RobotFramework + Python 自动化入门 三 (Web自动化)
在《RobotFramwork + Python 自动化入门 一》中,完成了一个Robot环境搭建及测试脚本的创建和执行。
在《RobotFramwork + Python 自动化入门 二》中,对RobotFramework的关键字使用和查看源码进行了介绍。
本节,介绍基于Web的RF自动化。
一、环境配置
1. 下载浏览器驱动程序
执行web端的测试脚本时,需要浏览器驱动,不同浏览器对应不同的驱动程序。
浏览器的驱动版本 要和 浏览器版本号对应或适配。
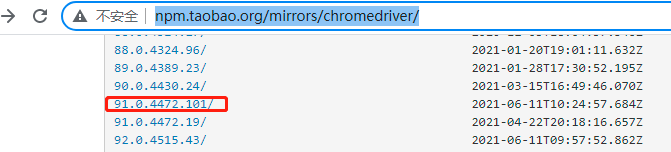
Chrome driver下载地址:http://npm.taobao.org/mirrors/chromedriver/
或百度搜索其他下载方式。
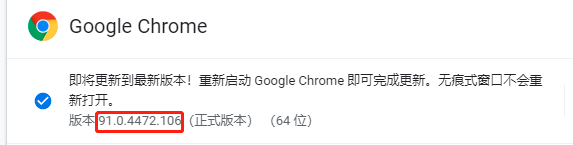
我的Chrome版本号为91.0.4472.106, 故下载最接近的chromedriver。
下载完成后放入Python安装目录(或者其他文件夹,但该文件夹要加入path路径)。
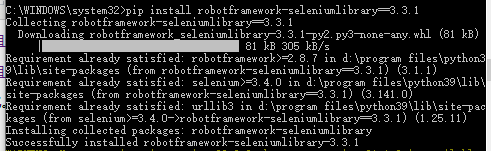
2.安装selenium库
安装命令(安装最新版): pip install robotframework-seleniumlibrary
指定版本号安装:pip install robotframework-seleniumlibrary==3.3.1
3. 添加依赖库
在RF项目中添加selenium library。
方法一:
双击打开red.xml文件,点击+按钮添加library。
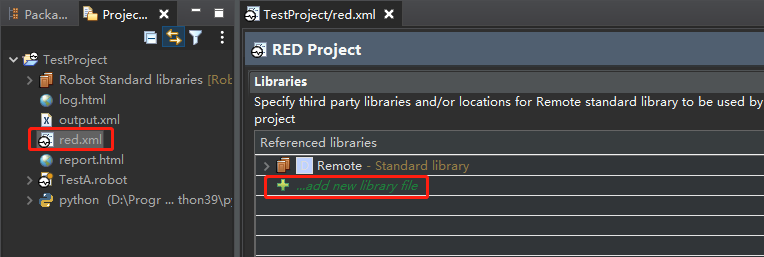
选择Python安装目录下的 \Lib\site-packages\SeleniumLibrary 文件夹中的__init__.py文件。
