Zookeeper源码(启动+选举)
简介
关于Zookeeper,目前普遍的应用场景基本作为服务注册中心,用于服务发现。但这只是Zookeeper的一个的功能,根据Apache的官方概述:“The Apache ZooKeeper system for distributed coordination is a high-performance service for building distributed applications.” Zookeeper是一个用于构建分布式应用的coordination, 并且为高性能的。Zookeeper借助于它内部的节点结构和监听机制,能用于很大部分的分布式协调场景。配置管理、命名服务、分布式锁、服务发现和发布订阅等等,这些场景在Zookeeper中基本使用其节点的“变更+通知”来实现。因为分布式的重点在于通信,通信的作用也就是协调。
Zookeeper由Java语言编写(也有C语言的Api实现),对于其原理,算是Paxos算法的实现,包含了Leader、Follower、Proposal等角色和选举之类的一些概念,但于Paxos还有一些不同(ZAB协议)。对于Paxos算法,个人认为,它是一套解决方案的理论,想要理解也有点的复杂。这里对于算法不太深入概述,仅对于Zookeeper服务端进行部分源码解析,包含应用的启动和选举方面,不包含Client。
源码获取
Zookeeper源码可以从Github(https://github.com/apache/zookeeper)上clone下来;
也可从Zookeeper官网(Apache)https://zookeeper.apache.org/releases.html上获取。
Zookeeper在3.5.5之前使用的是Ant构建,在3.5.5开始使用的是Maven构建。
本次采用的3.5.4版本进行解析
工程结构
目录结构:
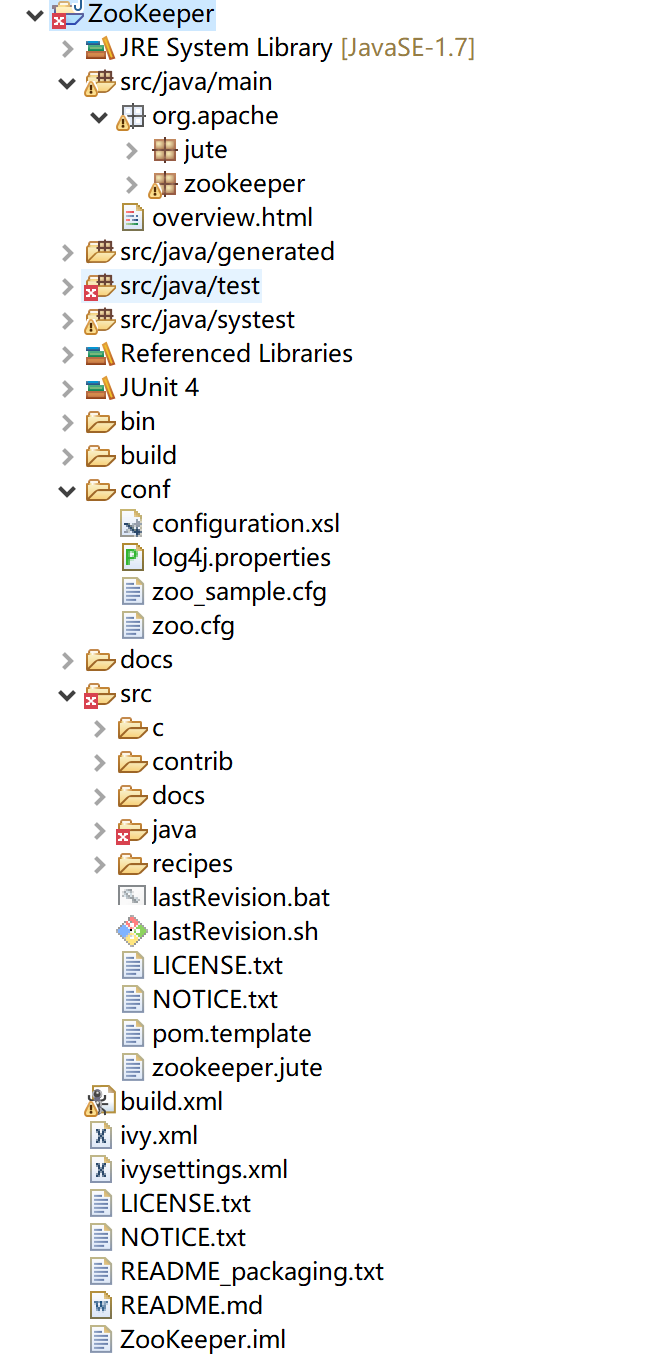
其中src中包含了C和Java源码,本次忽略C的Api。conf下为配置文件,也就是Zookeeper启动的配置文件。bin为Zookeeper启动脚本(server/client)。
org.apache.jute为Zookeeper的通信协议和序列化相关的组件,其通信协议基于TCP协议,它提供了Record接口用于序列化和反序列化,OutputArchive/InputArchive接口.
org.apache.zookeeper下为Zookeeper核心代码。包含了核心的业务实现。
启动流程
在我们使用Zookeeper的应用时,通过“./zkServer.sh start”命令来启动程序。通过查看zkServer.sh脚本,可以追踪到Zookeeper程序启动入口为“org.apache.zookeeper.server.quorum.QuorumPeerMain”,同时为程序指定了日志相关的配置。
1 ZOOMAIN="org.apache.zookeeper.server.quorum.QuorumPeerMain"
2 #.......
3 nohup "$JAVA" $ZOO_DATADIR_AUTOCREATE "-Dzookeeper.log.dir=${ZOO_LOG_DIR}" \
4 "-Dzookeeper.log.file=${ZOO_LOG_FILE}" "-Dzookeeper.root.logger=${ZOO_LOG4J_PROP}" \
5 -XX:+HeapDumpOnOutOfMemoryError -XX:OnOutOfMemoryError='kill -9 %p' \
6 -cp "$CLASSPATH" $JVMFLAGS $ZOOMAIN "$ZOOCFG" > "$_ZOO_DAEMON_OUT" 2>&1 < /dev/null &
7 if [ $? -eq 0 ]
#.......
