我用python爬取了知乎Top沙雕问题排行榜
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者: 数据森麟
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef
这两天偶然上网的时候,被知乎上一个名为“玉皇大帝住在平流层还是对流层”的问题吸引,本以为只是小打小闹,殊不知这个问题却在知乎上引发了强烈共鸣,浏览次数500W+,7000+关注: 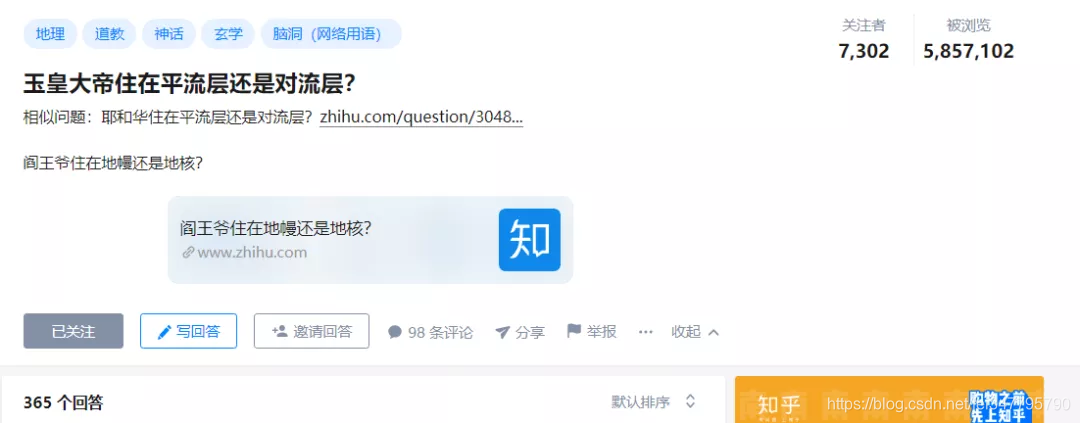
数据来源
知乎非常“贴心”地专门有一个问题可以满足我们的需求,出人意料的是这个问题居然有243个回答,并且陶飞同学获得了3W+的赞同
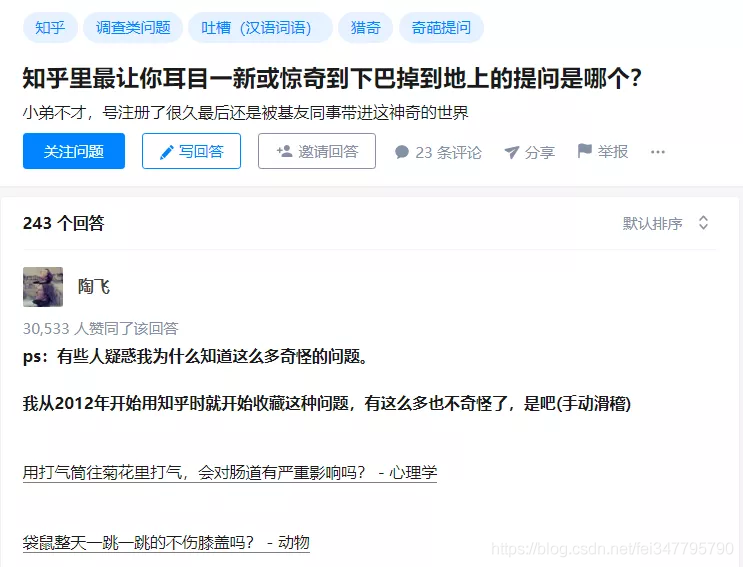
我们从中爬取了所有回答中出现的问题链接,共用400多个问题,其中陶飞就提供了200+,在此向陶飞同学表示感谢,帮助我们构建了“沙雕数据库”,这部分代码如下:
import re
import selenium
from selenium import webdriver
import requests
from bs4 import BeautifulSoup
import pandas as pd
import time
driver = webdriver.Chrome()
driver.maximize_window()
url = 'https://www.zhihu.com/question/37453271'
js='window.open("'+url+'")'
driver.execute_script(js)
driver.close()
driver.switch_to_window(driver.window_handles[0])
for i in range(100):
js="var q=document.documentElement.scrollTop=10000000"
driver.execute_script(js)
all_html = [k.get_property('innerHTML') for k in driver.find_elements_by_class_name('AnswerItem')]
all_text = ''.join(all_html)
#all_text = all_text.replace('\u002F','/')
all_text = all_text.replace('questions','question')
pat = 'question/\d+'
questions = list(set([k for k in re.findall(pat,all_text)]))
获得到了问题的对应的编号后,就可以去各自的页面获取各个问题对应的的标题、浏览数等信息,如下图所示: 
这部分代码如下:
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win32; x32; rv:54.0) Gecko/20100101 Firefox/54.0',
'Connection': 'keep-alive'}
cookies ='v=3; iuuid=1A6E888B4A4B29B16FBA1299108DBE9CDCB327A9713C232B36E4DB4FF222CF03; webp=true; ci=1%2C%E5%8C%97%E4%BA%AC; __guid=26581345.3954606544145667000.1530879049181.8303; _lxsdk_cuid=1646f808301c8-0a4e19f5421593-5d4e211f-100200-1646f808302c8; _lxsdk=1A6E888B4A4B29B16FBA1299108DBE9CDCB327A9713C232B36E4DB4FF222CF03; monitor_count=1; _lxsdk_s=16472ee89ec-de2-f91-ed0%7C%7C5; __mta=189118996.1530879050545.1530936763555.1530937843742.18'
