二十五 Python分布式爬虫打造搜索引擎Scrapy精讲—Requests请求和Response响应介绍
Requests请求
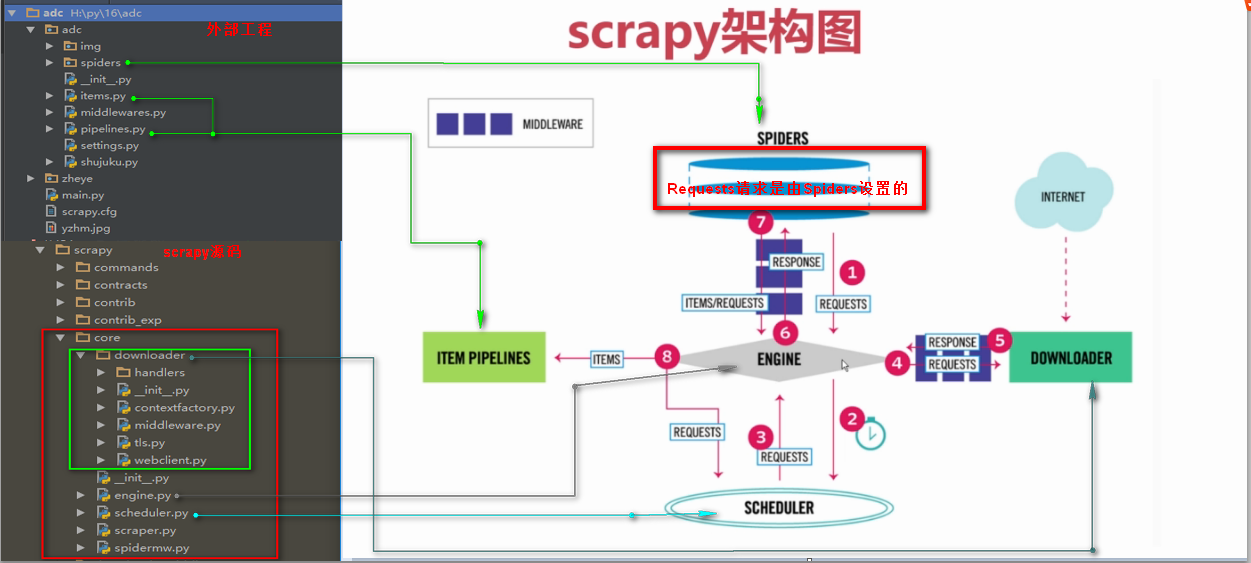
Requests请求就是我们在爬虫文件写的Requests()方法,也就是提交一个请求地址,Requests请求是我们自定义的
Requests()方法提交一个请求
参数:
url= 字符串类型url地址
callback= 回调函数名称
method= 字符串类型请求方式,如果GET,POST
headers= 字典类型的,浏览器用户代理
cookies= 设置cookies
meta= 字典类型键值对,向回调函数直接传一个指定值
encoding= 设置网页编码
priority= 默认为0,如果设置的越高,越优先调度
dont_filter= 默认为False,如果设置为真,会过滤掉当前url

# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request,FormRequest
import re class PachSpider(scrapy.Spider): #定义爬虫类,必须继承scrapy.Spider
name = 'pach' #设置爬虫名称
allowed_domains = ['www.luyin.org/'] #爬取域名
# start_urls = [''] #爬取网址,只适于不需要登录的请求,因为没法设置cookie等信息 header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:54.0) Gecko/20100101 Firefox/54.0'} #设置浏览器用户代理 def start_requests(self): #起始url函数,会替换start_urls
"""第一次请求一下登录页面,设置开启cookie使其得到cookie,设置回调函数"""
return [Request(
url='http://www.luyin.org/',
headers=self.header,
meta={'cookiejar':1}, #开启Cookies记录,将Cookies传给回调函数
callback=self.parse
)] def parse(self, response):
title = response.xpath('/html/head/title/text()').extract()
print(title)
Response响应
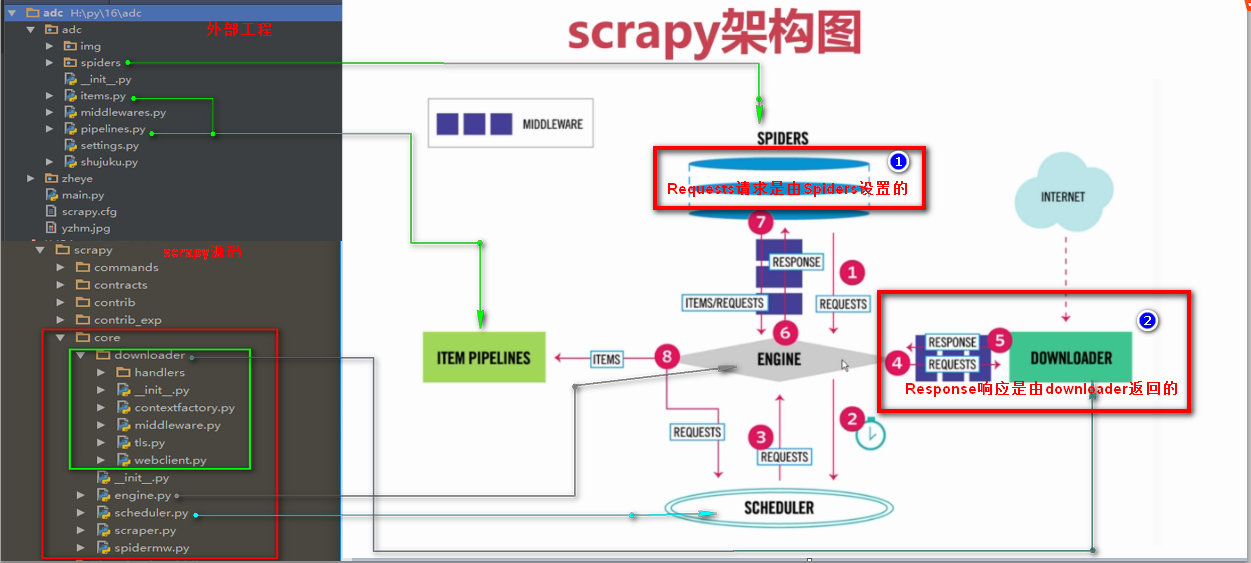
Response响应是由downloader返回的响应

Response响应参数
headers 返回响应头
status 返回状态吗
body 返回页面内容,字节类型
url 返回抓取url
# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request,FormRequest
import re class PachSpider(scrapy.Spider): #定义爬虫类,必须继承scrapy.Spider
name = 'pach' #设置爬虫名称
allowed_domains = ['www.luyin.org/'] #爬取域名
# start_urls = [''] #爬取网址,只适于不需要登录的请求,因为没法设置cookie等信息 header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:54.0) Gecko/20100101 Firefox/54.0'} #设置浏览器用户代理 def start_requests(self): #起始url函数,会替换start_urls
"""第一次请求一下登录页面,设置开启cookie使其得到cookie,设置回调函数"""
return [Request(
url='http://www.luyin.org/',
headers=self.header,
meta={'cookiejar':1}, #开启Cookies记录,将Cookies传给回调函数
callback=self.parse
)] def parse(self, response):
title = response.xpath('/html/head/title/text()').extract()
print(title)
print(response.headers)
print(response.status)
# print(response.body)
print(response.url)
二十五 Python分布式爬虫打造搜索引擎Scrapy精讲—Requests请求和Response响应介绍的更多相关文章
- 第三百四十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—Requests请求和Response响应介绍
第三百四十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—Requests请求和Response响应介绍 Requests请求 Requests请求就是我们在爬虫文件写的Requests() ...
- 二十六 Python分布式爬虫打造搜索引擎Scrapy精讲—通过downloadmiddleware中间件全局随机更换user-agent浏览器用户代理
downloadmiddleware介绍中间件是一个框架,可以连接到请求/响应处理中.这是一种很轻的.低层次的系统,可以改变Scrapy的请求和回应.也就是在Requests请求和Response响应 ...