Zookeeper启动流程:
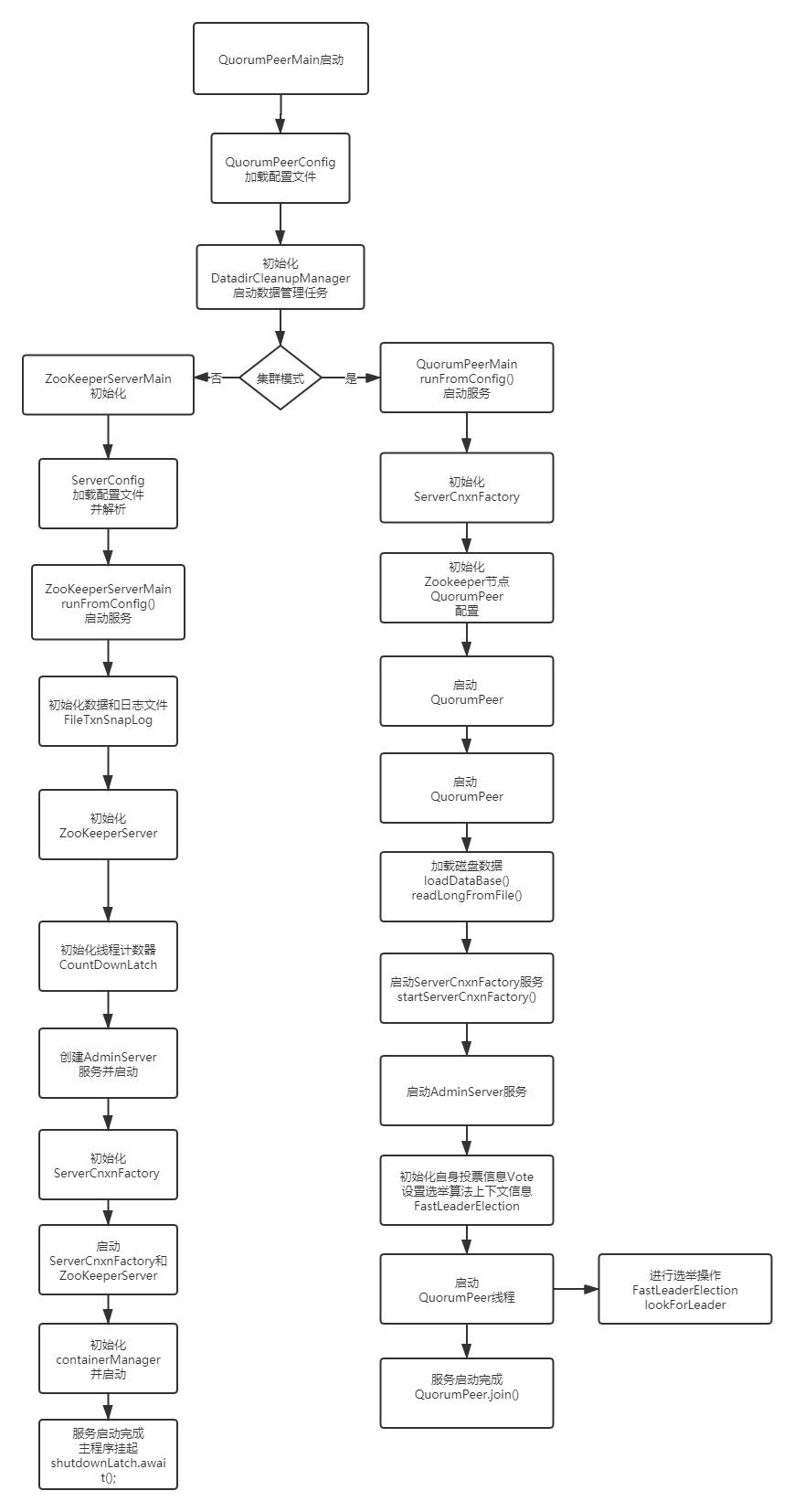
QuorumPeerMain.main()接受至少一个参数,一般就一个参数,参数为zoo.cfg文件路径。main方法中没有很多的业务代码,实例化了一个QuorumPeerMain 对象,然后main.initializeAndRun(args);进行了实例化
1 public static void main(String[] args) {
2 QuorumPeerMain main = new QuorumPeerMain();
3 try {
4 main.initializeAndRun(args);
5 } catch (IllegalArgumentException e) {
6 LOG.error("Invalid arguments, exiting abnormally", e);
7 LOG.info(USAGE);
8 System.err.println(USAGE);
9 System.exit(2);
10 } catch (ConfigException e) {
11 LOG.error("Invalid config, exiting abnormally", e);
12 System.err.println("Invalid config, exiting abnormally");
13 System.exit(2);
14 } catch (DatadirException e) {
15 LOG.error("Unable to access datadir, exiting abnormally", e);
16 System.err.println("Unable to access datadir, exiting abnormally");
17 System.exit(3);
18 } catch (AdminServerException e) {
19 LOG.error("Unable to start AdminServer, exiting abnormally", e);
20 System.err.println("Unable to start AdminServer, exiting abnormally");
21 System.exit(4);
22 } catch (Exception e) {
23 LOG.error("Unexpected exception, exiting abnormally", e);
24 System.exit(1);
25 }
26 LOG.info("Exiting normally");
27 System.exit(0);
28 }
initializeAndRun方法则通过实例化QuorumPeerConfig对象,通过parseProperties()来解析zoo.cfg文件中的配置,QuorumPeerConfig包含了Zookeeper整个应用的配置属性。接着开启一个DatadirCleanupManager对象来开启一个Timer用于清除并创建管理新的DataDir相关的数据。
最后进行程序的启动,因为Zookeeper分为单机和集群模式,所以分为两种不同的启动方式,当zoo.cfg文件中配置了standaloneEnabled=true为单机模式,如果配置server.0,server.1......集群节点,则为集群模式.
1 protected void initializeAndRun(String[] args)
2 throws ConfigException, IOException, AdminServerException
3 {
4 QuorumPeerConfig config = new QuorumPeerConfig();
5 if (args.length == 1) {
6 config.parse(args[0]);
7 }
8
9 // Start and schedule the the purge task
10 DatadirCleanupManager purgeMgr = new DatadirCleanupManager(config
11 .getDataDir(), config.getDataLogDir(), config
12 .getSnapRetainCount(), config.getPurgeInterval());
13 purgeMgr.start();
14
15 // 当配置了多节点信息,return quorumVerifier!=null && (!standaloneEnabled || quorumVerifier.getVotingMembers().size() > 1);
16 if (args.length == 1 && config.isDistributed()) {
17 // 集群模式
18 runFromConfig(config);
19 } else {
20 LOG.warn("Either no config or no quorum defined in config, running "
21 + " in standalone mode");
22 // there is only server in the quorum -- run as standalone
23 // 单机模式
24 ZooKeeperServerMain.main(args);
25 }
26 }
单机模式启动
当配置了standaloneEnabled=true 或者没有配置集群节点(sever.*)时,Zookeeper使用单机环境启动。单机环境启动入口为ZooKeeperServerMain类,ZooKeeperServerMain类中持有ServerCnxnFactory、ContainerManager和AdminServer对象;
1 public class ZooKeeperServerMain {
2 /*.............*/
3 // ZooKeeper server supports two kinds of connection: unencrypted and encrypted.
4 private ServerCnxnFactory cnxnFactory;
5 private ServerCnxnFactory secureCnxnFactory;
6 private ContainerManager containerManager;
7
8 private AdminServer adminServer;
9 /*.............*/
10 }
ServerCnxnFactory为Zookeeper中的核心组件,用于网络通信IO的实现和管理客户端连接,Zookeeper内部提供了两种实现,一种是基于JDK的NIO实现,一种是基于netty的实现。
ContainerManager类,用于管理维护Zookeeper中节点Znode的信息,管理zkDatabase;
AdminServer是一个Jetty服务,默认开启8080端口,用于提供Zookeeper的信息的查询接口。该功能从3.5的版本开始。
ZooKeeperServerMain的main方法中同QuorumPeerMain中一致,先实例化本身的对象,再进行init,加载配置文件,然后启动。
加载配置信息:
1 // 解析单机模式的配置对象,并启动单机模式
2 protected void initializeAndRun(String[] args)
3 throws ConfigException, IOException, AdminServerException
4 {
5 try {
6
7 //注册jmx
8 // JMX的全称为Java Management Extensions.是管理Java的一种扩展。
9 // 这种机制可以方便的管理、监控正在运行中的Java程序。常用于管理线程,内存,日志Level,服务重启,系统环境等
10 ManagedUtil.registerLog4jMBeans();
11 } catch (JMException e) {
12 LOG.warn("Unable to register log4j JMX control", e);
13 }
14
15 // 创建服务配置对象
16 ServerConfig config = new ServerConfig();
17
18 //如果入参只有一个,则认为是配置文件的路径
19 if (args.length == 1) {
20 // 解析配置文件
21 config.parse(args[0]);
22 } else {
23 // 参数有多个,解析参数
24 config.parse(args);
25 }
26
27 // 根据配置运行服务
28 runFromConfig(config);
29 }
服务启动: runFromConfig()为应用启动之前初始化一些对象,
1. 初始化FileTxnSnapLog对象,用于管理dataDir和datalogDir数据。
2. 初始化ZooKeeperServer 对象;
3. 实例化CountDownLatch线程计数器对象,在程序启动后,执行shutdownLatch.await();用于挂起主程序,并监听Zookeeper运行状态。
4. 创建adminServer(Jetty)服务并开启。
5. 创建ServerCnxnFactory对象,cnxnFactory = ServerCnxnFactory.createFactory(); Zookeeper默认使用NIOServerCnxnFactory来实现网络通信IO。
6. 启动ServerCnxnFactory服务
7. 创建ContainerManager对象,并启动;
8. Zookeeper应用启动。
1 public void runFromConfig(ServerConfig config)
2 throws IOException, AdminServerException {
3 LOG.info("Starting server");
4 FileTxnSnapLog txnLog = null;
5 try {
6 // Note that this thread isn't going to be doing anything else,
7 // so rather than spawning another thread, we will just call
8 // run() in this thread.
