15,scrapy中selenium的应用
引入
在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生如果直接用scrapy对其url发请求,是获取不到那部分动态加载出来的数据值,但是通过观察会发现,通过浏览器进行url请求发送则会加载出对应的动态加载的数据。那么如果我们想要在scrapy也获取动态加载出的数据,则必须使用selenium创建浏览器对象,然后通过该浏览器对象进行请求发送,获取动态加载的数据值。
1,案例分析:
- 需求:爬取网易新闻的国内板块下的新闻数据
- 需求分析:当点击国内超链接进入对应页面时,会发现当前页面展示的新闻数据是被动态加载出来的。需要我们使用selenium实例化一个浏览器对象,在该对象中进行url的请求,获取动态加载的数据。
2,selenium在scrapy中使用的原理分析:
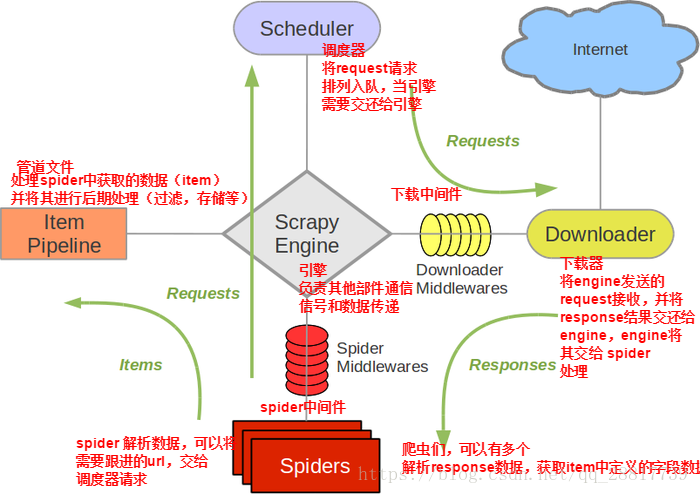
当引擎将国内板块url对应的请求提交给下载器后,下载进行网页数据的下载,然后将下载到的页面数据,封装到response中,提交给引擎,引擎将response在转交给Spiders。Spiders接收到的response对象中存储的页面数据里是没有动态加载的新闻数据的。要想获得动态数据,则需要在下载中间件中对下载器提交给引擎的response响应对象进行拦截,且对其内部存储的页面数据进行篡改,修改成携带了动态加载出的新闻数据,然后将被篡改的response对象最终交给Spiders进行解析操作。
3,selenium在scrapy中的使用流程:
- 重写爬虫文件的构造方法,在该方法中使用selenium实例化一个浏览器对象(因为浏览器对象只需要被实例化一次)
- 重写爬虫文件的closed(self,spider)方法,在其内部关闭浏览器对象。该方法是在爬虫结束时被调用
- 重写下载中间件中的process_response方法,让该方法对响应对象进行拦截,并篡改response中存储的页面数据
- 在配置文件中开启中间件
4,代码展示:
创建项目:
scrapy startproject wangyi
cd wangyi
scrapy genspider wangyinews http://war.163.com scrapy crawl wangyinews 完成代码编写后运行项目
- 爬虫文件:
# -*- coding: utf-8 -*-
import scrapy
from selenium import webdriver class WangyinewsSpider(scrapy.Spider):
name = 'wangyinews'
# allowed_domains = ['http://war.163.com/']
start_urls = ['http://war.163.com/'] def __init__(self):
self.bro = webdriver.Chrome(executable_path=r'E:\Google\Google\Chrome\Application\chromedriver.exe') def parse(self, response):
div_list = response.xpath('//div[@class="data_row news_article clearfix "]')
for div in div_list:
title = div.xpath('.//div[@class="news_title"]/h3/a/text()').extract_first()
print(title) def closed(self, spider):
print('关闭浏览器对象!')
self.bro.quit()
- 中间件文件(只需要修改下载中间件的process_response函数)
from time import sleep
from scrapy import signals
from scrapy.http import HtmlResponse def process_response(self, request, response, spider):
print('即将返回一个新的响应对象!!!')
bro = spider.bro
bro.get(url=request.url)
sleep(3)
page_text = bro.page_source
sleep(3)
return HtmlResponse(url=spider.bro.current_url,body=page_text, encoding='utf-8', request=request)
- setting文件
DOWNLOADER_MIDDLEWARES = {
'wangyi.middlewares.WangyiDownloaderMiddleware': 543,
}
15,scrapy中selenium的应用的更多相关文章
- 15.scrapy中selenium的应用
引入 在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值.但是通过观察我们会发现 ...
