大数据相关概念和hdfs
大数据
概述
大数据是新处理模式才能具备更多的决策力,洞察力,流程优化能力,来适应海量高增长率,多样化的数据资产。
大数据面临的问题
- 怎么存储海量数据(kb,mb,gb,tb,pb,eb,zb)
- 怎么对数据进行降噪处理(对数据进行清洗,使得数据变废为宝,提取有用的数据,减少不必要的数据资源空间的释放)
处理方案
- hadoop 是一种分布式文件存储系统来解决存储的问题,其中hdfs用来解决数据存储问题,mapReduce来解决如何进行建造处理
hadoop是什么?
由来?
根据google发布的3篇文章
google File System
Google MapReduce 获得启发 hadoop之父 Doug Cutting 用java语言解决大数据所面临的问题
- 概述
- hadoop 是apache基金会的一款开源的分布式的基础架构,它实现了高容错率,乃至高吞吐量,低成本,由于hadoop用java语言编写可以用在linux是非常可靠的,hadoop核心设计是hdfs和mapReudce以及Hbase分别对应这又google3篇文章,解决了大数据所面临的问题
- hdfs 分布式文件存储系统
- mapreduce 分布式计算框架 只需要少量的java代码 就能实现分布式计算
- hbase 基于HDFS 的列式存储的NoSql
- hadoop 是apache基金会的一款开源的分布式的基础架构,它实现了高容错率,乃至高吞吐量,低成本,由于hadoop用java语言编写可以用在linux是非常可靠的,hadoop核心设计是hdfs和mapReudce以及Hbase分别对应这又google3篇文章,解决了大数据所面临的问题
- hdfs
- 分布式文件存储系统,其中有nameNode,dataNode,block,nameNode负责管理着dataNode,dataNode负责接收读写请求和nameNode协调工作,负责block快的创建和复制,nameNode存储着元数据,datanode和block中的映射关系
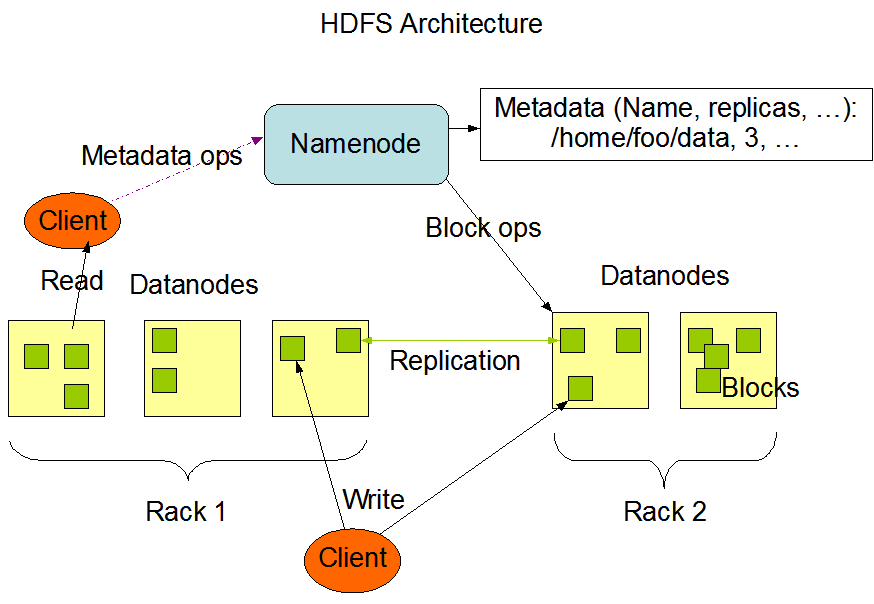
- nameNode 存储元数据 (用来描述数据的数据),负责管理dataNode 与dataNode 协调
- dataNode 负责nameNode的读写请求,用来存储数据块的节点,向nameNode报告自己的快信息
- block 数据快 hdfs 最小默认128mb 为一块,没一块默认有3个副本
- rack 机架 用来放置存储节点,提高容错率,高吞吐量。优化存储和计算
nameNode和SecondaryNameNode 之间的关系

fsimage 元数据的备份 会被加载到内存当中去
edits 读写请求的日志文件
nameNode 会在启动的时候加载 fsimage 和 edits ,这2个文件不会凭空出现,所以要格式化nameNode
当用户在操作文件时,由于edits的增加,导致了nameNode启动会越来越慢,所以就出现了SecondaryNameNode 可以简单来说,他是nameNode的一个副本,当到达检查点的时候,也就是hdfs 默认 1个小时 或者 日志操作量级达到100w条的时候,此时SecondaryNameNode会将fsimage和edits加载过来进行合并,此时,若是有读写请求过来的时候会被加载到一个叫edits-inprogess的文件进行记录读写请求,fsimage和edits合并之后会成为一个新的fsimage,而此时edits-inprogess会改名为edits
- 小问题 : 为什么 一个块的大小默认是128mb
- 在hadoop 1x 的时候默认快的大小为64 但是随着硬盘的变大 在hadoop2x的时候 快的大小 变成了128m ,此时默认最佳状态是寻址时间是传输速度的100/1
- 小问题 : 为什么 一个块的大小默认是128mb
- mapReduce