9 // create a file logger url from the command line args
10 //初始化日志文件
11 txnLog = new FileTxnSnapLog(config.dataLogDir, config.dataDir);
12
13 // 初始化zkServer对象
14 final ZooKeeperServer zkServer = new ZooKeeperServer(txnLog,
15 config.tickTime, config.minSessionTimeout, config.maxSessionTimeout, null);
16
17 // 服务结束钩子,用于知道服务器错误或关闭状态更改。
18 final CountDownLatch shutdownLatch = new CountDownLatch(1);
19 zkServer.registerServerShutdownHandler(
20 new ZooKeeperServerShutdownHandler(shutdownLatch));
21
22
23 // Start Admin server
24 // 创建admin服务,用于接收请求(创建jetty服务)
25 adminServer = AdminServerFactory.createAdminServer();
26 // 设置zookeeper服务
27 adminServer.setZooKeeperServer(zkServer);
28 // AdminServer是3.5.0之后支持的特性,启动了一个jettyserver,默认端口是8080,访问此端口可以获取Zookeeper运行时的相关信息
29 adminServer.start();
30
31 boolean needStartZKServer = true;
32
33
34 //---启动ZooKeeperServer
35 //判断配置文件中 clientportAddress是否为null
36 if (config.getClientPortAddress() != null) {
37 //ServerCnxnFactory是Zookeeper中的重要组件,负责处理客户端与服务器的连接
38 //初始化server端IO对象,默认是NIOServerCnxnFactory:Java原生NIO处理网络IO事件
39 cnxnFactory = ServerCnxnFactory.createFactory();
40
41 //初始化配置信息
42 cnxnFactory.configure(config.getClientPortAddress(), config.getMaxClientCnxns(), false);
43
44 //启动服务:此方法除了启动ServerCnxnFactory,还会启动ZooKeeper
45 cnxnFactory.startup(zkServer);
46 // zkServer has been started. So we don't need to start it again in secureCnxnFactory.
47 needStartZKServer = false;
48 }
49 if (config.getSecureClientPortAddress() != null) {
50 secureCnxnFactory = ServerCnxnFactory.createFactory();
51 secureCnxnFactory.configure(config.getSecureClientPortAddress(), config.getMaxClientCnxns(), true);
52 secureCnxnFactory.startup(zkServer, needStartZKServer);
53 }
54
55 // 定时清除容器节点
56 //container ZNodes是3.6版本之后新增的节点类型,Container类型的节点会在它没有子节点时
57 // 被删除(新创建的Container节点除外),该类就是用来周期性的进行检查清理工作
58 containerManager = new ContainerManager(zkServer.getZKDatabase(), zkServer.firstProcessor,
59 Integer.getInteger("znode.container.checkIntervalMs", (int) TimeUnit.MINUTES.toMillis(1)),
60 Integer.getInteger("znode.container.maxPerMinute", 10000)
61 );
62 containerManager.start();
63
64 // Watch status of ZooKeeper server. It will do a graceful shutdown
65 // if the server is not running or hits an internal error.
66
67 // ZooKeeperServerShutdownHandler处理逻辑,只有在服务运行不正常的情况下,才会往下执行
68 shutdownLatch.await();
69
70 // 关闭服务
71 shutdown();
72
73 if (cnxnFactory != null) {
74 cnxnFactory.join();
75 }
76 if (secureCnxnFactory != null) {
77 secureCnxnFactory.join();
78 }
79 if (zkServer.canShutdown()) {
80 zkServer.shutdown(true);
81 }
82 } catch (InterruptedException e) {
83 // warn, but generally this is ok
84 LOG.warn("Server interrupted", e);
85 } finally {
86 if (txnLog != null) {
87 txnLog.close();
88 }
89 }
90 }
Zookeeper中 ServerCnxnFactory默认采用了NIOServerCnxnFactory来实现,也可以通过配置系统属性zookeeper.serverCnxnFactory 来设置使用Netty实现;
1 static public ServerCnxnFactory createFactory() throws IOException {
2 String serverCnxnFactoryName =
3 System.getProperty(ZOOKEEPER_SERVER_CNXN_FACTORY);
4 if (serverCnxnFactoryName == null) {
5 //如果未指定实现类,默认使用NIOServerCnxnFactory
6 serverCnxnFactoryName = NIOServerCnxnFactory.class.getName();
7 }
8 try {
9 ServerCnxnFactory serverCnxnFactory = (ServerCnxnFactory) Class.forName(serverCnxnFactoryName)
10 .getDeclaredConstructor().newInstance();
11 LOG.info("Using {} as server connection factory", serverCnxnFactoryName);
12 return serverCnxnFactory;
13 } catch (Exception e) {
14 IOException ioe = new IOException("Couldn't instantiate "
15 + serverCnxnFactoryName);
16 ioe.initCause(e);
17 throw ioe;
18 }
19 }
cnxnFactory.startup(zkServer);方法启动了ServerCnxnFactory ,同时启动ZooKeeper服务
1 public void startup(ZooKeeperServer zks, boolean startServer)
2 throws IOException, InterruptedException {
3 // 启动相关线程
4 //开启NIOWorker线程池,
5 //启动NIO Selector线程
6 //启动客户端连接处理acceptThread线程
7 start();
8 setZooKeeperServer(zks);
9
10 //启动服务
11 if (startServer) {
12 // 加载数据到zkDataBase
13 zks.startdata();
14 // 启动定时清除session的管理器,注册jmx,添加请求处理器
15 zks.startup();
16 }
17 }
zks.startdata();
1 public void startdata() throws IOException, InterruptedException {
2 //初始化ZKDatabase,该数据结构用来保存ZK上面存储的所有数据
3 //check to see if zkDb is not null
4 if (zkDb == null) {
5 //初始化数据数据,这里会加入一些原始节点,例如/zookeeper
6 zkDb = new ZKDatabase(this.txnLogFactory);
7 }
8 //加载磁盘上已经存储的数据,如果有的话
9 if (!zkDb.isInitialized()) {
10 loadData();
11 }
12 }
zks.startup();
1 public synchronized void startup() {
2 //初始化session追踪器
3 if (sessionTracker == null) {
4 createSessionTracker();
5 }
6 //启动session追踪器
7 startSessionTracker();
8
9 //建立请求处理链路
10 setupRequestProcessors();
11
12 //注册jmx
13 registerJMX();
14
15 setState(State.RUNNING);
16 notifyAll();
17 }
最终Zookeeper应用服务启动,并处于监听状态。
集群模式启动
