[Hadoop]HDFS机架感知策略
HDFS NameNode对文件块复制相关所有事物负责,它周期性接受来自于DataNode的HeartBeat和BlockReport信息,HDFS文件块副本的放置对于系统整体的可靠性和性能有关键性影响。
一个简单但非优化的副本放置策略是,把副本分别放在不同机架,甚至不同IDC。这样可以防止整个机架、甚至整个IDC崩溃带来的错误,但是这样文件写必须在多个机架之间、甚至IDC之间传输,增加了副本写的代价。
在缺省配置下副本数是3个,通常的策略是:第一个副本放在和Client相同机架的Node里(如果Client不在集群范围,第一个Node是随机选取不太满或者不太忙的Node);第二个副本放在与第一个Node不同的机架中的Node;第三个副本放在与第二个Node所在机架里不同的Node。
Hadoop的副本放置策略在可靠性(副本在不同机架)和带宽(只需跨越一个机架)中做了一个很好的平衡。
但是,HDFS如何知道各个DataNode的网络拓扑情况呢?它的机架感知功能需要 topology.script.file.name 属性定义的可执行文件(或者脚本)来实现,文件提供了NodeIP对应RackID的翻译。如果 topology.script.file.name 没有设定,则每个IP都会翻译成/default-rack。
默认情况下,Hadoop机架感知是没有启用的,需要在NameNode机器的hadoop-site.xml里配置一个选项,例如:
<property>
<name>topology.script.file.name</name>
<value>/path/to/script</value>
</property>
这个配置选项的value指定为一个可执行程序,通常为一个脚本,该脚本接受一个参数,输出一个值。接受的参数通常为datanode机器的ip地址,而输出的值通常为该ip地址对应的datanode所在的rackID,例如”/rack1”。Namenode启动时,会判断该配置选项是否为空,如果非空,则表示已经启用机架感知的配置,此时namenode会根据配置寻找该脚本,并在接收到每一个datanode的heartbeat时,将该datanode的ip地址作为参数传给该脚本运行,并将得到的输出作为该datanode所属的机架,保存到内存的一个map中。
至于脚本的编写,就需要将真实的网络拓朴和机架信息了解清楚后,通过该脚本能够将机器的ip地址正确的映射到相应的机架上去。Hadoop官方给出的脚本:http://wiki.apache.org/hadoop/topology_rack_awareness_scripts
以下分别是没有配置机架感知信息和配置机架感知信息的hadoop HDFS进行数据上传时的测试结果。
当没有配置机架信息时,所有的机器hadoop都默认在同一个默认的机架下,名为 “/default-rack”,这种情况下,任何一台datanode机器,不管物理上是否属于同一个机架,都会被认为是在同一个机架下,此时,就很容易出现之前提到的增添机架间网络负载的情况。在没有机架信息的情况下,namenode默认将所有的slaves机器全部默认为在/default-rack下,此时写block时,三个datanode机器的选择完全是随机的。
当配置了机架感知信息以后,hadoop在选择三个datanode时,就会进行相应的判断:
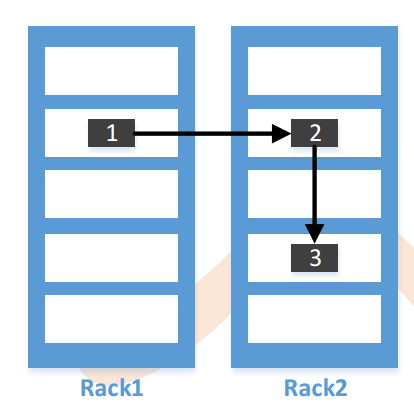
1. 如果上传本机不是一个datanode,而是一个客户端,那么就从所有slave机器中随机选择一台datanode作为第一个块的写入机器(datanode1)。而此时如果上传机器本身就是一个datanode,那么就将该datanode本身作为第一个块写入机器(datanode1)。
2. 随后在datanode1所属的机架以外的另外的机架上,随机的选择一台,作为第二个block的写入datanode机器(datanode2)。
3. 在写第三个block前,先判断是否前两个datanode是否是在同一个机架上,如果是在同一个机架,那么就尝试在另外一个机架上选择第三个datanode作为写入机器(datanode3)。而如果datanode1和datanode2没有在同一个机架上,则在datanode2所在的机架上选择一台datanode作为datanode3。
4. 得到3个datanode的列表以后,从namenode返回该列表到DFSClient之前,会在namenode端首先根据该写入客户端跟datanode列表中每个datanode之间的“距离”由近到远进行一个排序,客户端根据这个顺序有近到远的进行数据块的写入。
5. 当根据“距离”排好序的datanode节点列表返回给DFSClient以后,DFSClient便会创建Block OutputStream,并向这次block写入pipeline中的第一个节点(最近的节点)开始写入block数据。
6. 写完第一个block以后,依次按照datanode列表中的次远的node进行写入,直到最后一个block写入成功,DFSClient返回成功,该block写入操作结束。
通过以上策略,namenode在选择数据块的写入datanode列表时,就充分考虑到了将block副本分散在不同机架下,并同时尽量地避免了之前描述的网络开销。
作者:GodHehe
链接:https://www.jianshu.com/p/372d25352d3a
[Hadoop]HDFS机架感知策略的更多相关文章
- 我要进大厂之大数据Hadoop HDFS知识点(2)
01 我们一起学大数据 老刘继续分享出Hadoop中的HDFS模块的一些高级知识点,也算是对今天复习的HDFS内容进行一次总结,希望能够给想学大数据的同学一点帮助,也希望能够得到大佬们的批评和指点! ...
