Scrapy的Spider类和CrawlSpider类
Scrapy shell
用来调试Scrapy 项目代码的 命令行工具,启动的时候预定义了Scrapy的一些对象
设置 shell
Scrapy 的shell是基于运行环境中的python 解释器shell
本质上就是通过命令调用shell,并在启动的时候预定义需要使用的对象
scrapy允许通过在项目配置文件”scrapy.cfg”中进行配置来指定解释器shell,例如:
[settings]
shell = ipython
启动 shell
启动Scrapy shell的命令语法格式:scrapy shell [option] [url|file]
url 就是你想要爬取的网址,分析本地文件时一定要带上路径,scrapy shell默认当作url
Spider类
运行流程
首先生成初始请求以爬取第一个URL,并指定要使用从这些请求下载的响应调用的回调函数
在回调函数中,解析响应(网页)并返回,Item对象、Request对象或这些对象的可迭代的dicts
最后,从蜘蛛返回的项目通常会持久保存到数据库(在某些项目管道中)或导出写入文件
属性

name: spider的名称、必须是唯一的
start_urls: 起始urls、初始的Request请求来源
customer_settings: 自定义设置、运行此蜘蛛时将覆盖项目范围的设置。必须将其定义为类属性,因为在实例化之前更新了设置
logger: 使用Spider创建的Python日志器
方法
from_crawler:创建spider的类方法
start_requests:开始请求、生成request交给引擎下载返回response
parse:默认的回调方法,在子类中必须要重写
close:spider关闭时调用
CrawlSpider类
Spider类 是匹配url,然后返回request请求
CrawlSpider类 根据url规则,自动生成request请求
创建CrawlSpider类爬虫文件
crapy genspider -t crawl 爬虫名 域名
LinkExtractor参数

allow:正则表达式,满足的url会被提取出来
deny:正则表达式,满足的url不会被提取出来
estrict_xpaths:路径表达式,符合路径的标签提取出来
Rule参数