Zookeeper主程序QuorumPeerMain加载配置文件后,配置容器对象QuorumPeerConfig中持有一个QuorumVerifier对象,该对象会存储其他Zookeeper server节点信息,如果zoo.cfg中配置了server.*节点信息,会实例化一个QuorumVeriferi对象。其中AllMembers = VotingMembers + ObservingMembers
1 public interface QuorumVerifier {
2 long getWeight(long id);
3 boolean containsQuorum(Set<Long> set);
4 long getVersion();
5 void setVersion(long ver);
6 Map<Long, QuorumServer> getAllMembers();
7 Map<Long, QuorumServer> getVotingMembers();
8 Map<Long, QuorumServer> getObservingMembers();
9 boolean equals(Object o);
10 String toString();
11 }
如果quorumVerifier.getVotingMembers().size() > 1 则使用集群模式启动。调用runFromConfig(QuorumPeerConfig config),同时会实例化ServerCnxnFactory 对象,初始化一个QuorumPeer对象。
QuorumPeer为一个Zookeeper节点, QuorumPeer 为一个线程类,代表一个Zookeeper服务线程,最终会启动该线程。
runFromConfig方法中设置了一些列属性。包括选举类型、server Id、节点数据库等信息。最后通过quorumPeer.start();启动Zookeeper节点。
1 public void runFromConfig(QuorumPeerConfig config)
2 throws IOException, AdminServerException
3 {
4 try {
5 // 注册jmx
6 ManagedUtil.registerLog4jMBeans();
7 } catch (JMException e) {
8 LOG.warn("Unable to register log4j JMX control", e);
9 }
10
11 LOG.info("Starting quorum peer");
12 try {
13 ServerCnxnFactory cnxnFactory = null;
14 ServerCnxnFactory secureCnxnFactory = null;
15
16 if (config.getClientPortAddress() != null) {
17 cnxnFactory = ServerCnxnFactory.createFactory();
18 // 配置客户端连接端口
19 cnxnFactory.configure(config.getClientPortAddress(),
20 config.getMaxClientCnxns(),
21 false);
22 }
23
24 if (config.getSecureClientPortAddress() != null) {
25 secureCnxnFactory = ServerCnxnFactory.createFactory();
26 // 配置安全连接端口
27 secureCnxnFactory.configure(config.getSecureClientPortAddress(),
28 config.getMaxClientCnxns(),
29 true);
30 }
31
32 // ------------初始化当前zk服务节点的配置----------------
33 // 设置数据和快照操作
34 quorumPeer = getQuorumPeer();
35 quorumPeer.setTxnFactory(new FileTxnSnapLog(
36 config.getDataLogDir(),
37 config.getDataDir()));
38 quorumPeer.enableLocalSessions(config.areLocalSessionsEnabled());
39 quorumPeer.enableLocalSessionsUpgrading(
40 config.isLocalSessionsUpgradingEnabled());
41 //quorumPeer.setQuorumPeers(config.getAllMembers());
42 // 选举类型
43 quorumPeer.setElectionType(config.getElectionAlg());
44 // server Id
45 quorumPeer.setMyid(config.getServerId());
46 quorumPeer.setTickTime(config.getTickTime());
47 quorumPeer.setMinSessionTimeout(config.getMinSessionTimeout());
48 quorumPeer.setMaxSessionTimeout(config.getMaxSessionTimeout());
49 quorumPeer.setInitLimit(config.getInitLimit());
50 quorumPeer.setSyncLimit(config.getSyncLimit());
51 quorumPeer.setConfigFileName(config.getConfigFilename());
52
53 // 设置zk的节点数据库
54 quorumPeer.setZKDatabase(new ZKDatabase(quorumPeer.getTxnFactory()));
55 quorumPeer.setQuorumVerifier(config.getQuorumVerifier(), false);
56 if (config.getLastSeenQuorumVerifier()!=null) {
57 quorumPeer.setLastSeenQuorumVerifier(config.getLastSeenQuorumVerifier(), false);
58 }
59
60 // 初始化zk数据库
61 quorumPeer.initConfigInZKDatabase();
62 quorumPeer.setCnxnFactory(cnxnFactory);
63 quorumPeer.setSecureCnxnFactory(secureCnxnFactory);
64 quorumPeer.setLearnerType(config.getPeerType());
65 quorumPeer.setSyncEnabled(config.getSyncEnabled());
66 quorumPeer.setQuorumListenOnAllIPs(config.getQuorumListenOnAllIPs());
67
68 // sets quorum sasl authentication configurations
69 quorumPeer.setQuorumSaslEnabled(config.quorumEnableSasl);
70 if(quorumPeer.isQuorumSaslAuthEnabled()){
71 quorumPeer.setQuorumServerSaslRequired(config.quorumServerRequireSasl);
72 quorumPeer.setQuorumLearnerSaslRequired(config.quorumLearnerRequireSasl);
73 quorumPeer.setQuorumServicePrincipal(config.quorumServicePrincipal);
74 quorumPeer.setQuorumServerLoginContext(config.quorumServerLoginContext);
75 quorumPeer.setQuorumLearnerLoginContext(config.quorumLearnerLoginContext);
76 }
77 quorumPeer.setQuorumCnxnThreadsSize(config.quorumCnxnThreadsSize);
78
79 // -------------初始化当前zk服务节点的配置---------------
80 quorumPeer.initialize();
81
82 //启动
83 quorumPeer.start();
84 quorumPeer.join();
85 } catch (InterruptedException e) {
86 // warn, but generally this is ok
87 LOG.warn("Quorum Peer interrupted", e);
88 }
89 }
quorumPeer.start(); Zookeeper会首先加载本地磁盘数据,如果之前存在一些Zookeeper信息,则会加载到Zookeeper内存数据库中。通过FileTxnSnapLog中的loadDatabse();
1 public synchronized void start() {
2
3 // 校验serverid如果不在peer列表中,抛异常
4 if (!getView().containsKey(myid)) {
5 throw new RuntimeException("My id " + myid + " not in the peer list");
6 }
7
8 // 加载zk数据库:载入之前持久化的一些信息
9 loadDataBase();
10
11 // 启动连接服务端
12 startServerCnxnFactory();
13 try {
14 adminServer.start();
15 } catch (AdminServerException e) {
16 LOG.warn("Problem starting AdminServer", e);
17 System.out.println(e);
18 }
19 // 启动之后马上进行选举,主要是创建选举必须的环境,比如:启动相关线程
20 startLeaderElection();
21
22 // 执行选举逻辑
23 super.start();
24 }