- Hadoop HDFS 用户指南
This document is a starting point for users working with Hadoop Distributed File System (HDFS) eithe ...
- Hadoop HDFS负载均衡
Hadoop HDFS负载均衡 转载请注明出处:http://www.cnblogs.com/BYRans/ Hadoop HDFS Hadoop 分布式文件系统(Hadoop Distributed ...
- HDFS机架感知功能原理(rack awareness)
转自:http://www.jianshu.com/p/372d25352d3a HDFS NameNode对文件块复制相关所有事物负责,它周期性接受来自于DataNode的HeartBeat和Blo ...
- Hadoop HDFS分布式文件系统设计要点与架构
Hadoop HDFS分布式文件系统设计要点与架构 Hadoop简介:一个分布式系统基础架构,由Apache基金会开发.用户可以在不了解分布式底层细节的情况下,开发分布式程序.充分利用集群 ...
- [HDFS_add_3] HDFS 机架感知
0. 说明 HDFS 副本存放策略 && 配置机架感知 1. HDFS 的副本存放策略 HDFS 的副本存放策略是将一个副本存放在本地机架节点上,另外两个副本放在不同机架的不同节点上 ...
- hdfs 机架感知
一.背景 分布式的集群通常包含非常多的机器,由于受到机架槽位和交换机网口的限制,通常大型的分布式集群都会跨好几个机架,由多个机架上的机器共同组成一个分布式集群.机架内的机器之间的网络速度通常都会高 ...
- 深入理解hadoop之机架感知
深入理解hadoop之机架感知 机架感知 hadoop的replication为3,机架感知的策略为: 第一个block副本放在和client所在的datanode里(如果client不在集群范围内, ...
- HDFS机架感知
Hadoop版本:2.9.2 什么是机架感知 通常大型 Hadoop 集群是以机架的形式来组织的,同一个机架上的不同节点间的网络状况比不同机架之间的更为理想,NameNode 设法将数据块副本保存在不 ...
随机推荐
- window连接远程服务器报函数不支持之解决方案
1.针对window10系统 Windows+R,输入cmd,输入gpedit.msc 然后就可以启动远程连接了 2.针对window7用户 没有上述的第一个操作选项 1. 打开注册表,快捷输入 “r ...
- ELK 学习笔记之 elasticsearch基本概念和CRUD
elasticsearch基本概念和CRUD: 基本概念: CRUD: 创建索引: curl -XPUT 'http://192.168.1.151:9200/library/' -d '{" ...
- 【原创】go语言学习(二)数据类型、变量量、常量量
目录 1.标识符.关键字2. 变量量和常量量3. 数据类型4. Go程序基本结构 标识符.关键字 1.标识符是⽤用来表示Go中的变量量名或者函数名,以字⺟母或_开头.后⾯面跟着字⺟母 ._或数字2. ...
- UE制作PBR材质攻略Part 1 - 色彩知识
目录 一.前言 二.色彩知识 2.1 色彩理论 2.1.1 成像原理 2.1.2 色彩模型和色彩空间 2.1.3 色彩属性 2.1.4 直方图 2.1.5 色调曲线 2.1.6 线性空间与Gamma空 ...
- 两句话掌握python最难知识点——元类
千万不要被所谓“元类是99%的python程序员不会用到的特性”这类的说辞吓住.因为每个中国人,都是天生的元类使用者 学懂元类,你只需要知道两句话: 道生一,一生二,二生三,三生万物 我是谁?我从哪来 ...
- 04-02 AdaBoost算法
目录 AdaBoost算法 一.AdaBoost算法学习目标 二.AdaBoost算法详解 2.1 Boosting算法回顾 2.2 AdaBoost算法 2.3 AdaBoost算法目标函数优化 三 ...
- 理解numpy.dot()
import numpy.matlib import numpy as np a = np.array([[1,2],[3,4]]) b = np.array([[11,12],[13,14]]) p ...
- 手把手教你吧Python应用到实际开发 不再空谈悟法☝☝☝
手把手教你吧Python应用到实际开发 不再空谈悟法☝☝☝ 想用python做机器学习吗,是不是在为从哪开始挠头?这里我假定你是新手,这篇文章里咱们一起用Python完成第一个机器学习项目.我会手把手 ...
- Qt5教程: (3) 自定义信号与槽
1. 自定义槽 槽可以是任何成员函数.普通全局函数.静态函数 槽函数和信号的参数和返回值要一致 由于信号是没有返回值的, 槽函数也一定没有返回值 首先在mainwidget.h中添加槽函数: publ ...
- ASP.NET Core在 .NET Core 3.1 Preview 1中的更新
.NET Core 3.1 Preview 1现在可用.此版本主要侧重于错误修复,但同时也包含一些新功能. 这是此版本的ASP.NET Core的新增功能: 对Razor components的部分类 ...