第三百三十三节,web爬虫讲解2—Scrapy框架爬虫—Scrapy模拟浏览器登录—获取Scrapy框架Cookies
第三百三十三节,web爬虫讲解2—Scrapy框架爬虫—Scrapy模拟浏览器登录
模拟浏览器登录
start_requests()方法,可以返回一个请求给爬虫的起始网站,这个返回的请求相当于start_urls,start_requests()返回的请求会替代start_urls里的请求
Request()get请求,可以设置,url、cookie、回调函数
FormRequest.from_response()表单post提交,第一个必须参数,上一次响应cookie的response对象,其他参数,cookie、url、表单内容等
yield Request()可以将一个新的请求返回给爬虫执行
在发送请求时cookie的操作,
meta={'cookiejar':1}表示开启cookie记录,首次请求时写在Request()里
meta={'cookiejar':response.meta['cookiejar']}表示使用上一次response的cookie,写在FormRequest.from_response()里post授权
meta={'cookiejar':True}表示使用授权后的cookie访问需要登录查看的页面
获取Scrapy框架Cookies
请求Cookie
Cookie = response.request.headers.getlist('Cookie')
print(Cookie)
响应Cookie
Cookie2 = response.headers.getlist('Set-Cookie')
print(Cookie2)
# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request,FormRequest class PachSpider(scrapy.Spider): #定义爬虫类,必须继承scrapy.Spider
name = 'pach' #设置爬虫名称
allowed_domains = ['edu.iqianyue.com'] #爬取域名
# start_urls = ['http://edu.iqianyue.com/index_user_login.html'] #爬取网址,只适于不需要登录的请求,因为没法设置cookie等信息 header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:54.0) Gecko/20100101 Firefox/54.0'} #设置浏览器用户代理 def start_requests(self): #用start_requests()方法,代替start_urls
"""第一次请求一下登录页面,设置开启cookie使其得到cookie,设置回调函数"""
return [Request('http://edu.iqianyue.com/index_user_login.html',meta={'cookiejar':1},callback=self.parse)] def parse(self, response): #parse回调函数 data = { #设置用户登录信息,对应抓包得到字段
'number':'adc8868',
'passwd':'',
'submit':''
} # 响应Cookie
Cookie1 = response.headers.getlist('Set-Cookie') #查看一下响应Cookie,也就是第一次访问注册页面时后台写入浏览器的Cookie
print(Cookie1) print('登录中')
"""第二次用表单post请求,携带Cookie、浏览器代理、用户登录信息,进行登录给Cookie授权"""
return [FormRequest.from_response(response,
url='http://edu.iqianyue.com/index_user_login', #真实post地址
meta={'cookiejar':response.meta['cookiejar']},
headers=self.header,
formdata=data,
callback=self.next,
)]
def next(self,response):
a = response.body.decode("utf-8") #登录后可以查看一下登录响应信息
# print(a)
"""登录后请求需要登录才能查看的页面,如个人中心,携带授权后的Cookie请求"""
yield Request('http://edu.iqianyue.com/index_user_index.html',meta={'cookiejar':True},callback=self.next2)
def next2(self,response):
# 请求Cookie
Cookie2 = response.request.headers.getlist('Cookie')
print(Cookie2) body = response.body # 获取网页内容字节类型
