MongoDB Input
Configure Connection Tab
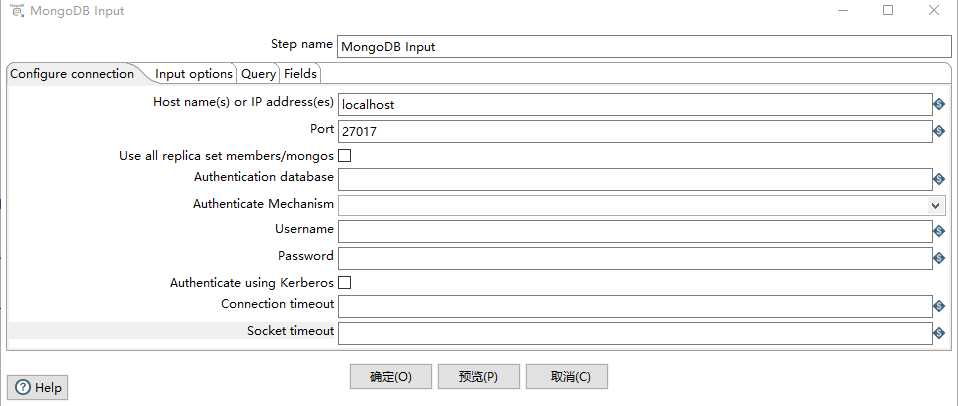
Host name(s) or IP address(es):网络名称或者地址。可以输入多个主机名或IP地址,用逗号分隔。还可以通过将主机名和端口号与冒号分隔开,为每个主机名指定不同的端口号,并将主机名和端口号的组合与逗号分隔开。例如,要为两个不同的MongoDB实例包含主机名和端口号,您将输入localhost 1:27017,localhost 2:27018,并使端口字段为空
Use all replica set members/mongos:
Port:端口号
Username:用户名
Password:密码
Authenticate using Kerberos:指示是否使用Kerberos服务来管理身份验证过程。
Connection timeout:连接超时时间(毫秒)
Socket timeout:等待写操作(以毫秒为单位)的时间
Input Options Tab
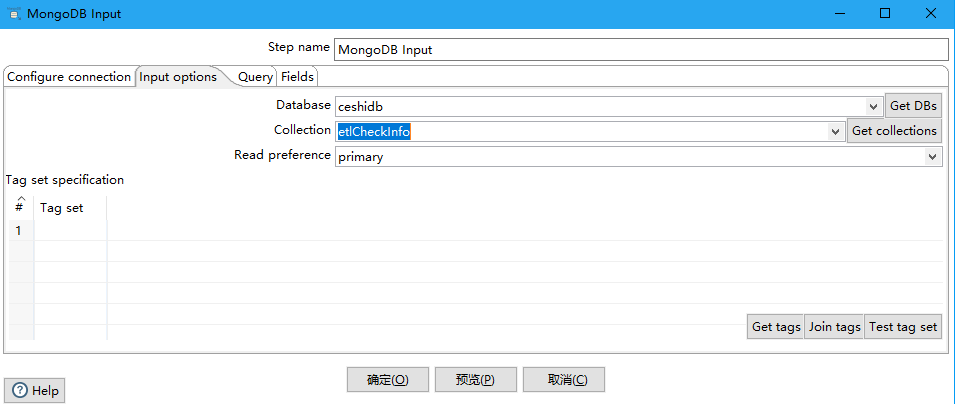
Database:检索数据的数据库的名称。单击Get DBs以在服务器上的数据库列表填充下拉菜单。
Collection:集合名称。点击 Get collections以在数据库中包含一个集合列表来填充下拉菜单
Read preference:表示要先读取哪个节点
Tag set specification/#/Tag Set:标签允许您自定义写关注和读取副本的首选项
Query Tab
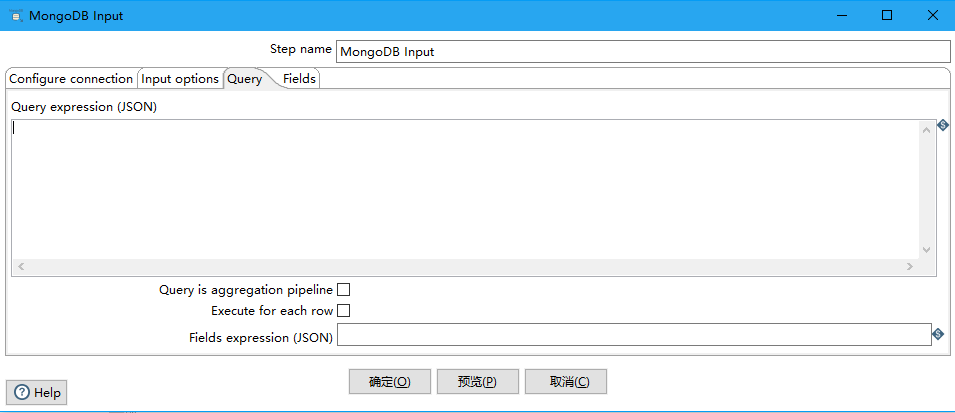
查询选项卡使您能够改进读请求。这个选项卡以两种不同的模式运行。您可以使用JSON查询表达式或使用聚合框架来创建查询。默认情况下,查询选项卡是JSON查询表达式模式。您可以输入一个JSON查询表达式。当选Query is aggregation pipeline 的时候,使用聚合表达式查询,是一种类似与json的查询语言。
Query expression (JSON):查询表达式(JSON)(Query is aggregation pipeline没被选择的情况下)
{ name : "MongoDB" } 或者{ name : { '$regex' : "m.*", '$options' : "i" } }
Query is aggregation pipeline:将多个JSON表达式连接在一起,立即执行。聚合管道将几个JSON表达式串在一起,前面的表达式的输出将成为下一个表达式的输入。
Aggregation pipeline specification (JSON):聚合管道规范(JSON)(Query is aggregation pipeline被选择)
{ $match : {state : "FL", city : "ORLANDO" } }, {$sort : {pop : -1 } }或者{ $group : { _id: "$state"} }, { $sort : { _id : 1 } }
Execute for each row:对每一行数据执行查询
Fields expression (JSON):Query is aggregation pipeline没被选中时候有效,控制字段返回
MongoDB Input的更多相关文章
- kettle之mongodb数据同步
需求: 1.源数据库新增一条记录,目标库同时新增一条记录: 2.源数据库修改一条记录,目标库同时修改该条记录: 示例用到三个Kettle组件 下面详细说下每个组件的配置 Source: 本示例连接的是 ...