加载数据完之后同单机模式启动一样,会调用ServerCnxnFactory.start(),启动NIOServerCnxnFactory服务和Zookeeper服务,最后启动AdminServer服务。
与单机模式启动不同的是,集群会在启动之后马上进行选举操作,会在配置的所有Zookeeper server节点中选举出一个leader角色。startLeaderElection();
选举
Zookeeper中分为Leader、Follower和Observer三个角色,各个角色扮演不同的业务功能。在Leader故障之后,Follower也会选举一个新的Leader。
Leader为集群中的主节点,一个集群只有一个Leader,Leader负责处理Zookeeper的事物操作,也就是更改Zookeeper数据和状态的操作。
Follower负责处理客户端的读请求和参与选举。同时负责处理Leader发出的事物提交请求,也就是提议(proposal)。
Observer用于提高Zookeeper集群的读取的吞吐量,响应读请求,和Follower不同的是,Observser不参与Leader的选举,也不响应Leader发出的proposal。
有角色就有选举。有选举就有策略,Zookeeper中的选举策略有三种实现:包括了LeaderElection、AuthFastLeaderElection和FastLeaderElection,目前Zookeeper默认采用FastLeaderElection,前两个选举算法已经设置为@Deprecated;
Zookeeper节点信息
serverId:服务节点Id,也就是Zookeeper dataDir中配置的myid ,server.*上指定的id。0,1,2,3,4..... ,该Id启动后不变
zxid:数据状态Id,zookeeper每次更新状态之后增加,可理解为全局有序id ,zxid越大,表示数据越新。Zxid是一个64位的数字,高32位为epoch,低32位为递增计数。
epoch:选举时钟,也可以理解为选举轮次,没进行一次选举,该值会+1;
ServerState:服务状态,Zookeeper节点角色状态,分为LOOKING、FOLLOWING、LEADING和OBSERVING,分别对应于不同的角色,当处于选举时,节点处于Looking状态。
每次投票,一个Vote会包含Zookeeper节点信息。
Zookeeper在启动之后会马上进行选举操作,不断的向其他Follower节点发送选票信息,同时也接收别的Follower发送过来的选票信息。最终每个Follower都持有共同的一个选票池,通过同样的算法选出Leader,如果当前节点选为Leader,则向其他每个Follower发送信息,如果没有则向Leader发送信息。
Zookeeper定义了Election接口;其中lookForLeader()就是选举操作。
1 public interface Election {
2 public Vote lookForLeader() throws InterruptedException;
3 public void shutdown();
4 }
在上面的集群模式启动流程中,最后会调用startLeaderElection()来下进行选举操作。startLeaderElection()中指定了选举算法。同时定义了为自己投一票(坚持你自己,年轻人!),一个Vote包含了投票节点、当前节点的zxid和当前的epoch。Zookeeper默认采取了FastLeaderElection选举算法。最后启动QuorumPeer线程,开始投票。
1 synchronized public void startLeaderElection() {
2 try {
3
4 // 所有节点启动的初始状态都是LOOKING,因此这里都会是创建一张投自己为Leader的票
5 if (getPeerState() == ServerState.LOOKING) {
6 currentVote = new Vote(myid, getLastLoggedZxid(), getCurrentEpoch());
7 }
8 } catch(IOException e) {
9 RuntimeException re = new RuntimeException(e.getMessage());
10 re.setStackTrace(e.getStackTrace());
11 throw re;
12 }
13
14 // if (!getView().containsKey(myid)) {
15 // throw new RuntimeException("My id " + myid + " not in the peer list");
16 //}
17 if (electionType == 0) {
18 try {
19 udpSocket = new DatagramSocket(myQuorumAddr.getPort());
20 responder = new ResponderThread();
21 responder.start();
22 } catch (SocketException e) {
23 throw new RuntimeException(e);
24 }
25 }
26 //初始化选举算法,electionType默认为3
27 this.electionAlg = createElectionAlgorithm(electionType);
28 }
FastLeaderElection类中定义三个内部类Notification、 ToSend 和 Messenger ,Messenger 中又定义了WorkerReceiver 和 WorkerSender
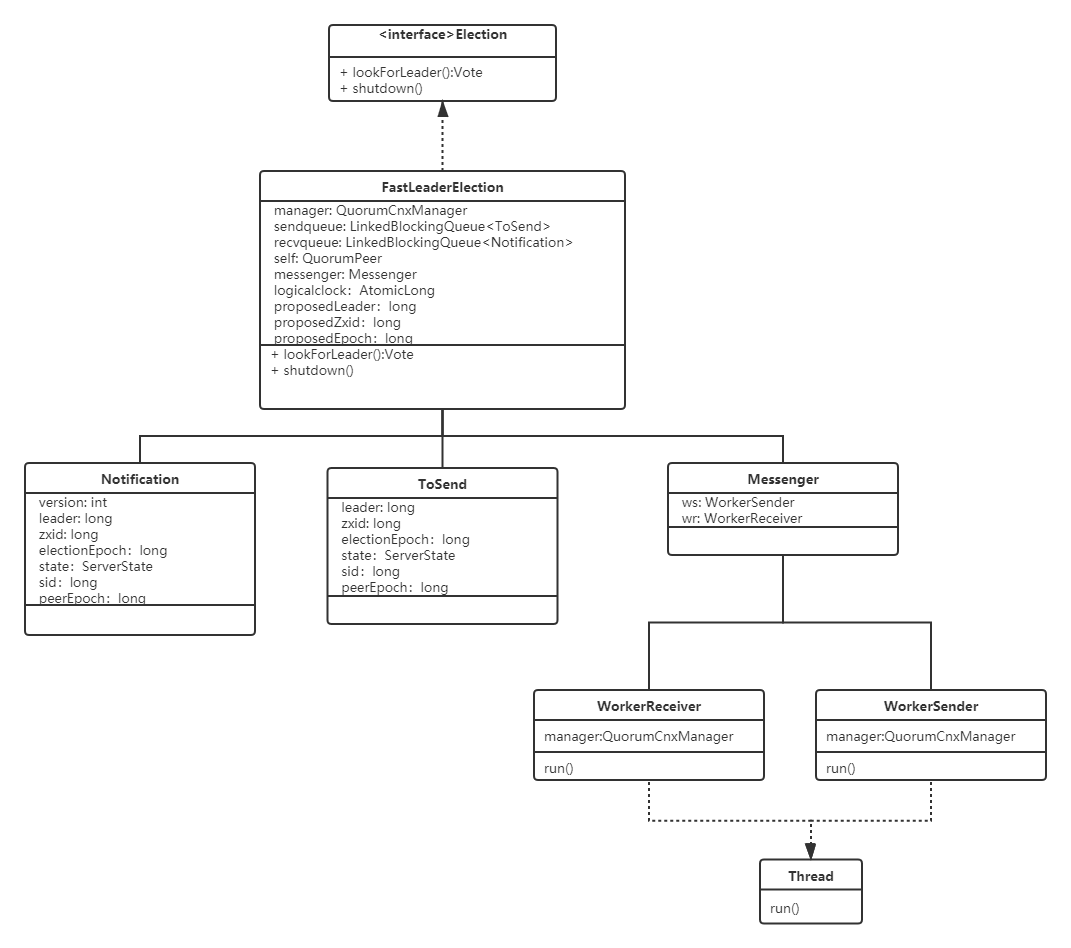
Notification类表示收到的选举投票信息(其他服务器发来的选举投票信息),其包含了被选举者的id、zxid、选举周期等信息。
ToSend类表示发送给其他服务器的选举投票信息,也包含了被选举者的id、zxid、选举周期等信息。
Message类为消息处理的类,用于发送和接收投票信息,包含了WorkerReceiver和WorkerSender两个线程类。
FastLeaderElection类:
1 public class FastLeaderElection implements Election {
2 //..........
3 /**
4 * Connection manager. Fast leader election uses TCP for
5 * communication between peers, and QuorumCnxManager manages
6 * such connections.
7 */
8
9 QuorumCnxManager manager;
10 /*
11 Notification表示收到的选举投票信息(其他服务器发来的选举投票信息),
12 其包含了被选举者的id、zxid、选举周期等信息,
13 其buildMsg方法将选举信息封装至ByteBuffer中再进行发送
14 */
15 static public class Notification {
16 //..........
17 }
18 /**
19 * Messages that a peer wants to send to other peers.
20 * These messages can be both Notifications and Acks
21 * of reception of notification.
22 */
23 /*
24 ToSend表示发送给其他服务器的选举投票信息,也包含了被选举者的id、zxid、选举周期等信息
25 */
26 static public class ToSend {
27 //..........
28 }
29 LinkedBlockingQueue<ToSend> sendqueue;
30 LinkedBlockingQueue<Notification> recvqueue;
31
32 /**
33 * Multi-threaded implementation of message handler. Messenger
34 * implements two sub-classes: WorkReceiver and WorkSender. The
35 * functionality of each is obvious from the name. Each of these
36 * spawns a new thread.
37 */
38 protected class Messenger {
39 /**
40 * Receives messages from instance of QuorumCnxManager on
41 * method run(), and processes such messages.
42 */
43
44 class WorkerReceiver extends ZooKeeperThread {
45 //..........
46 }
47 /**
48 * This worker simply dequeues a message to send and
49 * and queues it on the manager's queue.
50 */
51
52 class WorkerSender extends ZooKeeperThread {
53 //..........
54 }
55
56 WorkerSender ws;
57 WorkerReceiver wr;
58 Thread wsThread = null;
59 Thread wrThread = null;
60
61
62 }
63 //..........
64 QuorumPeer self;
65 Messenger messenger;
66 AtomicLong logicalclock = new AtomicLong(); /* Election instance */
67 long proposedLeader;
68 long proposedZxid;
69 long proposedEpoch;
70 //..........
71 }
QuorumPeer线程启动后会开启对ServerState的监听,如果当前服务节点属于Looking状态,则会执行选举操作。Zookeeper服务器启动后是Looking状态,所以服务启动后会马上进行选举操作。通过调用makeLEStrategy().lookForLeader()进行投票操作,也就是FastLeaderElection.lookForLeader();
QuorumPeer.run():
1 public void run() {
2 updateThreadName();
3
4 //..........