- 三十五 Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy分布式爬虫要点
1.分布式爬虫原理 2.分布式爬虫优点 3.分布式爬虫需要解决的问题
- 二十九 Python分布式爬虫打造搜索引擎Scrapy精讲—selenium模块是一个python操作浏览器软件的一个模块,可以实现js动态网页请求
selenium模块 selenium模块为第三方模块需要安装,selenium模块是一个操作各种浏览器对应软件的api接口模块 selenium模块是一个操作各种浏览器对应软件的api接口模块,所以 ...
- 二十八 Python分布式爬虫打造搜索引擎Scrapy精讲—cookie禁用、自动限速、自定义spider的settings,对抗反爬机制
cookie禁用 就是在Scrapy的配置文件settings.py里禁用掉cookie禁用,可以防止被通过cookie禁用识别到是爬虫,注意,只适用于不需要登录的网页,cookie禁用后是无法登录的 ...
- 二十四 Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫和反爬的对抗过程以及策略—scrapy架构源码分析图
1.基本概念 2.反爬虫的目的 3.爬虫和反爬的对抗过程以及策略 scrapy架构源码分析图
- 四十五 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询
bool查询说明 filter:[],字段的过滤,不参与打分must:[],如果有多个查询,都必须满足[并且]should:[],如果有多个查询,满足一个或者多个都匹配[或者]must_not:[], ...
- 三十六 Python分布式爬虫打造搜索引擎Scrapy精讲—利用开源的scrapy-redis编写分布式爬虫代码
scrapy-redis是一个可以scrapy结合redis搭建分布式爬虫的开源模块 scrapy-redis的依赖 Python 2.7, 3.4 or 3.5,Python支持版本 Redis & ...
- 四十四 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询
1.elasticsearch(搜索引擎)的查询 elasticsearch是功能非常强大的搜索引擎,使用它的目的就是为了快速的查询到需要的数据 查询分类: 基本查询:使用elasticsearch内 ...
随机推荐
- mysql数据库从删库到跑路之mysql存储引擎
一 什么是存储引擎 mysql中建立的库===>文件夹 库中建立的表===>文件 现实生活中我们用来存储数据的文件应该有不同的类型:比如存文本用txt类型,存表格用excel,存图片用pn ...
- PATH_INFO, SCRIPT_NAME, REQUEST_URI区别示例
- Python3 安装第三方包
打开cmd(切记是cmd,不是Python3.6那个敲代码环境)输入 pip3 install numpy 即可(安装numpy包)
- 一个简单的ssm项目
准备说明jdk.tomcat.idea.mave配置请看我前两篇,这里说下mysql以及我的mysql图像化工具 数据库 项目概览 项目构建--------搭建一个简单的mave的web项目,构建步骤 ...
- TabLayout与ViewPager同步后Tab的标题不显示
一.概述 1.1 问题描述 TabLayout+ViewPager后,TabLayout的TabItem不显示的问题: 1.2 截图 二.结论 mTabs.setupWithViewPager(mVi ...
- hdu2597 Simpsons’ Hidden Talents
地址:http://acm.hdu.edu.cn/showproblem.php?pid=2594 题目: Simpsons’ Hidden Talents Time Limit: 2000/1000 ...
- json转List、Map
import java.util.ArrayList; import java.util.HashMap; import java.util.Iterator; import java.util.Li ...
- RBAC权限模型——项目实战
RBAC权限模型——项目实战
- 使用.NET Core和Vue搭建WebSocket聊天室
博客地址是:https://qinyuanpei.github.io. WebSocket是HTML5标准中的一部分,从Socket这个字眼我们就可以知道,这是一种网络通信协议.WebSocket是 ...
- 为什么gitHub提交记录显示作者名称是unknow?
unknow,为什么? gitHub上提交记录显示作者名称是unknow,刚开始没怎么管,后面遇到问题看提交记录时发现有两个unknow(一定有一个人遇到和我一样的问题了,哈哈..),于是解决一下吧. ...