 方法 ...
- 论文阅读(Xiang Bai——【TIP2014】A Unified Framework for Multi-Oriented Text Detection and Recognition)
Xiang Bai--[TIP2014]A Unified Framework for Multi-Oriented Text Detection and Recognition 目录 作者和相关链接 ...
- [论文阅读笔记] Fast Network Embedding Enhancement via High Order Proximity Approximati
[论文阅读笔记] Fast Network Embedding Enhancement via High Order Proximity Approximation 本文结构 解决问题 主要贡献 主要 ...
随机推荐
- dev分支和release是什么
master(主分支) 存在一条主分支(master).所有用户可见的正式版本,都从master发布(也是用于部署生产环境的分支,确保master分支稳定性).主分支作为稳定的唯一代码库,不做任何开发 ...
- Java初步学习——2021.09.23每日报告,第三周周四
(1)今天做了什么: (2)明天准备做什么? (3)遇到的问题,如何解决? 学习数组,编写了一个随机选牌的代码.自己最开始一直想只设置一个字符串数组,利用随机数来输出,但那样对字符串赋值会比较麻烦.可 ...
- MyBatis原生批量插入的坑与解决方案!
前面的文章咱们讲了 MyBatis 批量插入的 3 种方法:循环单次插入.MyBatis Plus 批量插入.MyBatis 原生批量插入,详情请点击<MyBatis 批量插入数据的 3 种方法 ...
- 乘风破浪,遇见最美Windows 11之新微软商店(Microsoft Store)生态 - 安卓(Android™)开发体验指南
什么是Windows 11的安卓(Android)应用 2021年6月25日,微软召开线上发布会,对外宣告下一代Windows操作系统Windows 11,Windows 11为用户重新打造的Micr ...
- 保护模式篇——TLB与CPU缓存
写在前面 此系列是本人一个字一个字码出来的,包括示例和实验截图.由于系统内核的复杂性,故可能有错误或者不全面的地方,如有错误,欢迎批评指正,本教程将会长期更新. 如有好的建议,欢迎反馈.码字不易, ...
- CSP-S2021幽寂
不管怎么说,这次比赛考的比这一段时间以来的模拟赛都难看 难受,但是也不想太表现出来,所以更难受.... 有点害怕会退役...... Day -6 前一天晚上回宿舍的时候和\(zxs\)一路,聊的过程中 ...
- Spring中自定义Schema扩展机制
一.前言 Spring 为基于 XML 构建的应用提供了一种扩展机制,用于定义和配置 Bean. 它允许使用者编写自定义的 XML bean 解析器,并将解析器本身以及最终定义的 Bean 集成到 S ...
- error: unsupported reloc 43
在Ubuntu 16.04.5 LTS编译android 5.1报错 [19:17:13.062]libnativehelper/JniInvocation.cpp:165: error: unsup ...
- 链表中环的入口结点 牛客网 剑指Offer
链表中环的入口结点 牛客网 剑指Offer 题目描述 给一个链表,若其中包含环,请找出该链表的环的入口结点,否则,输出null. # class ListNode: # def __init__(se ...
- 最近公共祖先 牛客网 程序员面试金典 C++ Python
最近公共祖先 牛客网 程序员面试金典 C++ Python 题目描述 有一棵无穷大的满二叉树,其结点按根结点一层一层地从左往右依次编号,根结点编号为1.现在有两个结点a,b.请设计一个算法,求出a和b ...