四十五 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询
bool查询说明
filter:[],字段的过滤,不参与打分
must:[],如果有多个查询,都必须满足【并且】
should:[],如果有多个查询,满足一个或者多个都匹配【或者】
must_not:[],相反查询词一个都不满足的就匹配【取反,非】

# bool查询
# 老版本的filtered已经被bool替换
#用 bool 包括 must should must_not filter 来完成
#格式如下: #bool:{
# "filter":[], 字段的过滤,不参与打分
# "must":[], 如果有多个查询,都必须满足【并且】
# "should":[], 如果有多个查询,满足一个或者多个都匹配【或者】
# "must_not":[], 相反查询词一个都不满足的就匹配【取反,非】
#}
建立测试数据
#建立测试数据
POST jobbole/job/_bulk
{"index":{"_id":1}}
{"salary":10,"title":"python"}
{"index":{"_id":2}}
{"salary":20,"title":"Scrapy"}
{"index":{"_id":3}}
{"salary":30,"title":"Django"}
{"index":{"_id":4}}
{"salary":40,"title":"Elasticsearch"}
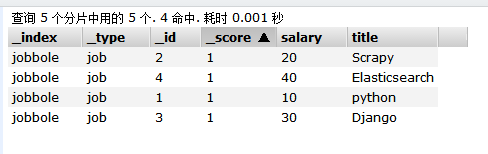
bool组合查询——最简单的filter过滤查询之term查询,相当于等于
过滤查询到salary字段等于20的数据
可以看出执行两个两个步骤,先查到所有数据,然后在查到的所有数据过滤查询到salary字段等于20的数据
# bool查询
# 老版本的filtered已经被bool替换
#用 bool 包括 must should must_not filter 来完成
#格式如下: #bool:{
# "filter":[], 字段的过滤,不参与打分
# "must":[], 如果有多个查询,都必须满足
# "should":[], 如果有多个查询,满足一个或者多个都匹配
# "must_not":[], 相反查询词一个都不满足的就匹配
#} #简单过滤查询
#最简单的filter过滤查询
#如果我们要查salary字段等于20的数据
GET jobbole/job/_search
{
"query": {
"bool": { #bool组合查询
"must":{ #如果有多个查询词,都必须满足
"match_all":{} #查询所有字段
},
"filter": { #filter过滤
"term": { #term查询,不会将我们的搜索词进行分词,将搜索词完全匹配的查询
"salary": 20 #查询salary字段值为20
}
}
}
}
} #简单过滤查询
#最简单的filter过滤查询
#如果我们要查salary字段等于20的数据
GET jobbole/job/_search
{
"query": {
"bool": {
"must":{
"match_all":{}
},
"filter": {
"term": {
"salary": 20
}
}
}
}
}

bool组合查询——最简单的filter过滤查询之terms查询,相当于或
过滤查询到salary字段等于10或20的数据
# bool查询
# 老版本的filtered已经被bool替换
#用 bool 包括 must should must_not filter 来完成
#格式如下: #bool:{
# "filter":[], 字段的过滤,不参与打分
# "must":[], 如果有多个查询,都必须满足
# "should":[], 如果有多个查询,满足一个或者多个都匹配
# "must_not":[], 相反查询词一个都不满足的就匹配
#} #简单过滤查询
#最简单的filter过滤查询
#如果我们要查salary字段等于20的数据
#过滤salary字段值为10或者20的数据
GET jobbole/job/_search
{
"query": {
"bool": {
"must":{
"match_all":{}
},
"filter": {
"terms": {
"salary":[10,20]
}
}
}
}
}
注意:filter过滤里也可以用其他基本查询的
_analyze测试查看分词器解析的结果
analyzer设置分词器类型ik_max_word精细化分词,ik_smart非精细化分词
text设置词
#_analyze测试查看分词器解析的结果
#analyzer设置分词器类型ik_max_word精细化分词,ik_smart非精细化分词
#text设置词
GET _analyze
{
"analyzer": "ik_max_word",
"text": "Python网络开发工程师"
} GET _analyze
{
"analyzer": "ik_smart",
"text": "Python网络开发工程师"
}