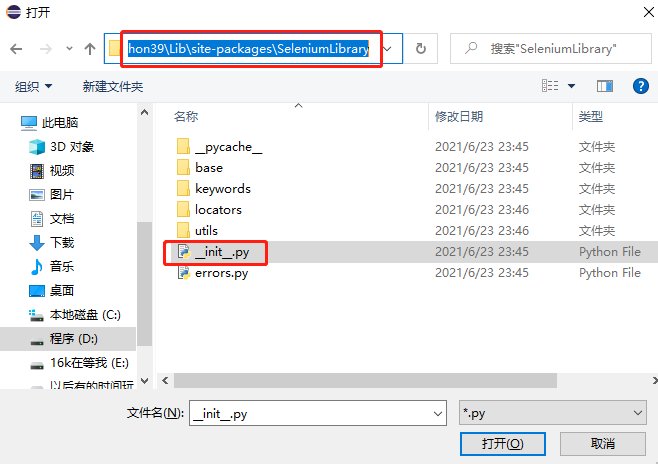
选择第一个SeleniumLibrary,点击OK。
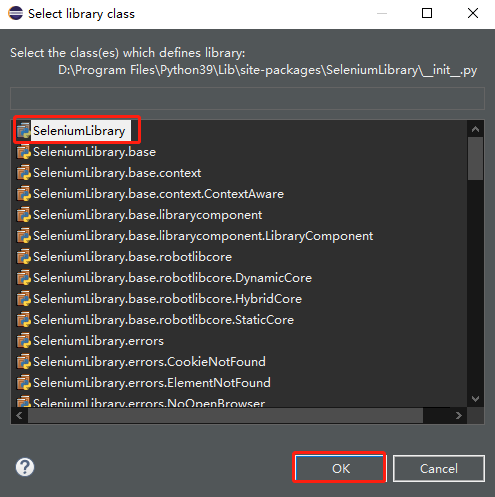
SeleniumLibrary添加成功。

点击保存按钮或 CTRL+S 快捷键。
Project目录下多了一个Robot Referenced libraries目录,SeleniumLibrary是其子目录,所有添加的第三方依赖都在这个目录下。
方法二:
右键 red.xml文件,点击Open With>Text Editor,以文本格式打开red.xml文件。

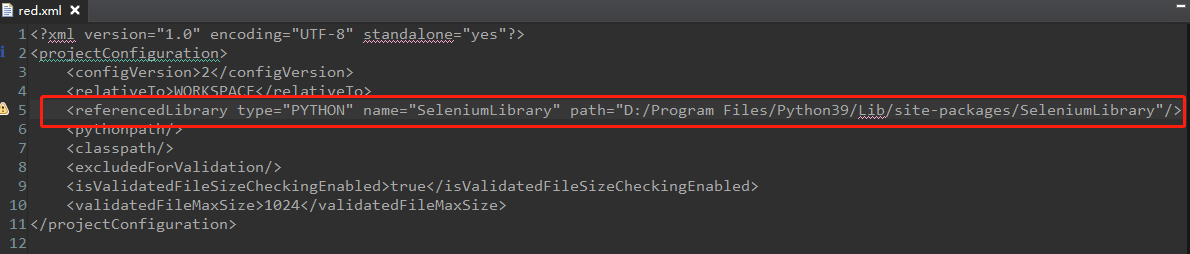
在red.xml文件中添加下方内容,保存:
<referencedLibrary type="PYTHON" name="SeleniumLibrary" path="D:/Program Files/Python39/Lib/site-packages/SeleniumLibrary"/>
4. 编码格式设置
在写中文环境的测试脚本时,经常会用到中文,故要设置编码格式为UTF-8。
如果不设置,当脚本中存在中文,执行脚本(robot文件)会报错。
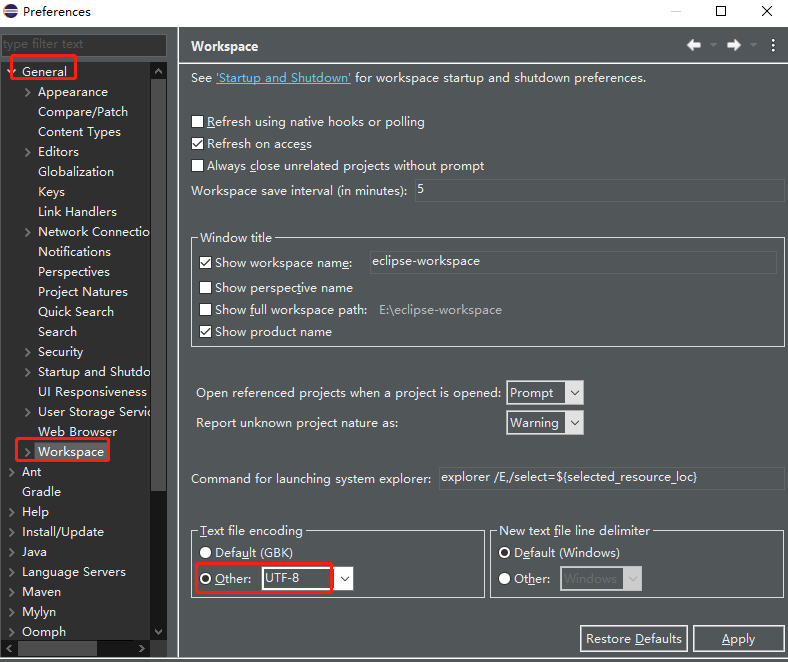
而且若只设置了单个项目的编码格式为UTF-8,在console界面会发现中文字符仍显示为乱码,故要设置整个workspace的编码格式。
设置方法:
菜单栏Window > Preferences > General > Workspace。
二、设计测试脚本
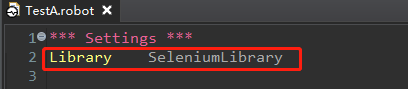
1. 引入SeleniumLibrary
当使用第三方库时,必须在文件中使用Library关键字 引入相应的库名。
2. 设计测试脚本
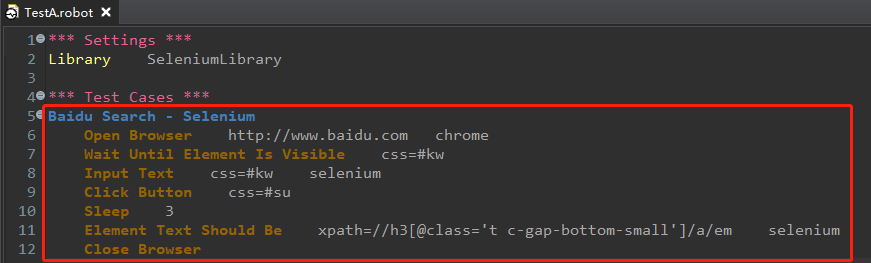