unicode_body = response.body_as_unicode() # 获取网站内容字符串类型 a = response.xpath('/html/head/title/text()').extract() #得到个人中心页面
print(a)
模拟浏览器登录2
第一步、
爬虫的第一次访问,一般用户登录时,第一次访问登录页面时,后台会自动写入一个Cookies到浏览器,所以我们的第一次主要是获取到响应Cookies
首先访问网站的登录页面,如果登录页面是一个独立的页面,我们的爬虫第一次应该从登录页面开始,如果登录页面不是独立的页面如 js 弹窗,那么我们的爬虫可以从首页开始
# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request,FormRequest
import re class PachSpider(scrapy.Spider): #定义爬虫类,必须继承scrapy.Spider
name = 'pach' #设置爬虫名称
allowed_domains = ['dig.chouti.com'] #爬取域名
# start_urls = [''] #爬取网址,只适于不需要登录的请求,因为没法设置cookie等信息 header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:54.0) Gecko/20100101 Firefox/54.0'} #设置浏览器用户代理 def start_requests(self):
"""第一次请求一下登录页面,设置开启cookie使其得到cookie,设置回调函数"""
return [Request('http://dig.chouti.com/',meta={'cookiejar':1},callback=self.parse)] def parse(self, response):
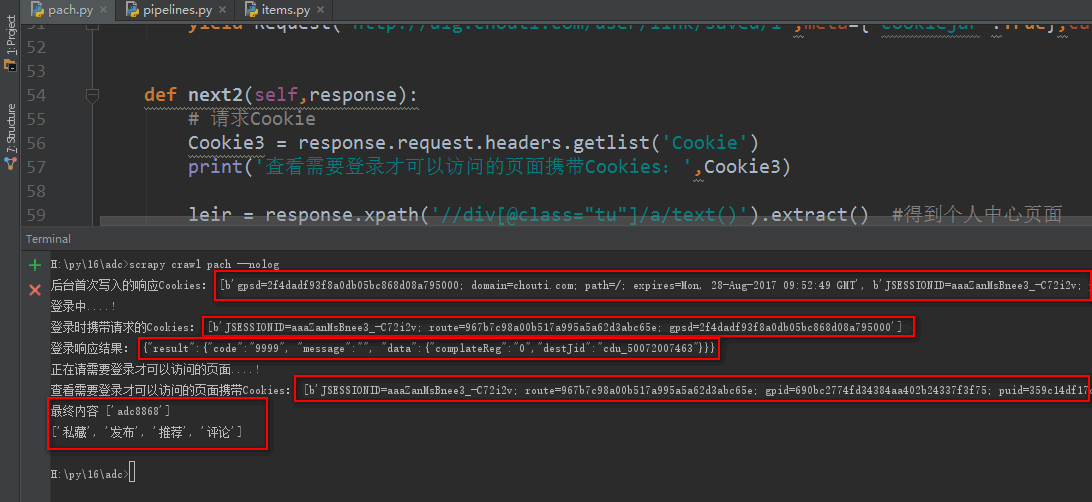
# 响应Cookies
Cookie1 = response.headers.getlist('Set-Cookie') #查看一下响应Cookie,也就是第一次访问注册页面时后台写入浏览器的Cookie
print('后台首次写入的响应Cookies:',Cookie1) data = { # 设置用户登录信息,对应抓包得到字段
'phone': '',
'password': '',
'oneMonth': ''
} print('登录中....!')
"""第二次用表单post请求,携带Cookie、浏览器代理、用户登录信息,进行登录给Cookie授权"""
return [FormRequest.from_response(response,
url='http://dig.chouti.com/login', #真实post地址
meta={'cookiejar':response.meta['cookiejar']},
headers=self.header,
formdata=data,
callback=self.next,
)] def next(self,response):
# 请求Cookie
Cookie2 = response.request.headers.getlist('Cookie')
print('登录时携带请求的Cookies:',Cookie2) jieg = response.body.decode("utf-8") #登录后可以查看一下登录响应信息
print('登录响应结果:',jieg) print('正在请需要登录才可以访问的页面....!') """登录后请求需要登录才能查看的页面,如个人中心,携带授权后的Cookie请求"""
yield Request('http://dig.chouti.com/user/link/saved/1',meta={'cookiejar':True},callback=self.next2) def next2(self,response):
# 请求Cookie
Cookie3 = response.request.headers.getlist('Cookie')
print('查看需要登录才可以访问的页面携带Cookies:',Cookie3) leir = response.xpath('//div[@class="tu"]/a/text()').extract() #得到个人中心页面
print('最终内容',leir)
leir2 = response.xpath('//div[@class="set-tags"]/a/text()').extract() # 得到个人中心页面
print(leir2)
第三百三十三节,web爬虫讲解2—Scrapy框架爬虫—Scrapy模拟浏览器登录—获取Scrapy框架Cookies的更多相关文章
- 十二 web爬虫讲解2—Scrapy框架爬虫—Scrapy模拟浏览器登录—获取Scrapy框架Cookies
模拟浏览器登录 start_requests()方法,可以返回一个请求给爬虫的起始网站,这个返回的请求相当于start_urls,start_requests()返回的请求会替代start_urls里 ...
