利用scrapy-client 发布爬虫到远程服务端
远程服务端Scrapyd先要开启
远程服务器必须装有scapyd,并开启。
这里远程服务开启的端口和ip:
192.166.12.80:6800
客户端配置和上传
先修爬虫项目文件scrapy.cfg:如下图
cd 到爬虫项目文件夹下,后执行:
scrapyd-deploy # 上传
scrapyd-deploy -l # 查看

打包项目
1、打包前先查看项目下的爬虫文件:

说明可以开始打包了
2.执行打包命令:
scrapyd-deploy 部署名称 -p 项目名称

上面表示打包成功。
以下是可能出现的问题,以及解决方案:
如果出现后端报错和scrapyd前端页面报错,解决方案:
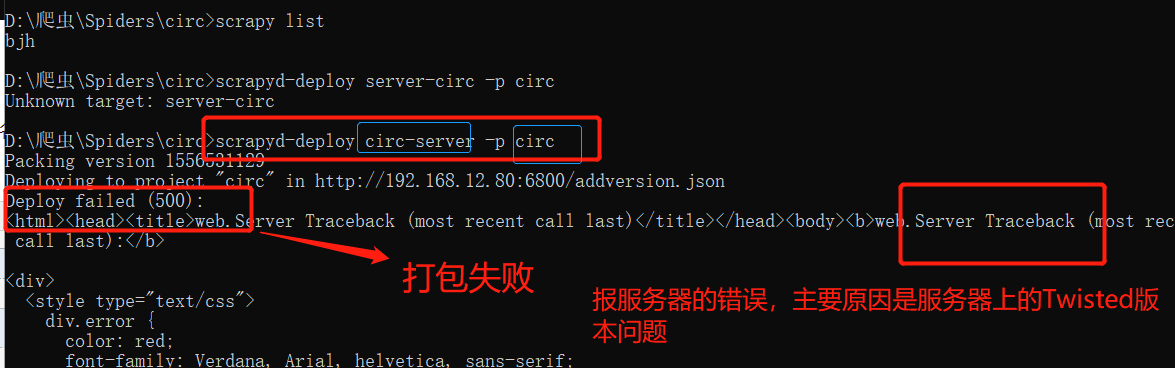
scrapyd 前端报错:

修改远程服务器(192.168.12.80)上的Twisted的版本改为 18.9.0
pip3 install Twisted==18.9.0

重启 Scrapyd:

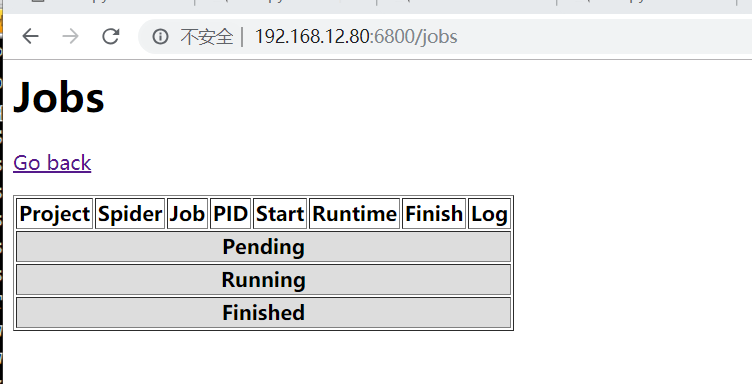
在访问192.168.12.80:6800/jobs,正常显示:
3.上传运行爬虫
curl http://远程ip:6800/schedule.json -d project=项目名称 -d spider=爬虫名称
如:
curl http://192.168.12.80:6800/schedule.json -d project=circ -d spider=bjh