测试脚本流程如下:
1.打开谷歌浏览器,进入百度页面
2.搜索框中输入selenium
3.点击搜索按钮
4.页面搜索结果标题应包含selenium
5.关闭浏览器
测试脚本:
Baidu Search - Selenium
Open Browser http://www.baidu.com chrome # chrome表示启动谷歌浏览器
Wait Until Element Is Visible css=#kw # css=#kw是搜索框的locator,css表示locator使用的是css定位方式
Input Text css=#kw selenium # css=#kw是输入框的locator
Click Button css=#su
Sleep 3
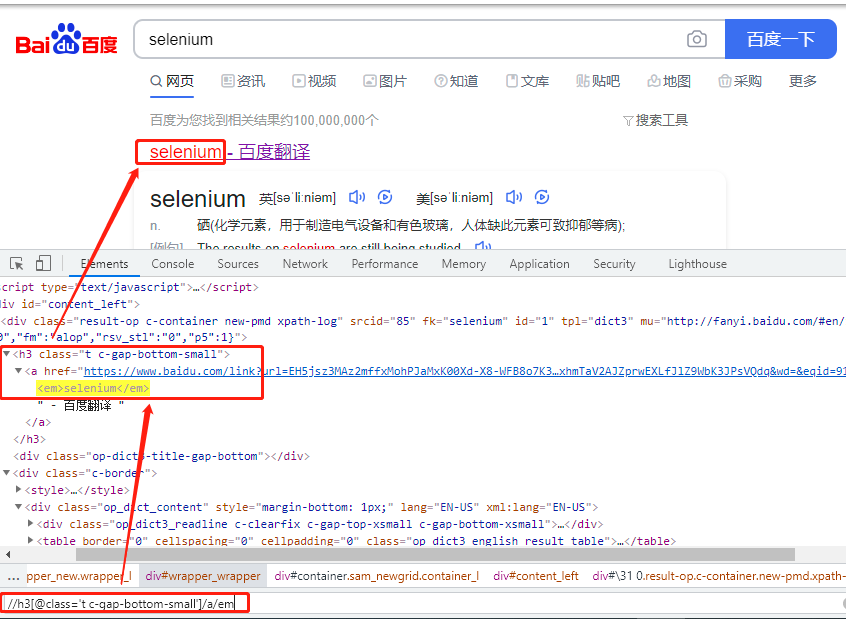
Element Text Should Be xpath=//h3[@class='t c-gap-bottom-small']/a/em selenium #xpath=//h3[@class='t c-gap-bottom-small']/a/em 是xpath格式的locator
Close Browser
Locator " xpath=//h3[@class='t c-gap-bottom-small']/a/em" 的含义如下:
3. 执行脚本
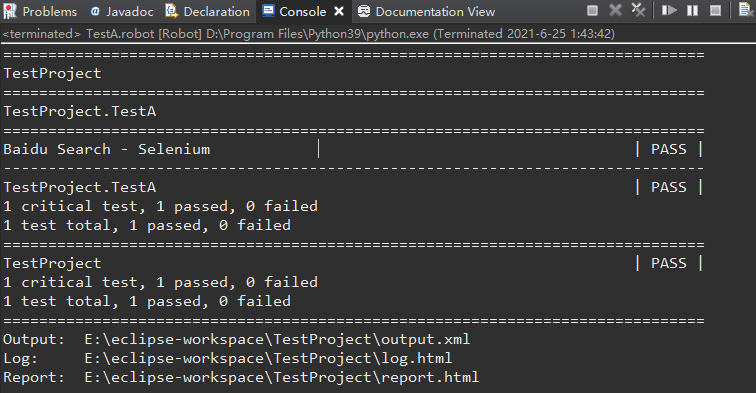
选择脚本文件,右键执行,或者直接点击工具栏”执行‘按钮。

执行结果如下:
RobotFramework + Python 自动化入门 三 (Web自动化)的更多相关文章
- 3.Python爬虫入门三之Urllib和Urllib2库的基本使用
1.分分钟扒一个网页下来 怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器解释才呈现出来的,实质它是一段HTML代码,加 JS.CSS ...
