python爬虫——爬取B站用户在线人数
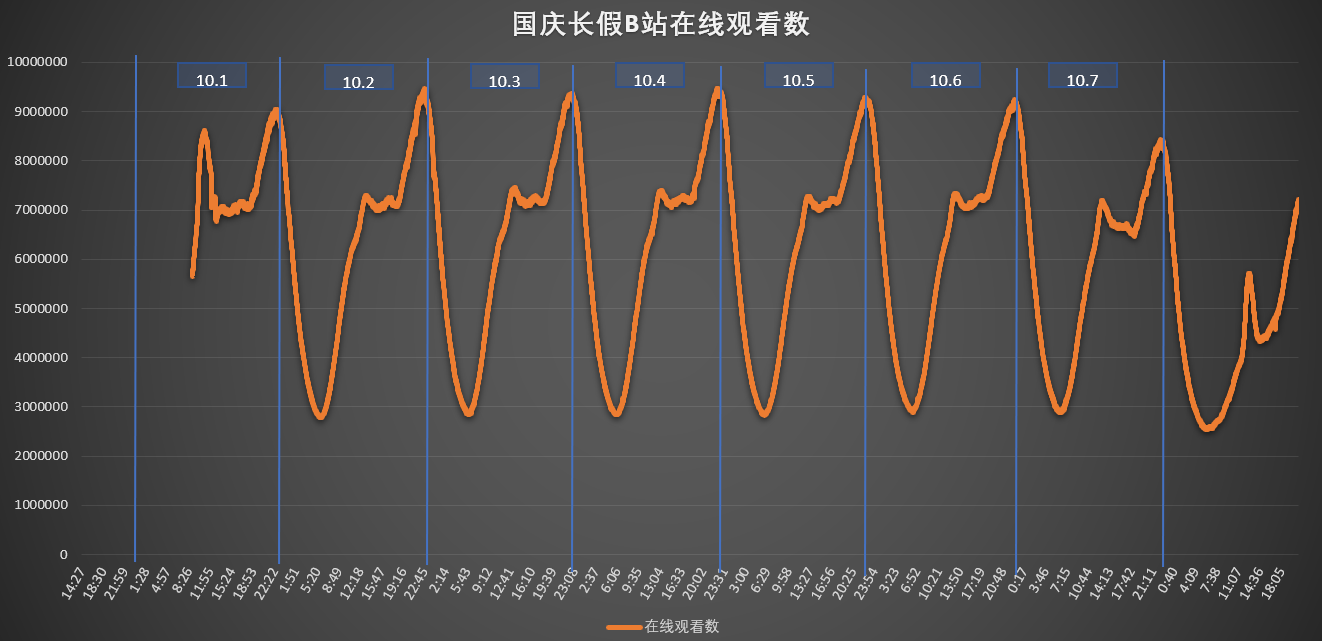
国庆期间想要统计一下bilibili网站的在线人数变化,写了一个简单的爬虫程序。主要是对https://api.bilibili.com/x/web-interface/online返回的参数进行分析,获取在线人数对应位置。程序关键点在于requests模块的使用。
具体步骤
1、网页中寻找数据元素对应接口
2、设置代理库
3、请求接口,json读取数据,获得当前在线人数
4、10次求平均
5、配置定时任务,每分钟执行一次
6、excel导出图表
最终结果

# !/usr/bin/env python3
# -*- coding: utf-8 -*- import requests
import random
import json
import time # ---------------------------------------------------------------------------------------
# 计算时间差,格式: 时分秒
def gettimediff(start, end):
seconds = (end - start).seconds
m, s = divmod(seconds, 60)
h, m = divmod(m, 60)
diff = ("%02d:%02d:%02d" % (h, m, s))
return diff # ----------------------------------------------------------------------------------------------------------------------
# 返回一个随机的请求头 headers
def getheaders():
user_agent_list = [ \
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1" \
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11", \
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6", \
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6", \
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1", \
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5", \
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5", \
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", \
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", \
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3", \
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24", \
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
UserAgent = random.choice(user_agent_list)
headers = {'User-Agent': UserAgent}
return headers # -----------------------------------------------------检查ip是否可用---------------------
def checkip(targeturl, ip):
headers = getheaders() # 定制请求头
proxies = {ip.split(':')[0]: ip} # 代理ip
try:
response = requests.get(url=targeturl, proxies=proxies, headers=headers, timeout=5).status_code
if response == 200:
return True
else:
return False
except:
return False # -------------------------------------------------------获取代理方法----------------------
def findip(): # ip类型,页码,目标url,存放ip的路径
url = 'https://api.bilibili.com/x/web-interface/online' # 配置url
headers = getheaders() # 定制请求头
callback = requests.get(url=url, headers=headers, timeout=10).text
data_json = json.loads(callback) # json格式读取返回值
web_online = data_json['data']['web_online'] # 获取在线人数
play_online = data_json['data']['play_online']
all_count = data_json['data']['all_count']
return web_online, play_online, all_count if __name__ == "__main__":
num_sum = 0
play_sum = 0
count_sum = 0
time_now = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time())) # 获取当前时间,格式%Y-%m-%d %H:%M:%S
for i in range(10): # 统计十次数据,求平均
num_sum = num_sum + findip()[0]
play_sum = play_sum + findip()[1]
count_sum = count_sum + findip()[2]
time.sleep(1)
num = num_sum / 10
play_online = play_sum / 10
count = count_sum / 10
with open('online_num.csv', 'a') as f: # 写入文件数据
f.write('%s,%s,%s,%s\n' % (time_now, num, play_online, count))
f.close()
python爬虫——爬取B站用户在线人数的更多相关文章
- 用Python爬虫爬取广州大学教务系统的成绩(内网访问)
用Python爬虫爬取广州大学教务系统的成绩(内网访问) 在进行爬取前,首先要了解: 1.什么是CSS选择器? 每一条css样式定义由两部分组成,形式如下: [code] 选择器{样式} [/code ...