bool组合查询——组合复杂查询1
查询salary字段等于20或者title字段等于python、salary字段不等于30、并且salary字段不等于10的数据
# bool查询
# 老版本的filtered已经被bool替换
#用 bool 包括 must should must_not filter 来完成
#格式如下: #bool:{
# "filter":[], 字段的过滤,不参与打分
# "must":[], 如果有多个查询,都必须满足【并且】
# "should":[], 如果有多个查询,满足一个或者多个都匹配【或者】
# "must_not":[], 相反查询词一个都不满足的就匹配【取反,非】
#} # 查询salary字段等于20或者title字段等于python、salary字段不等于30、并且salary字段不等于10的数据
GET jobbole/job/_search
{
"query": {
"bool": {
"should": [
{"term":{"salary":20}},
{"term":{"title":"python"}}
],
"must_not": [
{"term": {"salary":30}},
{"term": {"salary":10}}]
}
}
}
bool组合查询——组合复杂查询2
查询salary字段等于20或者title字段等于python、salary字段不等于30、并且salary字段不等于10的数据
# bool查询
# 老版本的filtered已经被bool替换
#用 bool 包括 must should must_not filter 来完成
#格式如下: #bool:{
# "filter":[], 字段的过滤,不参与打分
# "must":[], 如果有多个查询,都必须满足【并且】
# "should":[], 如果有多个查询,满足一个或者多个都匹配【或者】
# "must_not":[], 相反查询词一个都不满足的就匹配【取反,非】
#} # 查询title字段等于python、或者、(title字段等于elasticsearch并且salary等于30)的数据
GET jobbole/job/_search
{
"query": {
"bool": {
"should":[
{"term":{"title":"python"}},
{"bool": {
"must": [
{"term": {"title":"elasticsearch"}},
{"term":{"salary":30}}
]
}}
]
}
}
}
bool组合查询——过滤空和非空
#建立数据
POST bbole/jo/_bulk
{"index":{"_id":"1"}}
{"tags":["search"]}
{"index":{"_id":"2"}}
{"tags":["search","python"]}
{"index":{"_id":"3"}}
{"other_field":["some data"]}
{"index":{"_id":"4"}}
{"tags":null}
{"index":{"_id":"1"}}
{"tags":["search",null]}
处理null空值的方法
获取tags字段,值不为空并且值不为null的数据
# bool查询
# 老版本的filtered已经被bool替换
#用 bool 包括 must should must_not filter 来完成
#格式如下: #bool:{
# "filter":[], 字段的过滤,不参与打分
# "must":[], 如果有多个查询,都必须满足【并且】
# "should":[], 如果有多个查询,满足一个或者多个都匹配【或者】
# "must_not":[], 相反查询词一个都不满足的就匹配【取反,非】
#} #处理null空值的方法
#获取tags字段,值不为空并且值不为null的数据
GET bbole/jo/_search
{
"query": {
"bool": {
"filter": {
"exists": {
"field": "tags"
}
}
}
}
}
获取tags字段值为空或者为null的数据,如果数据没有tags字段也会获取
# bool查询
# 老版本的filtered已经被bool替换
#用 bool 包括 must should must_not filter 来完成
#格式如下: #bool:{
# "filter":[], 字段的过滤,不参与打分
# "must":[], 如果有多个查询,都必须满足【并且】
# "should":[], 如果有多个查询,满足一个或者多个都匹配【或者】
# "must_not":[], 相反查询词一个都不满足的就匹配【取反,非】
#} #获取tags字段值为空或者为null的数据,如果数据没有tags字段也会获取
GET bbole/jo/_search
{
"query": {
"bool": {
"must_not": {
"exists": {
"field": "tags"
}
}
}
}
}
四十五 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询的更多相关文章
- 第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询
第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询 1.elasticsearch(搜索引擎)的查询 elasticsearch是功能 ...
- 第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理
第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理 1.映射(mapping)介绍 映射:创建索引的时候,可以预先定义字 ...
- 第三百五十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装
第三百五十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装 elasticsearch(搜索引擎)介绍 ElasticSearch是一个基于 ...
- 五十 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门搜索
第三百七十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门 我的搜素简单实现原理我们可以用js来实现,首先用js获取到 ...
- 第三百七十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索结果分页
第三百七十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索结果分页 逻辑处理函数 计算搜索耗时 在开始搜索前:start_time ...
- 第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能
第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能 Django实现搜索功能 1.在Django配置搜索结果页的路由映 ...
- 第三百六十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询
第三百六十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询 bool查询说明 filter:[],字段的过滤,不参与打分must:[] ...
- 第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作
第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作 注意:前面讲到的各种操作都是一次http请求操作一条数据,如果想 ...
- 第三百六十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本概念
第三百六十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本概念 elasticsearch的基本概念 1.集群:一个或者多个节点组织在一起 2.节点 ...
随机推荐
- 2015-03-22——js常用的String方法
String string.charAt(pos); //返回字符串中pos位置处的字符.如果pos小于0或大于等于string.length返回空字符串.模拟实现:Function.prototy ...
- kubernetes,Docker网络相关资料链接
1.Why kubernetes not doesn't use libnetwork http://blog.kubernetes.io/2016/01/why-Kubernetes-doesnt- ...
- Python高级教程-列表生成式
List Comprehensions(列表生成式) 列表生成式,是Python内置的非常简单却强大的可以用来创建list的生成式. 例如,要生成list:[1,2,3,4,5,6,7,8,9,10] ...
- eclipse导入项目,项目名出现红叉的情况(修改版)
转至:http://blog.csdn.net/niu_hao/article/details/17440247 今天用eclipse导入同事发给我的一个项目之后,项目名称上面出现红叉,但是其他地方都 ...
- ES6简单入门
let let命令用来声明块级作用域. 以前的JavaScript只有全局作用域和函数作用域, 没有块级作用域. // 示例1: if (1) { var a = "hello"; ...
- Oracle SQL 外键测试
测试SQL 创建SQL t1为主表 t2为子表 create table t1(insert_date number,id int) create table t2(insert_d ...
- python并发编程之IO模型(Day38)
一.IO模型介绍 为了更好的学习IO模型,可以先看同步,异步,阻塞,非阻塞 http://www.cnblogs.com/linhaifeng/articles/7430066.html#_label ...
- yii2查询数据倒序显示
public function selectall(){ return $this->findBySql("SELECT * FROM article order by art_tim ...
- arcgis中给属性文件加x y坐标
两种方式: 一, 1在ArcGIS 9.2桌面软件arcview级别以上软件中,加载要添加x,y坐标的数据,打开属性表,添加X.Y字段 2 右键X字段,选择calculate geometry,如果颜 ...
- ruby underscore
“examScore".underscore : exam_score "ExamScore".underscore: exam_score