说明部署成功:
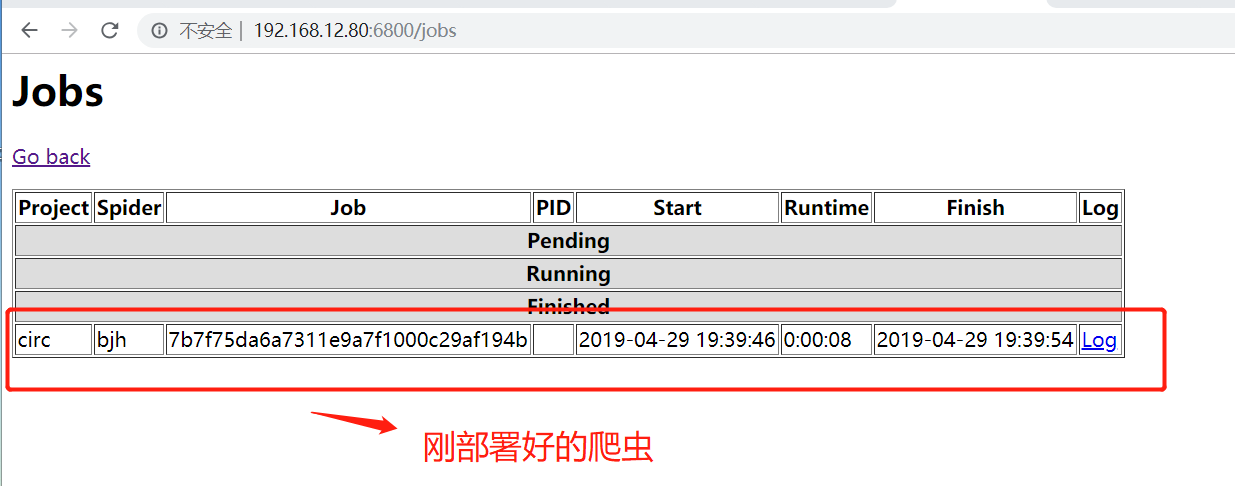
scrapyd部署已经完成了。
管理
1、停止爬虫
curl http://localhost:6800/cancel.json -d project=scrapy项目名称 -d job=运行ID
2.删除scrapy项目
注意:一般删除scrapy项目,需要先执行命令停止项目下在远行的爬虫
curl http://localhost:6800/delproject.json -d project=scrapy项目名称
3.查看有多少个scrapy项目在api中
curl http://localhost:6800/listprojects.json
4.查看指定的scrapy项目中有多少个爬虫
curl http://localhost:6800/listspiders.json?project=scrapy项目名称
5总结几个请求url,通过在浏览器输入,也可以监控爬虫进程。
例子:地址栏访问 :http://192.168.12.80:6800/daemonstatus.json,获取到一下页面