- Python爬虫|爬取喜马拉雅音频
"GOOD Python爬虫|爬取喜马拉雅音频 喜马拉雅是知名的专业的音频分享平台,用户规模突破4.8亿,汇集了有声小说,有声读物,儿童睡前故事,相声小品等数亿条音频,成为国内发展最快.规模 ...
- 爬虫---爬取b站小视频
前面通过python爬虫爬取过图片,文字,今天我们一起爬取下b站的小视频,其实呢,测试过程中需要用到视频文件,找了几个网站下载,都需要会员什么的,直接写一篇爬虫爬取视频~~~ 分析b站小视频 1.进入 ...
- 一个简单的python爬虫,爬取知乎
一个简单的python爬虫,爬取知乎 主要实现 爬取一个收藏夹 里 所有问题答案下的 图片 文字信息暂未收录,可自行实现,比图片更简单 具体代码里有详细注释,请自行阅读 项目源码: # -*- cod ...
- Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理 源代码如下: # 改进版, 增加了 .strip()方法的使用 # coding=utf-8 ...
- 使用Python爬虫爬取网络美女图片
代码地址如下:http://www.demodashi.com/demo/13500.html 准备工作 安装python3.6 略 安装requests库(用于请求静态页面) pip install ...
- python爬虫爬取内容中,-xa0,-u3000的含义
python爬虫爬取内容中,-xa0,-u3000的含义 - CSDN博客 https://blog.csdn.net/aiwuzhi12/article/details/54866310
- Python爬虫爬取全书网小说,程序源码+程序详细分析
Python爬虫爬取全书网小说教程 第一步:打开谷歌浏览器,搜索全书网,然后再点击你想下载的小说,进入图一页面后点击F12选择Network,如果没有内容按F5刷新一下 点击Network之后出现如下 ...
- python爬虫—爬取英文名以及正则表达式的介绍
python爬虫—爬取英文名以及正则表达式的介绍 爬取英文名: 一. 爬虫模块详细设计 (1)整体思路 对于本次爬取英文名数据的爬虫实现,我的思路是先将A-Z所有英文名的连接爬取出来,保存在一个cs ...
随机推荐
- HDU2874 Connections between cities 最近公共祖先
第一次按常规的方法求,将所有的查询的u,v,和最近公共祖先都保存起来,然后用tarjan+并查集求最近公共祖先.因为询问的次数过多,所以在保存查询的时候总是MLE,后来参考了一下别人的代码,才突然觉悟 ...
- 基于servlet的图书管理系统
该项目是Java语言开发的图书管理系统,IDE采用eclipse,技术采用servlet,数据库使用mysql,前端页面采用bootstrap框架,简介美观. 系统具备基础的功能,读者可以注册登录,登 ...
- MYSQL之B+TREE索引原理
1.什么是索引? 索引:加速查询的数据结构. 2.索引常见数据结构 顺序查找: 最基本的查询算法-复杂度O(n),大数据量此算法效率糟糕. 二叉树查找:(binary tree search): O( ...
- 使用VUE实现在table中文字信息超过5个隐藏,鼠标移到时弹窗显示全部
使用VUE实现在table中文字信息超过5个隐藏,鼠标移到时弹窗显示全部 <template> <div> <table> <tr v-for="i ...
- Python函数编程——闭包和装饰器
Python函数编程--闭包和装饰器 一.闭包 关于闭包,即函数定义和函数表达式位于另一个函数的函数体内(嵌套函数).而且,这些内部函数可以访问它们所在的外部函数中声明的所有局部变量.参数.当其中一个 ...
- FreeSql (五)插入数据
var connstr = "Data Source=127.0.0.1;Port=3306;User ID=root;Password=root;" + "Initia ...
- UGUI_游戏界面开发Demo001
1.Alt+Stretch:快速拉伸匹配至画布,与父类大小保持一致. 2.Anchors锚点:实现屏幕自适应 图片也可以实现自适应.Target Graphic (目标图),点击的时候,控件的效果用在 ...
- java PDF转word的初步实现
package com.springboot.springboot.util; import java.io.File; import java.io.FileOutputStream; import ...
- jvm内存溢出问题的定位方法
jvm内存溢出问题的定位方法 今天给大家带来JVM体验之内存溢出问题的定位方法. 废话不多说直接开始: 一.Java堆溢出 测试代码如下: import java.util.*; public cla ...
- Ubuntu 14.04 java环境安装配置(不是openJAVA)
两种配置方式 第一: 在 Ubuntu 中使用 PPA 安装 Java 8 ( 支持 Ubuntu 10.04 - Ubuntu 14.04 ): sudo add-apt-repository pp ...