cookie = {}
for line in cookies.split(';'):
name, value = cookies.strip().split('=', 1)
cookie[name] = value
questions_df = pd.DataFrame(columns = ['title','visit','follower','answer','is_open'])
for i in range(len(questions)):
try:
url = 'https://www.zhihu.com/'+questions[i]
html = requests.get(url,cookies=cookie, headers=header).content
bsObj = BeautifulSoup(html.decode('utf-8'),"html.parser")
text = str(bsObj)
title = bsObj.find('h1',attrs={'class':'QuestionHeader-title'}).text
visit = int(re.findall('"visitCount":\d+',text)[0].replace('"visitCount":',''))
follower = int(re.findall('"followerCount":\d+',text)[0].replace('"followerCount":',''))
answer = int(re.findall('"answerCount":\d+',text)[0].replace('"answerCount":',''))
is_open = int(len(re.findall('问题已关闭',text))==0)
questions_df = questions_df.append({'title':title,'visit':visit,
'follower':follower,'answer':answer,
'is_open':is_open},ignore_index=True)
time.sleep(2)
print(i)
except:
print('错误'+str(i))
数据分析
在分享出最终的“沙雕排行榜”前,我们首先严肃认真(lixinggongshi)的进行一波分析,主要看一下问题中的关键词,首先是所有词云的词云: 
看来这些问题大多是源自于大家对于人生的探索,否则“为什么”,“如果”,“怎么办”也不会出现那么多,出人意料的是“体验”这个知乎专属tag居然并不多,可能是出于对知乎的尊重,和“体验”相关的问题都不会问得那么“沙雕”。
下面把这些助词去掉,再来看下结果:

这个图看来,读者关注的问题还是很极端,一方面在关注男女朋友“你冷酷、你无情、你无理取闹”这种问题,另一方面却在关注宇宙、地球这种关乎全人类的问题,很符合知乎“人均985,各个过百万”的人设。
这两个图实际上都是基于一个表情,不知道有没有看出来:

好吧,其实看不出来才是正常,能看出来的可能现在去知乎提个问题,下期就会上榜,最后把部分问题做出词云:

不知道大家能不能看清,说实话我自己是看不清的,也没准备让大家看清,目的就是引出下面真正的排行榜
沙雕问题排行榜
通过综合问题观看数,关注数,回答数,关注占比,回答占比,综合得到分数的流量指数和新奇指数,最终获得一个整体的分数,如下图所示: 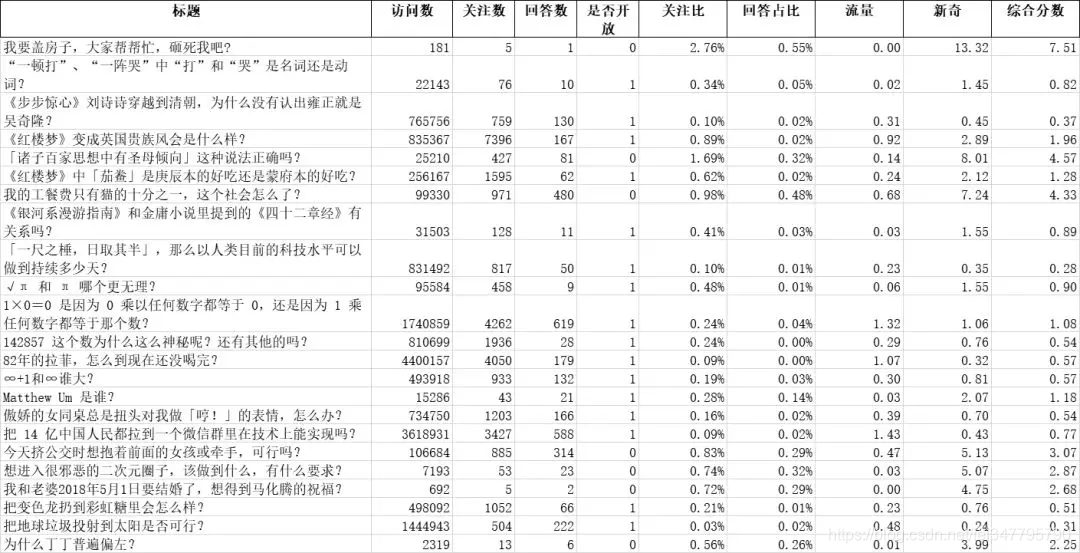
听起来是不是很复杂,实际上最终还是通过90%10%的数据+10%90%的主观来进行了排名,为大家精选了15个最为“沙雕”的问题,
我用python爬取了知乎Top沙雕问题排行榜的更多相关文章
- python爬取中国知网部分论文信息
爬取指定主题的论文,并以相关度排序. #!/usr/bin/python3 # -*- coding: utf-8 -*- import requests import linecache impor ...