- 转 Python爬虫入门三之Urllib库的基本使用
静觅 » Python爬虫入门三之Urllib库的基本使用 1.分分钟扒一个网页下来 怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器 ...
- python爬虫入门三:requests库
urllib库在很多时候都比较繁琐,比如处理Cookies.因此,我们选择学习另一个更为简单易用的HTTP库:Requests. requests官方文档 1. 什么是Requests Request ...
- Python爬虫入门三之Urllib库的基本使用
转自http://cuiqingcai.com/947.html 1.分分钟扒一个网页下来 怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由 ...
- RobotFramework + Python 自动化入门 四 (Web进阶)
在<RobotFramwork + Python 自动化入门 一>中,完成了一个Robot环境搭建及测试脚本的创建和执行. 在<RobotFramwork + Python 自动化入 ...
- Python爬虫入门之Urllib库的基本使用
那么接下来,小伙伴们就一起和我真正迈向我们的爬虫之路吧. 1.分分钟扒一个网页下来 怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器解 ...
- RobotFramework自动化测试框架-Selenium Web自动化(三)关于在RobotFramework中如何使用Selenium很全的总结(下)
本文紧接着RobotFramework自动化测试框架-Selenium Web自动化(二)关于在RobotFramework中如何使用Selenium很全的总结(上)继续分享RobotFramewor ...
- RobotFramework + Python 自动化入门 二 (关键字)
在<RobotFramwork + Python 自动化入门 一>中,完成了Robot环境搭建及测试脚本的创建和执行. 本节,对RobotFramework的关键字使用和查看源码进行介绍. ...
- RobotFramework自动化测试框架-Selenium Web自动化(二)关于在RobotFramework中如何使用Selenium很全的总结(上)
好久没有继续分享关于自动化测试相关的东西了,自动化在现今的测试领域已经越来越重要了,大部分公司在测试岗位招聘中都需要会相关的自动化测试知识.而 RobotFramework自动化测试框架 是自动化测试 ...
随机推荐
- activiti知识点梳理
一.Activiti是什么 Alfresco 软件在 2010 年 5 月17 日宣布 Activiti业务流程管理(BPM)开源项目的正式启动,其首席架构师由业务流程管理 BPM的专家 Tom Ba ...
- 『动善时』JMeter基础 — 18、JMeter配置元件【计数器】
目录 1.计数器介绍 2.计数器界面详解 3.计数器的使用 (1)测试计划内包含的元件 (2)线程组界面内容 (3)计数器界面内容 (4)HTTP请求界面内容 (5)查看结果 1.计数器介绍 如果需要 ...
- mysql登录框注入绕过单引号匹配
0x00 原理 网站使用正则匹配对用户名一栏传到服务器的参数进行了匹配,如果匹配到了单引号则报错 0x01 简单例子 当我们输入admin'时,网站直接报错,很有可能就是用了正则,这样我们也不 ...
- Envoy:开启访问日志,access_log
access_log: - name: envoy.listener.accesslog typed_config: "@type": type.googleapis.com/en ...
- CSS3 变形
目录 Transform Transform与坐标系统 transform-origin transform-style 二维旋转 旋转 rotate 平移 translate translateX ...
- [bug] Hive:map.xml could only be replicated to 0 nodes instead of minReplication (=1). There are 0 datanode(s) running and no node(s) are excluded in this operation.
原因: datanode未运行,重启hdfs
- [bug] CDH安装中断 再次安装显示当前受管 无法选择
参考 https://blog.csdn.net/JacksonKing/article/details/104350313 重装 https://blog.csdn.net/simle168/art ...
- [C] gcc
概述 GNU C Compiler 流程 预处理,生成.i文件(中间文件,看不到) 编译,生成.s文件(中间文件,看不到) 汇编,生成.o文件 链接,生成可执行文件 参数 -E:预处理 -S:预处理, ...
- gitbook安装使用教程
以下是gitbook的简略安装使用过程,可以参考一下.后续有时间我再回头修改完善实验目的:安装gitbook后,将相关的文件发布到gitlab上安装node.js在cmd下执行安装npm instal ...
- brk 和 sbrk 区别
转自:https://www.cnblogs.com/chengxuyuancc/p/3566710.html brk和sbrk的定义,在man手册中定义了这两个函数: 1 #include < ...