- 第三百二十三节,web爬虫,scrapy模块以及相关依赖模块安装
第三百二十三节,web爬虫,scrapy模块以及相关依赖模块安装 当前环境python3.5 ,windows10系统 Linux系统安装 在线安装,会自动安装scrapy模块以及相关依赖模块 pip ...
- 第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作
第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作 注意:前面讲到的各种操作都是一次http请求操作一条数据,如果想 ...
- 第三百五十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy的暂停与重启
第三百五十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy的暂停与重启 scrapy的每一个爬虫,暂停时可以记录暂停状态以及爬取了哪些url,重启时可以从暂停状态开始爬取过的UR ...
- 第三百八十三节,Django+Xadmin打造上线标准的在线教育平台—第三方模块django-simple-captcha验证码
第三百八十三节,Django+Xadmin打造上线标准的在线教育平台—第三方模块django-simple-captcha验证码 下载地址:https://github.com/mbi/django- ...
- 第三百七十三节,Django+Xadmin打造上线标准的在线教育平台—创建用户app,在models.py文件生成3张表,用户表、验证码表、轮播图表
第三百七十三节,Django+Xadmin打造上线标准的在线教育平台—创建用户app,在models.py文件生成3张表,用户表.验证码表.轮播图表 创建Django项目 项目 settings.py ...
- 第三百三十六节,web爬虫讲解2—urllib库中使用xpath表达式—BeautifulSoup基础
第三百三十六节,web爬虫讲解2—urllib库中使用xpath表达式—BeautifulSoup基础 在urllib中,我们一样可以使用xpath表达式进行信息提取,此时,你需要首先安装lxml模块 ...
- 第三百三十五节,web爬虫讲解2—Scrapy框架爬虫—豆瓣登录与利用打码接口实现自动识别验证码
第三百三十五节,web爬虫讲解2—Scrapy框架爬虫—豆瓣登录与利用打码接口实现自动识别验证码 打码接口文件 # -*- coding: cp936 -*- import sys import os ...
- 第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息
第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息 crapy爬取百度新闻,爬取Ajax动态生成的信息,抓取百度新闻首页的新闻rul地址 有多 ...
随机推荐
- java: 保留两位小数4种方法
import java.math.BigDecimal; import java.text.DecimalFormat; import java.text.NumberFormat; public c ...
- Apache Flink Training and sample code
http://training.data-artisans.com/ https://github.com/dataArtisans/blog-post-code-samples https://gi ...
- 每日英语:Can Robots Better Spot Terrorists at Airports?
Next to have their jobs automated: airport-security screeners? Aviation and government authorities a ...
- 使用SpringBoot的yml文件配置时踩的一个坑
问题描述:使用SpringBoot整合redis进行yml配置的时候,启动工程报错,提示加载application.yml配置文件失败: ::27.430 [main] ERROR org.sprin ...
- 【Java】PreparedStatement VS Statement
创建时: Statement statement = conn.createStatement(); PreparedStatement preStatement = conn.prepareS ...
- spring 强制采用cglib进行代理
spring对AOP的支持 *如果目标对象实现了接口,默认情况下会采用JDK的动态代理实现AOP* 如果目标对象实现了接口,可以强制使用CGLIB实现AOP*如果目标对象没有实现了接口,必须采用CGL ...
- chmod 权限 命令详细用法
指令名称 : chmod 使用权限 : 所有使用者 使用方式 : chmod [-cfvR] [--help] [--version] mode file... 说明 : Linux/Unix 的档案 ...
- PHP重载以及Laravel门面Facade
目录 重载的概念 魔术方法中的重载 属性重载 方法重载 Laravel中的Facade 扩展 谈谈__invoke Laravel提供了许多易用的Facade,让我们用起来特步顺手,那么这些Facad ...
- [mount]linux 挂载时 mount: wrong fs type, bad option, bad superblock on /dev/sdb
原因:挂载时未格式化,使用的文件系统格式不对 解决方案:格式化 sudo mkfs -t ext4 /dev/sdb 再挂载 sudo mount /dev/sdb /xxx/ 用df -h检查,发现 ...
- 【进阶修炼】——改善C#程序质量(7)
113,声明变量时考虑最大值. Ushort的最大值是65535,用于不同的用途这个变量可能发生溢出,所以设计时应充分了解每个变量的最大值. 114,MD5不再安全. MD5多用于信息完整性的校验.R ...