- scrapy中selenium的应用
引入 在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值.但是通过观察我们会发现 ...
- scrapy中 selenium(中间件) + 语言处理 +mysql
在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值.但是通过观察我们会发现,通过 ...
- 14 Scrapy中selenium的应用
在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值.但是通过观察我们会发现,通过 ...
- selenium在scrapy中的使用、UA池、IP池的构建
selenium在scrapy中的使用流程 重写爬虫文件的构造方法__init__,在该方法中使用selenium实例化一个浏览器对象(因为浏览器对象只需要被实例化一次). 重写爬虫文件的closed ...
- Scrapy中集成selenium
面对众多动态网站比如说淘宝等,一般情况下用selenium最好 那么如何集成selenium到scrapy中呢? 因为每一次request的请求都要经过中间件,所以写在中间件中最为合适 from se ...
- 在Scrapy中使用selenium
在scrapy中使用selenium 在scrapy中需要获取动态加载的数据的时候,可以在下载中间件中使用selenium 编码步骤: 在爬虫文件中导入webdrvier类 在爬虫文件的爬虫类的构造方 ...
- selenium在scrapy中的应用
引入 在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值.但是通过观察我们会发现 ...
- 第三百五十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—将selenium操作谷歌浏览器集成到scrapy中
第三百五十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—将selenium操作谷歌浏览器集成到scrapy中 1.爬虫文件 dispatcher.connect()信号分发器,第一个参数信 ...
随机推荐
- 去除pycharm的波浪线
PyCharm使用了较为严格的PEP8的检查规则,如果代码命名不规范,甚至多出的空格都会被波浪线标识出来,导致整个编辑器里铺满了波浪线,右边的滚动条也全是黄色或灰色的标记线,很是影响编辑.这里给大家分 ...
- 显示单位px、dip以及sp的区别
dip: Device Independent Pixels(设备独立像素). 不同设备有不同的显示效果,这个和设备硬件有关,一般我们为了支持WVGA.HVGA和QVGA推荐使用这个,不依赖像素. p ...
- redhat配置dns服务器bind
配置Oracle11g的RAC需要使用DNS服务器来解析SCAN IP,本文就是以此为例介绍bind服务器的使用.首先科普一下bind服务器,属于企业级产品了,还是开源的: Bind是Berkeley ...
- 解决在eclipse中导入项目名称已存在的有关问题
新建项目-Import-File System-找到相应的文件夹-Overwrite existing resources without warning打钩,选中项目即可
- php 05
流程控制 一.流程控制 1.顺序结构 //自上而下 从左到右 2.条件分支结构 a. 单向分支结构 if() 只能管理一条指令 这条指令是和他紧跟着的指令 if(){} 只能管理整个花括号里面的代码 ...
- Oracle Form个性化案例(一)
业务场景: 现有Form A,需通过A中的菜单栏中调用另一Form B,需将某值作为参数传入Form B中:
- Eucalyptus常用查询命令
前言: Elastic Utility Computing Architecture for Linking Your Programs To Useful Systems (Eucalyptus) ...
- WIn10 电脑运行Docker
参考地址: https://www.cnblogs.com/linjj/p/5606687.html https://docs.docker.com/engine/reference/commandl ...
- dsniff
/usr/local/sbin/dsniff 这个东西好强大,获取到用户名和密码 bt服务区器上:dsniff -i eth0 -m(自动协议检测) 在另外一个电脑上打开网页,登陆ftp服务器,回头看 ...
- SqlServer查询文件组被占用情况
在SqlServer中,删除一个文件组 alter database [xxxxx] remove filegroup FGMonthTurnIntroduceByMonth13 有时候会遇到如下报错 ...