- Scala spark mongodb
最好的参考是Mongo官网的地址 https://docs.mongodb.com/spark-connector/getting-started/ 需要截图所示的包 代码地址 https://git ...
- Spark连接MongoDB之Scala
MongoDB Connector for Spark Spark Connector Scala Guide spark-shell --jars "mongo-spark-connect ...
- MongoDB With Spark遇到的2个错误,不能初始化和sample重复的key
1.$sample stage could not find a non-duplicate document while using a random cursor 这个问题比较难解决,因为我用mo ...
- Scala2.11.8 spark2.3.1 mongodb connector 2.3.0
import java.sql.DriverManager import com.mongodb.spark._ import org.apache.spark.SparkConf import or ...
- spark读取mongodb数据写入hive表中
一 环境: spark-: hive-; scala-; hadoop--cdh-; jdk-1.8; mongodb-2.4.10; 二.数据情况: MongoDB数据格式{ "_i ...
- MongoDB + Spark: 完整的大数据解决方案
Spark介绍 按照官方的定义,Spark 是一个通用,快速,适用于大规模数据的处理引擎. 通用性:我们可以使用Spark SQL来执行常规分析, Spark Streaming 来流数据处理, 以及 ...
- pyspark mongodb yarn
from pyspark.sql import SparkSession my_spark = SparkSession \ .builder \ .appName("myApp" ...
- Mongodb——文档数据库
mongodb是一个文档数据库. mongo操作 多个修改操作,但每个修改携带的数据包较小,可操作考虑批量操作.bulkWrite()改善性能. MongoCollection是线程安全的. db.c ...
随机推荐
- mysqll中索引详细讲解
MySQL(五) MySQL中的索引详讲 序言 之前写到MySQL对表的增删改查(查询最为重要)后,就感觉MySQL就差不多学完了,没有想继续学下去的心态了,原因可能是由于别人的影响,觉得对于My ...
- Linux gdb调试及后台程序问题
https://blog.csdn.net/lengchanguo/article/details/50481533 转? 问题是后台& 调试
- [唐胡璐]Selenium技巧- ReportNG替换TestNG默认结果报告
TestNG默认的报告虽然内容挺全,但是展现效果却不太理想,不易阅读。因此我们想利用ReportNG来替代TestNG默认的report。 什么是ReportNG呢?这里不多说,请直接参见:http: ...
- NPM酷库:jsdom,纯JS实现的DOM
NPM酷库,每天两分钟,了解一个流行NPM库. 昨天认识了一个在Node.js环境下操作HTML的库 cheerio,cheerio实现了jQuery接口,用起来十分方便.为什么不直接用jQuery呢 ...
- php遍历一个文件下的所有文件和子文件夹下的文件
function AllFile($dir){ if($dh = opendir($dir)){ while (($file = readdir($dh)) !== false){ if($file ...
- 012_linuxC++之_类的继承定义
(一)访问控制和继承 公有继承(public):当一个类派生自公有基类时,基类的公有成员也是派生类的公有成员,基类的保护成员也是派生类的保护成员,基类的私有成员不能直接被派生类访问,但是可以通过调用基 ...
- 小米 oj 发奖励(思维)
发奖励 序号:#75难度:有挑战时间限制:1000ms内存限制:10M 描述 小明老师准备给一些得到小红花的小朋友发糖果做为奖励. 假设有n个小朋友,每个小朋友拥有的小红花为m(n)个,他让这n个小 ...
- Bert系列 源码解读 四 篇章
Bert系列(一)——demo运行 Bert系列(二)——模型主体源码解读 Bert系列(三)——源码解读之Pre-trainBert系列(四)——源码解读之Fine-tune 转载自: https: ...
- Linux下更换为阿里yum源
更新日期: 2018-08-06 1.yum源的工作原理 yum是为了解决安装包的依赖关系而生的,如果要源码安装一个软件,需要频繁下载各个包,并解决包的依赖关系.这就好比学门课程,要学会这门课程,就要 ...
- 记一次 用 ssh 反向代理解决的远程操作效率问题
公司在异地有一个项目,项目在内网有一个linux 集群开发人员通过 xshell 进行操作,但是开发过程中还需要公司开发人员进行远程操作,原来采用的方案是向日葵,需求能实现但是限于网络环境向日葵实在是 ...