正则化,L1,L2
机器学习中在为了减小loss时可能会带来模型容量增加,即参数增加的情况,这会导致模型在训练集上表现良好,在测试集上效果不好,也就是出现了过拟合现象。为了减小这种现象带来的影响,采用正则化。正则化,在减小训练样本误差的同时,限制参数的增长,限制参数过多或者过大,从而提高模型的泛化性。
1. L1 正则化
L1 正则化公式也很简单,直接在原来的损失函数基础上加上权重参数的绝对值:

2. L2 正则化
L2 正则化公式非常简单,直接在原来的损失函数基础上加上权重参数的平方和:
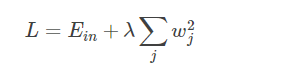
L1范式和L2范式的区别
(1) L1范式是对应参数向量绝对值之和
(2) L1范式具有稀疏性
(3) L1范式可以用来作为特征选择,并且可解释性较强(这里的原理是在实际Loss function 中都需要求最小值,根据L1的定义可知L1最小值只有0,故可以通过这种方式来进行特征选择)
(4) L2范式是对应参数向量的平方和,再求平方根
(5) L2范式是为了防止机器学习的过拟合,提升模型的泛化能力
L2正则 对应的是加入2范数,使得对权重进行衰减,从而达到惩罚损失函数的目的,防止模型过拟合。保留显著减小损失函数方向上的权重,而对于那些对函数值影响不大的权重使其衰减接近于0。相当于加入一个gaussian prior。
L1正则 对应得失加入1范数,同样可以防止过拟合。它会产生更稀疏的解,即会使得部分权重变为0,达到特征选择的效果。相当于加入了一个laplacean prior。
正则化,L1,L2的更多相关文章
- 机器学习 - 正则化L1 L2
L1 L2 Regularization 表示方式: $L_2\text{ regularization term} = ||\boldsymbol w||_2^2 = {w_1^2 + w_2^2 ...
- 正则化 L1 L2
机器学习中几乎都可以看到损失函数后面会添加一个额外项,常用的额外项一般有两种,一般英文称作ℓ1ℓ1-norm和ℓ2ℓ2-norm,中文称作L1正则化和L2正则化,或者L1范数和L2范数. L1正则化和 ...
- 【深度学习】L1正则化和L2正则化
在机器学习中,我们非常关心模型的预测能力,即模型在新数据上的表现,而不希望过拟合现象的的发生,我们通常使用正则化(regularization)技术来防止过拟合情况.正则化是机器学习中通过显式的控制模 ...
- L1正则化比L2正则化更易获得稀疏解的原因
我们知道L1正则化和L2正则化都可以用于降低过拟合的风险,但是L1正则化还会带来一个额外的好处:它比L2正则化更容易获得稀疏解,也就是说它求得的w权重向量具有更少的非零分量. 为了理解这一点我们看一个 ...
- 机器学习之正则化【L1 & L2】
前言 L1.L2在机器学习方向有两种含义:一是L1范数.L2范数的损失函数,二是L1.L2正则化 L1范数.L2范数损失函数 L1范数损失函数: L2范数损失函数: L1.L2分别对应损失函数中的绝对 ...
- L1正则化和L2正则化
L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择 L2正则化可以防止模型过拟合(overfitting):一定程度上,L1也可以防止过拟合 一.L1正则化 1.L1正则化 需注意, ...
- L1正则化与L2正则化的理解
1. 为什么要使用正则化 我们先回顾一下房价预测的例子.以下是使用多项式回归来拟合房价预测的数据: 可以看出,左图拟合较为合适,而右图过拟合.如果想要解决右图中的过拟合问题,需要能够使得 $ ...
- L1,L2范数和正则化 到lasso ridge regression
一.范数 L1.L2这种在机器学习方面叫做正则化,统计学领域的人喊她惩罚项,数学界会喊她范数. L0范数 表示向量xx中非零元素的个数. L1范数 表示向量中非零元素的绝对值之和. L2范数 表 ...
- ML-线性模型 泛化优化 之 L1 L2 正则化
认识 L1, L2 从效果上来看, 正则化通过, 对ML的算法的任意修改, 达到减少泛化错误, 但不减少训练误差的方式的统称 训练误差 这个就损失函数什么的, 很好理解. 泛化错误 假设 我们知道 预 ...
- 机器学习中L1,L2正则化项
搞过机器学习的同学都知道,L1正则就是绝对值的方式,而L2正则是平方和的形式.L1能产生稀疏的特征,这对大规模的机器学习灰常灰常重要.但是L1的求解过程,实在是太过蛋疼.所以即使L1能产生稀疏特征,不 ...
随机推荐
- LIBS入门
样品汽化产生自由原子,原子电子的激发诱导光辐射产生表征原子的分立光谱,采集和分析光辐射. 光源:1064nm Nd:YAG固态激光器,10ns脉冲,焦点光密度1 GW·cm−2 可见和紫外光源. ...
- MOT大连站 | 卓越研发之路:前沿技术落地实践
还在讨论究竟哪种编程语言更容易深度学习?哪种编程语言更具有价值?如果你是资深技术人员又或者是团队负责人,在机器学习.微服务.Spring 5反应式编程等方面遇到了问题,不妨参加一场由msup和微软联合 ...
- (四)juc线程高级特性——线程池 / 线程调度 / ForkJoinPool
13. 线程池 第四种获取线程的方法:线程池,一个 ExecutorService,它使用可能的几个池线程之一执行每个提交的任务,通常使用 Executors 工厂方法配置. 线程池可以解决两个不同问 ...
- jmeter安装与环境变量配置
因jmeter是java开发的,要想运行java开发的程序,必须先下载JDK一.jdk 1.下载jdk jdk下载地址:https://www.oracle.com/technetwork/java ...
- Restful API设计规范
理解RESTful架构 Restful API设计指南 理解RESTful架构 越来越多的人开始意识到,网站即软件,而且是一种新型的软件. 这种"互联网软件"采用客户端/服务器模式 ...
- Recurrent NN vs Recursive NN
https://www.bilibili.com/video/av9770302/?p=8 李宏毅深度学习 图很清楚的反映出两者的不同 Recurrent可以看成Recursive的特殊形式,即以特定 ...
- C#中的double类型数据向SQL sqerver 存储与读取问题
1.存储 由于double类型在SQLsever中并没有对应数据,试过对应float.real类型,发现小数位都存在四舍五入的现象,目前我使用的是decimal类型,用此类型时个人觉得小数位数应该比自 ...
- 报错解决——xcrun: error: invalid active developer path (/Library/Developer/CommandLineTools), missing xcrun at: /Library/Developer/CommandLineTools/usr/bin/xcrun
一般在遇到这个问题的时候都是想用git或者svn,结果发现用不了并报错xcrun: error: invalid active developer path (/Library/Developer/C ...
- sql server 按年月日分组
sql server 按年月日分组 ----------------------------------------------- --author:yangjinwang --date:2017- ...
- Sitecore中Core,Master和Web数据库之间的区别
Core数据库 正如名称所示,Core Database是Sitecore应用程序的主干,它可用于多种用途. 核心数据库包含所有Sitecore设置. 它包含桌面模式,内容编辑器,页面编辑器等的定义. ...