1、获取状态
http://127.0.0.1:6800/daemonstatus.json
2、获取项目列表
http://127.0.0.1:6800/listprojects.json
3、获取项目下已发布的爬虫列表
http://127.0.0.1:6800/listspiders.json?project=myproject
4、获取项目下已发布的爬虫版本列表
http://127.0.0.1:6800/listversions.json?project=myproject
5、获取爬虫运行状态
http://127.0.0.1:6800/listjobs.json?project=myproject
6、启动服务器上某一爬虫(必须是已发布到服务器的爬虫)
http://127.0.0.1:6800/schedule.json (post方式,data={“project”:myproject,“spider”:myspider})
7、删除某一版本爬虫
http://127.0.0.1:6800/delversion.json
(post方式,data={“project”:myproject,“version”:myversion})
8、删除某一工程,包括该工程下的各版本爬虫
http://127.0.0.1:6800/delproject.json(post方式,data={“project”:myproject})
利用scrapy-client 发布爬虫到远程服务端的更多相关文章
- 利用scrapy框架进行爬虫
今天一个网友问爬虫知识,自己把许多小细节都忘了,很惭愧,所以这里写一下大概的步骤,主要是自己巩固一下知识,顺便复习一下.(scrapy框架有一个好处,就是可以爬取https的内容) [爬取的是杨子晚报 ...
- 利用scrapy和MongoDB来开发一个爬虫
今天我们利用scrapy框架来抓取Stack Overflow里面最新的问题(),并且将这些问题保存到MongoDb当中,直接提供给客户进行查询. 安装 在进行今天的任务之前我们需要安装二个框架,分别 ...
- 【爬虫】利用Scrapy抓取京东商品、豆瓣电影、技术问题
1.scrapy基本了解 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架.可以应用在包括数据挖掘, 信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取(更确切来说,网络抓 ...
- 利用scrapy爬取腾讯的招聘信息
利用scrapy框架抓取腾讯的招聘信息,爬取地址为:https://hr.tencent.com/position.php 抓取字段包括:招聘岗位,人数,工作地点,发布时间,及具体的工作要求和工作任务 ...
- Scrapy - 第一个爬虫和我的博客
第一个爬虫 这里我用官方文档的第一个例子:爬取http://quotes.toscrape.com来作为我的首个scrapy爬虫,我没有找到scrapy 1.5的中文文档,后续内容有部分是我按照官方文 ...
- Scrapy 框架,爬虫文件相关
Spiders 介绍 由一系列定义了一个网址或一组网址类如何被爬取的类组成 具体包括如何执行爬取任务并且如何从页面中提取结构化的数据. 简单来说就是帮助你爬取数据的地方 内部行为 #1.生成初始的Re ...
- python3+scrapy 趣头条爬虫实例
项目简介 爬取趣头条新闻(http://home.qutoutiao.net/pages/home.html),具体内容: 1.列表页(json):标题,简介.封面图.来源.发布时间 2.详情页(ht ...
- Scrapyd发布爬虫的工具
Scrapyd Scrapyd是部署和运行Scrapy.spider的应用程序.它使您能够使用JSON API部署(上传)您的项目并控制其spider. Scrapyd-client Scrapyd- ...
- 发布Cocos2d-x的PC端程序
发布Cocos2d-x的PC端程序 一.创建一个Release的项目 1.利用根目录下的解决方案生成Release.win32文件夹 2.新建一个cocos2d项目(比如解决方案名称MySolutio ...
随机推荐
- qt 画多边形(实现鼠标拖动节点)
---恢复内容开始--- 2018-01-06 这个小例子实现了移动鼠标,鼠标的坐标信息跟随鼠标移动,多边形的实现,鼠标点击可以拖动多边形点的位置,(其中有个问题?我在QMainWindow下,用mo ...
- 接口自动化测试持续集成--SoapUI安装
实际使用: 接口自动化测试持续集成框架:maven+SoapUI+jenkins 1.SoapUI安装文件下载5.1.2 http://pan.baidu.com/s/1c17dJLu安装步骤非常简单 ...
- CentOS 7 搭建Squid代理服务器
Squid安装 官方地址:http://www.squid-cache.org/ [root@DaMoWang ~]# -r6d8f397.tar.gz [root@DaMoWang ~]# -r6d ...
- java 访问数据库
Class.forName(“com.microsoft.sqlserver.jdbc.SQLServerDriver”);//依据不同数据库,加载不同驱动 String url = “jdbc:sq ...
- JavaFX-Stage
1.Stage类继承自Window类,继承了Window类的show()方法,Stage的close()方法实际上是调用了继承自Window类的hide()方法.另外还有Window的setOpaci ...
- 2017-2018-2 『网络对抗技术』Exp1:PC平台逆向破解 20165335
一.实验目标: 本次实践的对象是一个名为pwn1的linux可执行文件. 该程序正常执行流程是:main调用foo函数,foo函数会简单回显任何用户输入的字符串. 该程序同时包含另一个代码片段,get ...
- Atom读写MarkDown插件选择,以及墙内安装markdown-preview-enhanced,及markdown和mermaid使用教程
1.Atom自带markdown-preview 功能太少,需要大量拓展. 2.markdown-preview-plus 功能还不错,但是其中的滚动条插件markdown-scroll-sync和最 ...
- 2018-2019-2 网络对抗技术 20165316 Exp5 MSF基础应用
2018-2019-2 网络对抗技术 20165316 Exp5 MSF基础应用 目录 原理与实践说明 实践原理 实践内容概述 基础问题回答 攻击实例 主动攻击的实践 ms08_067_netapi: ...
- css3 box-flex
应用地址:http://www.jb51.net/css/467291.html box-flex是css3新添加的盒子模型属性,它的出现打破了我们经常使用的浮动布局,实现垂直等高.水平均分.按比例划 ...
- 第十七节 Cookie基础与应用
什么是cookie:其实就是页面用来保存信息:比如,自动登录.记住用户名 cookie的特性:(以域名为单位的) 同一个网站(同一个域名)中所有页面共享一套cookie 数量.大小有限,跟浏览器有关, ...