【Python】【爬虫】爬取酷狗音乐网络红歌榜
原理:我的上篇博客
import requests
import time
from bs4 import BeautifulSoup def get_html(url):
'''
获得 HTML
'''
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/53\
7.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
else:
return def get_infos(html):
'''
提取数据
'''
html = BeautifulSoup(html)
# 排名#
ranks = html.select('#rankWrap > div.pc_temp_songlist > ul > li > span.pc_temp_num')
# 歌手 + 歌名
names = html.select('#rankWrap > div.pc_temp_songlist > ul > li > a')
# 播放时间
times = html.select('#rankWrap > div.pc_temp_songlist > ul > li > span.pc_temp_tips_r > span') # 打印信息
for r,n,t in zip(ranks,names,times):
r = r.get_text().replace('\n','').replace('\t','').replace('\r','')
n = n.get_text()
t = t.get_text().replace('\n','').replace('\t','').replace('\r','')
data = {
'排名': r,
'歌名-歌手': n,
'播放时间': t
}
print(data) def main():
'''
主接口
'''
urls = ['https://www.kugou.com/yy/rank/home/{}-23784.html?from=rank'
.format(str(i)) for i in range(1, 6)]
for url in urls:
html = get_html(url)
get_infos(html)
time.sleep(1) if __name__ == '__main__':
main()
结果:
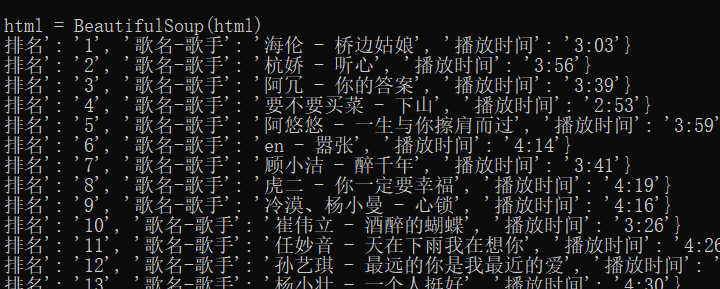
【Python】【爬虫】爬取酷狗音乐网络红歌榜的更多相关文章
- Java爬虫系列之实战:爬取酷狗音乐网 TOP500 的歌曲(附源码)
在前面分享的两篇随笔中分别介绍了HttpClient和Jsoup以及简单的代码案例: Java爬虫系列二:使用HttpClient抓取页面HTML Java爬虫系列三:使用Jsoup解析HTML 今天 ...
- python爬取酷狗音乐排行榜
本文为大家分享了python爬取酷狗音乐排行榜的具体代码,供大家参考,具体内容如下
- python使用beautifulsoup4爬取酷狗音乐
声明:本文仅为技术交流,请勿用于它处. 小编经常在网上听一些音乐但是有一些网站好多音乐都是付费下载的正好我会点爬虫技术,空闲时间写了一份,截止4月底没有问题的,会下载到当前目录,只要按照bs4库就好, ...
- python爬取酷狗音乐
url:https://www.kugou.com/yy/html/rank.html 我们随便访问一个歌曲可以看到url有个hash https://www.kugou.com/song/#hash ...
- 使用scrapy 爬取酷狗音乐歌手及歌曲名并存入mongodb中
备注还没来得及写,共爬取八千多的歌手,每名歌手平均三十首歌曲算,大概二十多万首歌曲 run.py #!/usr/bin/env python # -*- coding: utf-8 -*- __aut ...
- Python实例---爬去酷狗音乐
项目一:获取酷狗TOP 100 http://www.kugou.com/yy/rank/home/1-8888.html 排名 文件&&歌手 时长 效果: 附源码: import t ...
- python爬虫---爬取网易云音乐
代码: import requests from lxml import etree text = requests.get("https://music.163.com/discover/ ...
- 【Python】【爬虫】爬取酷狗TOP500
好啦好啦,那我们来拉开我们的爬虫之旅吧~~~ 这一只小爬虫是爬取酷狗TOP500的,使用的爬取手法简单粗暴,目的是帮大家初步窥探爬虫长啥样,后期会慢慢变得健壮起来的. 环境配置 在此之前需要下载一个谷 ...
- Python爬取酷狗飙升榜前十首(100)首,写入CSV文件
酷狗飙升榜,写入CSV文件 爬取酷狗音乐飙升榜的前十首歌名.歌手.时间,是一个很好的爬取网页内容的例子,对爬虫不熟悉的读者可以根据这个例子熟悉爬虫是如何爬取网页内容的. 需要用到的库:requests ...
随机推荐
- Android开发菜单以及子菜单
package com.example.androidtest; import android.app.Activity; import android.os.Bundle; import andro ...
- dos命令获取系统时间与变量定义
1.获取系统时间及格式化 参考文章: 1.1 cmd下获取系统时间 1.2 获取系统时间的DOS命令 2.变量定义 https://www.jb51.net/article/49197.htm 3.使 ...
- 141.内置上下文处理器debug、request、auth、messages、media、static、csrf
上下文处理器 上下文处理器可以返回一些数据,在全局模板中都可以使用,比如登录后的用户数据,在很多页面中都需要使用,那么我们就可以方在上下文处理器中,就没有必要在每个视图中返回这个对象了. 在setti ...
- (转)Android访问webservice
纠正网上乱传的android调用Webservice方法. 1.写作背景: 笔者想实现android调用webservice,可是网上全是不管对与错乱转载的文章,结果不但不能解决问题,只会让人心烦 ...
- Java中基本数据类型byte的溢出问题
Java中基本数据类型byte的溢出问题 问题源于:https://www.cnblogs.com/HuoHua2020/p/12326631.html 定义两个byte类型的数据,将其之和赋值给一个 ...
- thinkphp5.x全版本任意代码执行getshell
ThinkPHP官方2018年12月9日发布重要的安全更新,修复了一个严重的远程代码执行漏洞.该更新主要涉及一个安全更新,由于框架对控制器名没有进行足够的检测会导致在没有开启强制路由的情况下可能的ge ...
- #助力CSP2019# OI中容易出现的**错误汇总
多测不清空,爆0两行泪 3年OI一场空,不开long long见祖宗 线段树空间需要开4倍 读入有负数的时候,如果要写快读,要识别负号 持续更新
- 机器学习作业(一)线性回归——Matlab实现
题目太长啦!文档下载[传送门] 第1题 简述:设计一个5*5的单位矩阵. function A = warmUpExercise() A = []; A = eye(5); end 运行结果: 第2题 ...
- ActiveMQ的p2p模式与发布订阅模式
1.消息中间件:采用异步通讯防止,支持点对点以及发布订阅模式,可以解决高并发问题 传统调用接口,可能发生阻塞,重复提交,超时等等问题,可以利用消息中间件发送异步通讯请求 ...
- 转行小白成长路--java基础
每天都会发一篇,一点一滴,记录在这条路上的足迹.立个flag 2019年3月份至今已近一年,对信息技术有个大概的了解,个人认为对于这门技术更应该从最底层的原理入手,了解计算机演化的历史,从计算机语言到 ...