5
6 try {
7 /*
8 * Main loop
9 */
10 while (running) {
11 switch (getPeerState()) {
12 case LOOKING:
13 LOG.info("LOOKING");
14
15 if (Boolean.getBoolean("readonlymode.enabled")) {
16 final ReadOnlyZooKeeperServer roZk =
17 new ReadOnlyZooKeeperServer(logFactory, this, this.zkDb);
18 Thread roZkMgr = new Thread() {
19 public void run() {
20 try {
21 // lower-bound grace period to 2 secs
22 sleep(Math.max(2000, tickTime));
23 if (ServerState.LOOKING.equals(getPeerState())) {
24 roZk.startup();
25 }
26 } catch (InterruptedException e) {
27 LOG.info("Interrupted while attempting to start ReadOnlyZooKeeperServer, not started");
28 } catch (Exception e) {
29 LOG.error("FAILED to start ReadOnlyZooKeeperServer", e);
30 }
31 }
32 };
33 try {
34 roZkMgr.start();
35 reconfigFlagClear();
36 if (shuttingDownLE) {
37 shuttingDownLE = false;
38 startLeaderElection();
39 }
40 setCurrentVote(makeLEStrategy().lookForLeader());
41 } catch (Exception e) {
42 LOG.warn("Unexpected exception", e);
43 setPeerState(ServerState.LOOKING);
44 } finally {
45 roZkMgr.interrupt();
46 roZk.shutdown();
47 }
48 } else {
49 try {
50 reconfigFlagClear();
51 if (shuttingDownLE) {
52 shuttingDownLE = false;
53 startLeaderElection();
54 }
55 setCurrentVote(makeLEStrategy().lookForLeader());
56 } catch (Exception e) {
57 LOG.warn("Unexpected exception", e);
58 setPeerState(ServerState.LOOKING);
59 }
60 }
61 break;
62 case OBSERVING:
63 try {
64 LOG.info("OBSERVING");
65 setObserver(makeObserver(logFactory));
66 observer.observeLeader();
67 } catch (Exception e) {
68 LOG.warn("Unexpected exception",e );
69 } finally {
70 observer.shutdown();
71 setObserver(null);
72 updateServerState();
73 }
74 break;
75 case FOLLOWING:
76 try {
77 LOG.info("FOLLOWING");
78 setFollower(makeFollower(logFactory));
79 follower.followLeader();
80 } catch (Exception e) {
81 LOG.warn("Unexpected exception",e);
82 } finally {
83 follower.shutdown();
84 setFollower(null);
85 updateServerState();
86 }
87 break;
88 case LEADING:
89 LOG.info("LEADING");
90 try {
91 setLeader(makeLeader(logFactory));
92 leader.lead();
93 setLeader(null);
94 } catch (Exception e) {
95 LOG.warn("Unexpected exception",e);
96 } finally {
97 if (leader != null) {
98 leader.shutdown("Forcing shutdown");
99 setLeader(null);
100 }
101 updateServerState();
102 }
103 break;
104 }
105 start_fle = Time.currentElapsedTime();
106 }
107 } finally {
108 LOG.warn("QuorumPeer main thread exited");
109 MBeanRegistry instance = MBeanRegistry.getInstance();
110 instance.unregister(jmxQuorumBean);
111 instance.unregister(jmxLocalPeerBean);
112
113 for (RemotePeerBean remotePeerBean : jmxRemotePeerBean.values()) {
114 instance.unregister(remotePeerBean);
115 }
116
117 jmxQuorumBean = null;
118 jmxLocalPeerBean = null;
119 jmxRemotePeerBean = null;
120 }
121 }
FastLeaderElection.lookForLeader():
1 public Vote lookForLeader() throws InterruptedException {
2 try {
3 self.jmxLeaderElectionBean = new LeaderElectionBean();
4 MBeanRegistry.getInstance().register(
5 self.jmxLeaderElectionBean, self.jmxLocalPeerBean);
6 } catch (Exception e) {
7 LOG.warn("Failed to register with JMX", e);
8 self.jmxLeaderElectionBean = null;
9 }
10 if (self.start_fle == 0) {
11 self.start_fle = Time.currentElapsedTime();
12 }
13 try {
14 HashMap<Long, Vote> recvset = new HashMap<Long, Vote>();
15
16 HashMap<Long, Vote> outofelection = new HashMap<Long, Vote>();
17 //等待200毫秒
18 int notTimeout = finalizeWait;
19
20 synchronized(this){
21 //逻辑时钟自增+1
22 logicalclock.incrementAndGet();
23 updateProposal(getInitId(), getInitLastLoggedZxid(), getPeerEpoch());
24 }
25
26 LOG.info("New election. My id = " + self.getId() +
27 ", proposed zxid=0x" + Long.toHexString(proposedZxid));
28 //发送投票信息
29 sendNotifications();
30
31 /*
32 * Loop in which we exchange notifications until we find a leader
33 */
34 //判断是否为Looking状态
35 while ((self.getPeerState() == ServerState.LOOKING) &&
36 (!stop)){
37 /*
38 * Remove next notification from queue, times out after 2 times
39 * the termination time
40 */
41 //获取接收其他Follow发送的投票信息
42 Notification n = recvqueue.poll(notTimeout,
43 TimeUnit.MILLISECONDS);
44
45 /*
46 * Sends more notifications if haven't received enough.
47 * Otherwise processes new notification.
48 */
49 //未收到投票信息
50 if(n == null){
51 //判断是否和集群离线了
52 if(manager.haveDelivered()){
53 //未断开,发送投票
54 sendNotifications();
55 } else {
56 //断开,重连
57 manager.connectAll();
58 }
59 /*
60 * Exponential backoff
61 */
62 int tmpTimeOut = notTimeout*2;
63 notTimeout = (tmpTimeOut < maxNotificationInterval?
64 tmpTimeOut : maxNotificationInterval);
65 LOG.info("Notification time out: " + notTimeout);
66 } //接收到了投票,则处理收到的投票信息
67 else if (validVoter(n.sid) && validVoter(n.leader)) {
68 /*
69 * Only proceed if the vote comes from a replica in the current or next
70 * voting view for a replica in the current or next voting view.
71 */
72 //其他节点的Server.state
73 switch (n.state) {
74 case LOOKING:
75 //如果其他节点也为Looking状态,说明当前正处于选举阶段,则处理投票信息。
76
77 // If notification > current, replace and send messages out
78 //如果当前的epoch(投票轮次)小于其他的投票信息,则说明自己的投票轮次已经过时,则更新自己的投票轮次
79 if (n.electionEpoch > logicalclock.get()) {
80 //更新投票轮次
81 logicalclock.set(n.electionEpoch);
82 //清除收到的投票
83 recvset.clear();
84 //比对投票信息
85 //如果本身的投票信息 低于 收到的的投票信息,则使用收到的投票信息,否则再次使用自身的投票信息进行发送投票。
86 if(totalOrderPredicate(n.leader, n.zxid, n.peerEpoch,
87 getInitId(), getInitLastLoggedZxid(), getPeerEpoch())) {
88 //使用收到的投票信息
89 updateProposal(n.leader, n.zxid, n.peerEpoch);
90 } else {
91 //使用自己的投票信息
92 updateProposal(getInitId(),
93 getInitLastLoggedZxid(),
94 getPeerEpoch());
95 }
96 //发送投票信息
97 sendNotifications();
98 } else if (n.electionEpoch < logicalclock.get()) {
99 //如果其他节点的epoch小于当前的epoch则丢弃
100 if(LOG.isDebugEnabled()){
101 LOG.debug("Notification election epoch is smaller than logicalclock. n.electionEpoch = 0x"
102 + Long.toHexString(n.electionEpoch)
103 + ", logicalclock=0x" + Long.toHexString(logicalclock.get()));
104 }
105 break;
106 } else if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch,
107 proposedLeader, proposedZxid, proposedEpoch)) {
108 //同样的epoch,正常情况,所有节点基本处于同一轮次
109 //如果自身投票信息 低于 收到的投票信息,则更新投票信息。并发送
110 updateProposal(n.leader, n.zxid, n.peerEpoch);
111 sendNotifications();
112 }
113
114 if(LOG.isDebugEnabled()){
115 LOG.debug("Adding vote: from=" + n.sid +
116 ", proposed leader=" + n.leader +
117 ", proposed zxid=0x" + Long.toHexString(n.zxid) +
118 ", proposed election epoch=0x" + Long.toHexString(n.electionEpoch));
119 }
120 //投票信息Vote归档,收到的有效选票 票池
121 recvset.put(n.sid, new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch));
122
123 //统计投票结果 ,判断是否能结束选举
124 if (termPredicate(recvset,
125 new Vote(proposedLeader, proposedZxid,
126 logicalclock.get(), proposedEpoch))) {
127 //如果已经选出leader
128
129 // Verify if there is any change in the proposed leader
130 while((n = recvqueue.poll(finalizeWait,
131 TimeUnit.MILLISECONDS)) != null){
132 if(totalOrderPredicate(n.leader, n.zxid, n.peerEpoch,
133 proposedLeader, proposedZxid, proposedEpoch)){
134 recvqueue.put(n);
135 break;
136 }
137 }
138
139 /*
140 * This predicate is true once we don't read any new
141 * relevant message from the reception queue
142 */
143 //如果选票结果为当前节点,则更新ServerState,否则设置为Follwer
144 if (n == null) {
145 self.setPeerState((proposedLeader == self.getId()) ?