- Python爬取中国知网文献、参考文献、引证文献
前两天老师派了个活,让下载知网上根据高级搜索得到的来源文献的参考文献及引证文献数据,网上找了一些相关博客,感觉都不太合适,因此特此记录,希望对需要的人有帮助. 切入正题,先说这次需求,高级搜索,根据中 ...
- Python爬虫从入门到放弃(十八)之 Scrapy爬取所有知乎用户信息(上)
爬取的思路 首先我们应该找到一个账号,这个账号被关注的人和关注的人都相对比较多的,就是下图中金字塔顶端的人,然后通过爬取这个账号的信息后,再爬取他关注的人和被关注的人的账号信息,然后爬取被关注人的账号 ...
- Python之爬虫(二十) Scrapy爬取所有知乎用户信息(上)
爬取的思路 首先我们应该找到一个账号,这个账号被关注的人和关注的人都相对比较多的,就是下图中金字塔顶端的人,然后通过爬取这个账号的信息后,再爬取他关注的人和被关注的人的账号信息,然后爬取被关注人的账号 ...
- Python爬取网页信息
Python爬取网页信息的步骤 以爬取英文名字网站(https://nameberry.com/)中每个名字的评论内容,包括英文名,用户名,评论的时间和评论的内容为例. 1.确认网址 在浏览器中输入初 ...
- 【Python爬虫案例】用Python爬取李子柒B站视频数据
一.视频数据结果 今天是2021.12.7号,前几天用python爬取了李子柒的油管评论并做了数据分析,可移步至: https://www.cnblogs.com/mashukui/p/1622025 ...
- Python 爬取所有51VOA网站的Learn a words文本及mp3音频
Python 爬取所有51VOA网站的Learn a words文本及mp3音频 #!/usr/bin/env python # -*- coding: utf-8 -*- #Python 爬取所有5 ...
- python爬取网站数据
开学前接了一个任务,内容是从网上爬取特定属性的数据.正好之前学了python,练练手. 编码问题 因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这个机会算是彻底搞清楚了. 问题要从文字的编码讲 ...
- python爬取某个网页的图片-如百度贴吧
python爬取某个网页的图片-如百度贴吧 作者:vpoet mail:vpoet_sir@163.com 注:随意copy,不用告诉我 #coding:utf-8 import urllib imp ...
随机推荐
- 如何完成述职报告或年终总结PPT
对于我们 打工仔 职场人士来说,年有年度总结,月有月度报告,指不定有些小伙伴还会有周报和日报,不仅枯燥,而且浪费时间,头都要炸了 ,简直太有趣了呢. 所以,如何准确快速的写完述职报告呢? 这是个好问题 ...
- 硬盘容量统计神器WinDirStat
最近遇到C盘快要爆满的问题,我的笔记本是128G SSD + 1t HDD,给C盘分配的空间是80G固态,由于平时疏远管理,造成了C盘臃肿,迁移一些软件,但还是没有太好的解决,这是上知乎发现有大神推荐 ...
- 输出所有java进程的gc状态
#!/bin/sh #read -t -p "请输入jstat命令监控间隔,次数:" time count read -p "输入jstat命令监控间隔(1s输出一次,输 ...
- kmeans均值聚类算法实现
这个算法中文名为k均值聚类算法,首先我们在二维的特殊条件下讨论其实现的过程,方便大家理解. 第一步.随机生成质心 由于这是一个无监督学习的算法,因此我们首先在一个二维的坐标轴下随机给定一堆点,并随即给 ...
- iOSMultipeerConnectivity使用
MultipeerConnectivity是iOS7推出的多点连接框架,多用于文件传输,类似于iOS设备的airTrop隔空投放,在没有联网的情况下也能聊天传文件. 使用方法,一个设备作为广播开放Pe ...
- jenkins构建找不到python依赖
最近在搞jenkins自动构建,遇到这样一个问题,我装的python相关的依赖在X用户下,但是jenkins在root下运行的,所以找不到相关的import 1. 执行pip freeze,会打印相关 ...
- Mac使用iTerm2 一键免密登录
iTerm是mac平台很好用的ssh管理工具,今天给大家介绍一种使用iTerm一键登陆服务器优雅的方式,这样就不需要每次连接服务器时都需要输入端口号.用户名.ip地址.密码(为了安全,服务器密码都好长 ...
- cookies和sessions组件
目录 cookie与session cookie介绍 session介绍 token django操作cookie 设置cookie 获取cookie 删除cookie 基于cookie实现的登录认证 ...
- Linux—chattr 命令详解
chattr命令的用法:chattr [ -RV ] [ -v version ] [ mode ] files…最关键的是[mode]部分,[mode]部分是由+-=和[ASacDdIijsTtu] ...
- Scrapy的Spider类和CrawlSpider类
Scrapy shell 用来调试Scrapy 项目代码的 命令行工具,启动的时候预定义了Scrapy的一些对象 设置 shell Scrapy 的shell是基于运行环境中的python 解释器sh ...