linkextractor:提取链接的实例对象
callback:回调函数
follow:指定是否应该从使用此规则提取的每个响应中跟踪链接
process_links:用于过滤连接的回调函数
process_request:用于过滤请求的回调函数
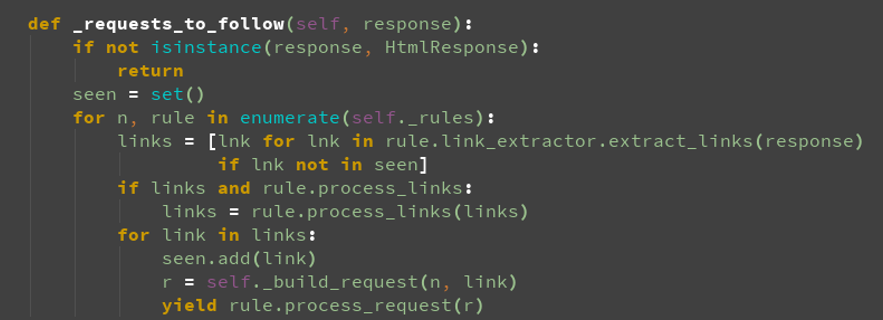
url去重
Scrapy的Spider类和CrawlSpider类的更多相关文章
- Scrapy框架——CrawlSpider类爬虫案例
Scrapy--CrawlSpider Scrapy框架中分两类爬虫,Spider类和CrawlSpider类. 此案例采用的是CrawlSpider类实现爬虫. 它是Spider的派生类,Spide ...
- 13.CrawlSpider类爬虫
1.CrawlSpider介绍 Scrapy框架中分两类爬虫,Spider类和CrawlSpider类. 此案例采用的是CrawlSpider类实现爬虫. 它是Spider的派生类,Spider类的设 ...
- python爬虫入门(八)Scrapy框架之CrawlSpider类
CrawlSpider类 通过下面的命令可以快速创建 CrawlSpider模板 的代码: scrapy genspider -t crawl tencent tencent.com CrawSpid ...
- scrapy的CrawlSpider类
了解CrawlSpider 踏实爬取一般网站的常用spider,其中定义了一些规则(rule)来提供跟进link的方便机制,也许该spider不适合你的目标网站,但是对于大多数情况是可以使用的.因此, ...
- scrapy项目4:爬取当当网中机器学习的数据及价格(CrawlSpider类)
scrapy项目3中已经对网页规律作出解析,这里用crawlspider类对其内容进行爬取: 项目结构与项目3中相同如下图,唯一不同的为book.py文件 crawlspider类的爬虫文件book的 ...
- scrapy系列(四)——CrawlSpider解析
CrawlSpider也继承自Spider,所以具备它的所有特性,这些特性上章已经讲过了,就再在赘述了,这章就讲点它本身所独有的. 参与过网站后台开发的应该会知道,网站的url都是有一定规则的.像dj ...
- Scrapy(五):CrawlSpider的使用
Scrapy(五):CrawlSpider的使用 说明 :CrawlSpider,就是一个类,是Spider的一个子类,也是一个官方类,因为是子类,所以功能更加的强大,多了一项功能:去指定的页面中来抓 ...
- 爬虫07 /scrapy图片爬取、中间件、selenium在scrapy中的应用、CrawlSpider、分布式、增量式
爬虫07 /scrapy图片爬取.中间件.selenium在scrapy中的应用.CrawlSpider.分布式.增量式 目录 爬虫07 /scrapy图片爬取.中间件.selenium在scrapy ...
- Scrapy框架-Spider
目录 1. Spider 2.Scrapy源代码 2.1. Scrapy主要属性和方法 3.parse()方法的工作机制 1. Spider Spider类定义了如何爬取某个(或某些)网站.包括了爬取 ...
随机推荐
- 推荐一种非常好的新版DSP库源码移植方式,含V7,V6和V5的IAR以及MDK5的AC5和AC6版本
说明: 1.新版CMSIS V5.6里面的DSP库比以前的版本人性化了好多. 2.本帖为大家分享一种源码的添加方式,之前一直是用的库方便,不方便查看源码部分. 3.DSP教程可以还看第1版的,在我们的 ...
- Java 程序员最喜欢使用的日常工具
多年来,Java 始终是企业应用程序的支柱.最近几年,Java 也是 Android 开发的首选编程语言.不过开发人员如何使用这种语言呢?一项新的研究阐明了主要使用 Java 的开发人员的工作类型,以 ...
- mybatis中 == 和 != 的用法
!= 的用法 <if test="xxx != null and xxx !=''"> == 的用法(相较于!=,仅需将双引号和单引号的位置换一下即可) <if ...
- IDEA去除掉虚线,波浪线,和下划线实线的方法
初次安装使用IDEA,总是能看到导入代码后,出现很多的波浪线,下划线和虚线,这是IDEA给我们的一些提示和警告,但是有时候我们并不需要,反而会让人看着很不爽,这里简单记录一下自己的调整方法,供其他的小 ...
- MySQL Aborted_clients和 Aborted_connects状态变量详解
Aborted_clients和 Aborted_connects状态变量详解 By:授客 QQ:1033553122 状态变量定义 Aborted_clients 因客户端消亡时未恰当的关闭连接 ...
- python 基础学习笔记(4)--字典 和 集合
**字典:** - [ ] 列表可以存储大量的数据,但是如果数据量大的话,他的查询速度比较慢,因为列表只能顺序存储,数据与数据之间的关联性不强.所以便有了字典(dict)这种容器的数据类型,它是以{} ...
- 12C-使用跨平台增量备份减少可移动表空间的停机时间 (Doc ID 2005729.1)
12C - Reduce Transportable Tablespace Downtime using Cross Platform Incremental Backup (Doc ID 20057 ...
- [Go]TCP服务中读写进行协程分离
读写两部分进行一下分离,中间通过chan进行传递数据 ,这样可以方便的在write中进行一些业务处理 single/snet/tcpconn.go package snet import ( &quo ...
- day98_12_2 数据分析工具包。
1.numpy 在python中,数据分析可以使用numpy. 首先可以安装ipython解释器,在终端,代码变得可视化,界面有高亮显示: pip Install ipython 除了可以在终端编程之 ...
- poi创建excel文件
package com.mozq.sb.file01.test; import org.apache.poi.hssf.usermodel.*; import org.apache.poi.hssf. ...