146 ServerState.LEADING: learningState());
147
148 Vote endVote = new Vote(proposedLeader,
149 proposedZxid, proposedEpoch);
150 leaveInstance(endVote);
151 return endVote;
152 }
153 }
154 break;
155 case OBSERVING:
156 LOG.debug("Notification from observer: " + n.sid);
157 break;
158 case FOLLOWING:
159 case LEADING:
160 /*
161 * Consider all notifications from the same epoch
162 * together.
163 */
164 //如果其他节点已经确定为Leader
165 //如果同一个的投票轮次,则加入选票池
166 //判断是否能过半选举出leader ,如果是,则checkLeader
167 /*checkLeader:
168 * 【是否能选举出leader】and
169 * 【(如果投票leader为自身,且轮次一致) or
170 * (如果所选leader不是自身信息在outofelection不为空,且leader的ServerState状态已经为leader)】
171 *
172 */
173 if(n.electionEpoch == logicalclock.get()){
174 recvset.put(n.sid, new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch));
175 if(termPredicate(recvset, new Vote(n.leader,
176 n.zxid, n.electionEpoch, n.peerEpoch, n.state))
177 && checkLeader(outofelection, n.leader, n.electionEpoch)) {
178 self.setPeerState((n.leader == self.getId()) ?
179 ServerState.LEADING: learningState());
180
181 Vote endVote = new Vote(n.leader, n.zxid, n.peerEpoch);
182 leaveInstance(endVote);
183 return endVote;
184 }
185 }
186
187 /*
188 * Before joining an established ensemble, verify that
189 * a majority are following the same leader.
190 * Only peer epoch is used to check that the votes come
191 * from the same ensemble. This is because there is at
192 * least one corner case in which the ensemble can be
193 * created with inconsistent zxid and election epoch
194 * info. However, given that only one ensemble can be
195 * running at a single point in time and that each
196 * epoch is used only once, using only the epoch to
197 * compare the votes is sufficient.
198 *
199 * @see https://issues.apache.org/jira/browse/ZOOKEEPER-1732
200 */
201 outofelection.put(n.sid, new Vote(n.leader,
202 IGNOREVALUE, IGNOREVALUE, n.peerEpoch, n.state));
203 //说明此时 集群中存在别的轮次选举已经有了选举结果
204 //比对outofelection选票池,是否能结束选举,同时检查leader信息
205 //如果能结束选举 接收到的选票产生的leader通过checkLeader为true,则更新当前节点信息
206 if (termPredicate(outofelection, new Vote(n.leader,
207 IGNOREVALUE, IGNOREVALUE, n.peerEpoch, n.state))
208 && checkLeader(outofelection, n.leader, IGNOREVALUE)) {
209 synchronized(this){
210 logicalclock.set(n.electionEpoch);
211 self.setPeerState((n.leader == self.getId()) ?
212 ServerState.LEADING: learningState());
213 }
214 Vote endVote = new Vote(n.leader, n.zxid, n.peerEpoch);
215 leaveInstance(endVote);
216 return endVote;
217 }
218 break;
219 default:
220 LOG.warn("Notification state unrecoginized: " + n.state
221 + " (n.state), " + n.sid + " (n.sid)");
222 break;
223 }
224 } else {
225 if (!validVoter(n.leader)) {
226 LOG.warn("Ignoring notification for non-cluster member sid {} from sid {}", n.leader, n.sid);
227 }
228 if (!validVoter(n.sid)) {
229 LOG.warn("Ignoring notification for sid {} from non-quorum member sid {}", n.leader, n.sid);
230 }
231 }
232 }
233 return null;
234 } finally {
235 try {
236 if(self.jmxLeaderElectionBean != null){
237 MBeanRegistry.getInstance().unregister(
238 self.jmxLeaderElectionBean);
239 }
240 } catch (Exception e) {
241 LOG.warn("Failed to unregister with JMX", e);
242 }
243 self.jmxLeaderElectionBean = null;
244 LOG.debug("Number of connection processing threads: {}",
245 manager.getConnectionThreadCount());
246 }
247 }
lookForLeader方法中把当前选票和收到的选举进行不断的比对和更新,最终选出leader,其中比对选票的方法为totalOrderPredicate(): 其中的比对投票信息方式为:
1. 首先判断epoch(选举轮次),也就是选择epoch值更大的节点;如果收到的epoch更大,则当前阶段落后,更新自己的epoch,否则丢弃。
2. 如果同于轮次中,则选择zxid更大的节点,因为zxid越大说明数据越新。
3. 如果同一轮次,且zxid一样,则选择serverId最大的节点。
综上3点可理解为越大越棒!
totalOrderPredicate():
1 protected boolean totalOrderPredicate(long newId, long newZxid, long newEpoch, long curId, long curZxid, long curEpoch) {
2 LOG.debug("id: " + newId + ", proposed id: " + curId + ", zxid: 0x" +
3 Long.toHexString(newZxid) + ", proposed zxid: 0x" + Long.toHexString(curZxid));
4 if(self.getQuorumVerifier().getWeight(newId) == 0){
5 return false;
6 }
7
8 /*
9 * We return true if one of the following three cases hold:
10 * 1- New epoch is higher
11 * 2- New epoch is the same as current epoch, but new zxid is higher
12 * 3- New epoch is the same as current epoch, new zxid is the same
13 * as current zxid, but server id is higher.
