吴裕雄 python 机器学习——模型选择验证曲线validation_curve模型
import numpy as np
import matplotlib.pyplot as plt from sklearn.svm import LinearSVC
from sklearn.datasets import load_digits
from sklearn.model_selection import validation_curve #模型选择验证曲线validation_curve模型
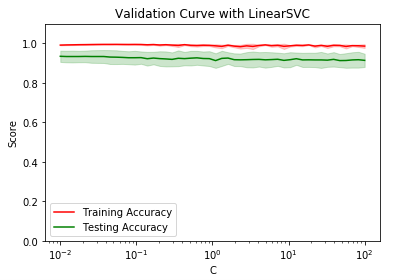
def test_validation_curve():
'''
测试 validation_curve 的用法 。验证对于 LinearSVC 分类器 , C 参数对于预测准确率的影响
'''
### 加载数据
digits = load_digits()
X,y=digits.data,digits.target
#### 获取验证曲线 ######
param_name="C"
param_range = np.logspace(-2, 2)
train_scores, test_scores = validation_curve(LinearSVC(), X, y, param_name=param_name,param_range=param_range,cv=10, scoring="accuracy")
###### 对每个 C ,获取 10 折交叉上的预测得分上的均值和方差 #####
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
####### 绘图 ######
fig=plt.figure()
ax=fig.add_subplot(1,1,1) ax.semilogx(param_range, train_scores_mean, label="Training Accuracy", color="r")
ax.fill_between(param_range, train_scores_mean - train_scores_std,train_scores_mean + train_scores_std, alpha=0.2, color="r")
ax.semilogx(param_range, test_scores_mean, label="Testing Accuracy", color="g")
ax.fill_between(param_range, test_scores_mean - test_scores_std,test_scores_mean + test_scores_std, alpha=0.2, color="g") ax.set_title("Validation Curve with LinearSVC")
ax.set_xlabel("C")
ax.set_ylabel("Score")
ax.set_ylim(0,1.1)
ax.legend(loc='best')
plt.show() #调用test_validation_curve()
test_validation_curve()
吴裕雄 python 机器学习——模型选择验证曲线validation_curve模型的更多相关文章
- 吴裕雄 python 机器学习——数据预处理包裹式特征选取模型
from sklearn.svm import LinearSVC from sklearn.datasets import load_iris from sklearn.feature_select ...
- 吴裕雄 python 机器学习——等度量映射Isomap降维模型
# -*- coding: utf-8 -*- import numpy as np import matplotlib.pyplot as plt from sklearn import datas ...
- 吴裕雄 python 机器学习——多维缩放降维MDS模型
# -*- coding: utf-8 -*- import numpy as np import matplotlib.pyplot as plt from sklearn import datas ...
- 吴裕雄 python 机器学习——多项式贝叶斯分类器MultinomialNB模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,naive_bayes from skl ...
- 吴裕雄 python 机器学习——数据预处理二元化OneHotEncoder模型
from sklearn.preprocessing import OneHotEncoder #数据预处理二元化OneHotEncoder模型 def test_OneHotEncoder(): X ...
- 吴裕雄 python 机器学习——数据预处理二元化Binarizer模型
from sklearn.preprocessing import Binarizer #数据预处理二元化Binarizer模型 def test_Binarizer(): X=[[1,2,3,4,5 ...
- 吴裕雄 python 机器学习——集成学习AdaBoost算法回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习AdaBoost算法分类模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——支持向量机SVM非线性分类SVC模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model,svm fr ...
随机推荐
- Highcharts中文帮助文档
Highcharts中文帮助文档Highcharts 简介: Highcharts 是一个制作图表的 Javascript 类库,可以制作的图表有:直线图,曲线图.区域图.区域曲线图.柱状图.饼装图. ...
- c#自带压缩类实现的多文件压缩和解压
用c#自带的System.IO.Compression命名空间下的压缩类实现的多文件压缩和解压功能,缺点是多文件压缩包的解压只能调用自身的解压方法,和现有的压缩软件不兼容.下面的代码没有把多文件的目录 ...
- FineUIPro/Mvc/Core v6.1.0 发布了!
FineUIPro/Mvc/Core v6.1.0 正式发布了(2019-12-25),这个版本主要是BUG修正,并增加了一些新特性,建议升级到此版本. 在列举新版本特性之前,我们先来回顾下每次发布大 ...
- vue图书小案例
小知识点: vue中计算属性有缓存(对象属性变化时才会更新),方法没有缓存,所以计算属性比方法效率高js中let有块级作用域,var没有块级作用域,所以var是有缺陷的this.letters[0] ...
- 本地cmd连接远程mysql数据库
一.登录远程mysql 输入mysql -h要远程的IP地址 -u设置的MySQL用户名 -p登录用户密码 例如:mysql -h 192.168.1.139 -u root -p dorlocald ...
- 文件分割合并DOS版
这个从163邮箱里翻出来的程序,2004年的修改日期,放这另存一下. 当时拿了一本C++的书来学,学了一阵就琢磨着做一个东东,然后就想起一个以前印象深刻的软件,叫做笨笨狗分割器. 当时主要还是靠3.5 ...
- ASP.NET + MVC5 入门完整教程七 -—-- MVC基本工具(上)
https://blog.csdn.net/qq_21419015/article/details/80474956 这里主要介绍三类工具之一的 依赖项注入(DI)容器,其他两类 单元测试框架和模仿工 ...
- Flink流处理(四)- 时间语义
4. 时间语义(Time Semantics) 这章我们会介绍时间语义,以及在流中,对于时间的各种不同的概念的描述.同时我们也会讨论一个流处理器在事件乱序的情况下,如何能提供精准的结果,以及如何使用流 ...
- Poj1328Radar Installation雷达安装
原题链接 经典贪心,转化为问题为,对于所有的区间,求最小的点数能使每个区间都至少有一个点. #include<iostream> #include<cstdio> #inclu ...
- 【Html】Html基本标记
<!doctype html> <html> <head> <!--mata 元信息标记--> <meta charset="utf-8 ...