14 */
15
16 return ((newEpoch > curEpoch) ||
17 ((newEpoch == curEpoch) &&
18 ((newZxid > curZxid) || ((newZxid == curZxid) && (newId > curId)))));
19 }
选举流程
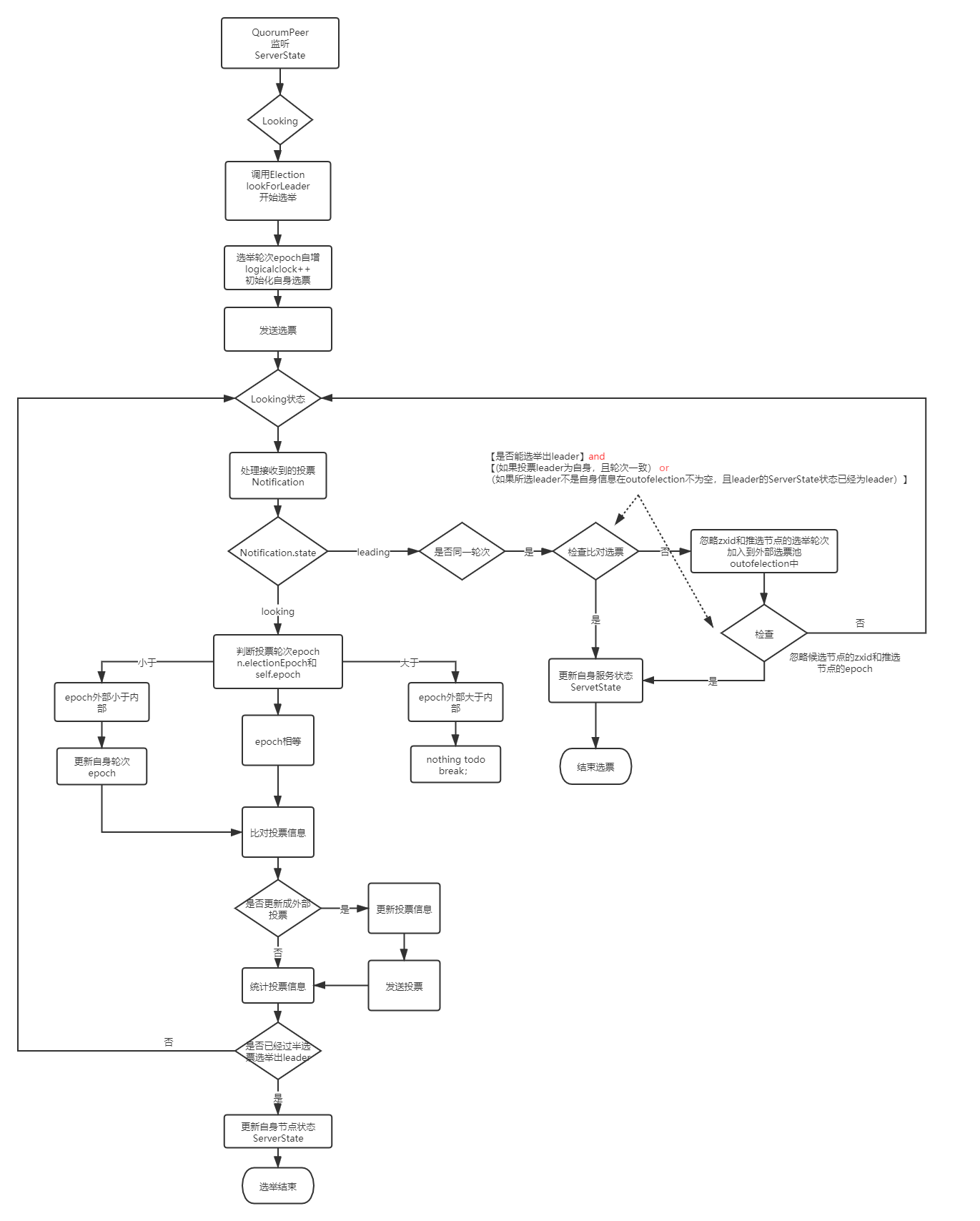
整个选举过程可大致理解不断的接收选票,比对选票,直到选出leader,每个zookeeper节点都持有自己的选票池,按照统一的比对算法,正常情况下最终选出来的leader是一致的。
end;
本内容仅是zookeeper一部分源码解析,包括启动和选举;其中核心的zookeeper事物处理和一致性协议ZAB,后续再跟进。如果不对或不妥的地方,欢迎留言指出。
Zookeeper github:https://github.com/apache/zookeeper/
Apache zk:https://zookeeper.apache.org/releases.html
源码部分注释来源:拉钩-子幕
Zookeeper源码(启动+选举)的更多相关文章
- Zookeeper 源码分析-启动
Zookeeper 源码分析-启动 博客分类: Zookeeper 本文主要介绍了zookeeper启动的过程 运行zkServer.sh start命令可以启动zookeeper.入口的main ...
- Zookeeper 源码(五)Leader 选举
Zookeeper 源码(五)Leader 选举 前面学习了 Zookeeper 服务端的相关细节,其中对于集群启动而言,很重要的一部分就是 Leader 选举,接着就开始深入学习 Leader 选举 ...
- Zookeeper 源码(六)Leader-Follower-Observer
Zookeeper 源码(六)Leader-Follower-Observer 上一节介绍了 Leader 选举的全过程,本节讲解一下 Leader-Follower-Observer 服务器的三种角 ...
- Zookeeper 源码(四)Zookeeper 服务端源码
Zookeeper 源码(四)Zookeeper 服务端源码 Zookeeper 服务端的启动入口为 QuorumPeerMain public static void main(String[] a ...
- zookeeper源码分析之五服务端(集群leader)处理请求流程
leader的实现类为LeaderZooKeeperServer,它间接继承自标准ZookeeperServer.它规定了请求到达leader时需要经历的路径: PrepRequestProcesso ...
- zookeeper源码分析之四服务端(单机)处理请求流程
上文: zookeeper源码分析之一服务端启动过程 中,我们介绍了zookeeper服务器的启动过程,其中单机是ZookeeperServer启动,集群使用QuorumPeer启动,那么这次我们分析 ...
- zookeeper源码分析之三客户端发送请求流程
znode 可以被监控,包括这个目录节点中存储的数据的修改,子节点目录的变化等,一旦变化可以通知设置监控的客户端,这个功能是zookeeper对于应用最重要的特性,通过这个特性可以实现的功能包括配置的 ...
- Zookeeper 源码(七)请求处理
Zookeeper 源码(七)请求处理 以单机启动为例讲解 Zookeeper 是如何处理请求的.先回顾一下单机时的请求处理链. // 单机包含 3 个请求链:PrepRequestProcessor ...
- Zookeeper 源码(三)Zookeeper 客户端源码
Zookeeper 源码(三)Zookeeper 客户端源码 Zookeeper 客户端主要有以下几个重要的组件.客户端会话创建可以分为三个阶段:一是初始化阶段.二是会话创建阶段.三是响应处理阶段. ...
随机推荐
- 实验 6:OpenDaylight 实验——OpenDaylight 及 Postman 实现流表下发
一.实验目的 熟悉 Postman 的使用;熟悉如何使用 OpenDaylight 通过 Postman 下发流表. 二.实验任务 流表有软超时和硬超时的概念,分别对应流表中的 idle_timeou ...
- 060 01 Android 零基础入门 01 Java基础语法 06 Java一维数组 07 冒泡排序
060 01 Android 零基础入门 01 Java基础语法 06 Java一维数组 07 冒泡排序 本文知识点:冒泡排序 冒泡排序 实际案例分析冒泡排序流程 第1轮比较: 第1轮比较的结果:把最 ...
- 独立看第一个C++程序到最终结果log----2019-04-16
(如果一个人夸你,千万别相信,一个人真优秀是不需要说出来的,所以别人夸你的时候也是自己最松懈的时候,千万不能飘,只能说明自己不是很差而已,世界上优秀的人很多,一直优秀到最后的人却是凤毛菱角. 如果一个 ...
- matlab中figure 创建图窗窗口
来源:https://ww2.mathworks.cn/help/matlab/ref/figure.html?searchHighlight=figure&s_tid=doc_srchtit ...
- vue使用vueCropper裁剪功能,代码复制直接使用
//先安装包 npm install vue-cropper --save-dev <template> <div id="merchantInformation" ...
- VMware ESXi 客户端连接控制台时,提示“VMRC 控制台连接已断开...正在尝试重新连接”的解决方法
故障描述: 通过 VMware vSphere Client 连接到安装 VMware ESXi 虚拟环境的主机时,当启动其中的虚拟机后,无法连接到控制台. 选择"控制台"时,控制 ...
- Windows Server 2003 蓝屏 -- 系统故障:停止错误
Windows Server 2003 EE 出现蓝屏: 0X0000004D (0X000f27D9, 0X000F27D9, 0X0000000C, 0X00000000) 蓝屏拍照: 重启机器 ...
- 十一长假我肝了这本超硬核PDF,现决定开源!!
写在前面 在 [冰河技术] 微信公众号中的[互联网工程]专题,更新了不少文章,有些读者反馈说,在公众号中刷 历史文章不太方便,有时会忘记自己看到哪一篇了,当打开一篇文章时,似乎之前已经看过了,但就是不 ...
- centos7.5安装gcc7.2.0
参考https://www.cnblogs.com/lazyInsects/p/9778910.html cd /usr/src wget https://mirrors.tuna.tsinghua. ...
- Go | Go 使用 consul 做服务发现
Go 使用 consul 做服务发现 目录 Go 使用 consul 做服务发现 前言 一.目标 二.使用步骤 1. 安装 consul 2. 服务注册 定义接口 具体实现 测试用例 3. 服务发现 ...