- 概念 : 分布式计算框架。用于大规模的数据计算,采用并行计算,充分的利用了dataNode的物理存储机制,采用了(Map)映射(Reduce)规约,他极大的方便了程序员不会分布式并行编程的情况下,将自己的程序运行在分布式系统上 ,思想就是 将一个键值对 放在map 里 然后 使用Reduce 进行统筹规划,保证所有的映射的键值队中每一个共享的键组
- mapReduce最擅长做的就是分而治之 ;
- 分 就是把一个庞大复杂的任务分解成若干个简单的任务来处理,简单的任务包含有3层
- 相对于原来的数据要大大缩小
- 所有的任务中并行计算,且互不干扰
- 就近计算原则
- 治之 Reduce 负责对map计算的结果进行统筹汇总
- 要实现mapReduce 首先得借助一个资源调度平台 Yarn
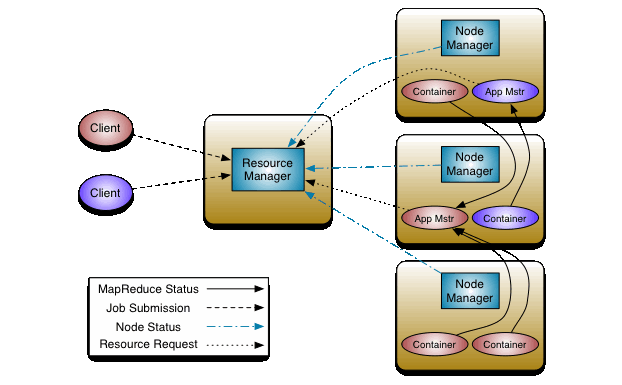
- Yarn
- 概念 Yarn 作为资源调度平台 ,其中有一个最大的管理者,ResourceManager 负责着资源的统筹分配,还有各个节点的管理着,NodeManager 负责向ResourceManager进行资源状态的报告,在NodeManager 中还有一个 MRAppMaster ,负责 申请计算资源,协调计算任务并和NodeManager一起执行监视任务
- ResourceManager 负责对集群的整体资源和计算做统筹规划
- NodeManager 管理主机上的计算组员,负责报告自身的状态信息
- MRAppMaster 负责向ResourceManager负责申请资源,协调计算任务
- YarnChild 做实际的计算任务
- Container 计算资源的抽象单位
大数据相关概念和hdfs的更多相关文章
- 《OD大数据实战》HDFS入门实例
一.环境搭建 1. 下载安装配置 <OD大数据实战>Hadoop伪分布式环境搭建 2. Hadoop配置信息 1)${HADOOP_HOME}/libexec:存储hadoop的默认环境 ...
- 大数据 --> 分布式文件系统HDFS的工作原理
分布式文件系统HDFS的工作原理 Hadoop分布式文件系统(HDFS)是一种被设计成适合运行在通用硬件上的分布式文件系统.HDFS是一个高度容错性的系统,适合部署在廉价的机器上.它能提供高吞吐量的数 ...
- 大数据小白系列——HDFS(4)
这里是大数据小白系列,这是本系列的第四篇,来看一个真实世界Hadoop集群的规模,以及我们为什么需要Hadoop Federation. 首先,我们先要来个直观的印象,这是你以为的Hadoop集群: ...
- 大数据小白系列——HDFS(3)
这里是大数据小白系列,这是本系列的第三篇,介绍HDFS中NameNode选举,JournalNode等概念. 上一期我们说到了为解决NameNode(下称NN)单点失败问题,HDFS中使用了双NN的机 ...
- 大数据小白系列——HDFS(2)
这里是大数据小白系列,这是本系列的第二篇,介绍一下HDFS中SecondaryNameNode.单点失败(SPOF).以及高可用(HA)等概念. 上一篇我们说到了大数据.分布式存储,以及HDFS中的一 ...
- 大数据小白系列——HDFS(1)
[注1:结尾有大福利!] [注2:想写一个大数据小白系列,介绍大数据生态系统中的主要成员,理解其原理,明白其用途,万一有用呢,对不对.] 大数据是什么?抛开那些高大上但笼统的说法,其实大数据说的是两件 ...
- 大数据入门第六天——HDFS详解
一.概述 1.HDFS中的角色 Block数据: HDFS中的文件在物理上是分块存储(block),块的大小可以通过配置参数( dfs.blocksize)来规定,默认大小在hadoop2.x版本中是 ...
- 大数据基础总结---HDFS分布式文件系统
HDFS分布式文件系统 文件系统的基本概述 文件系统定义:文件系统是一种存储和组织计算机数据的方法,它使得对其访问和查找变得容易. 文件名:在文件系统中,文件名是用于定位存储位置. 元数据(Metad ...
- Hadoop大数据平台入门——HDFS和MapReduce
随着硬件水平的不断提高,需要处理数据的大小也越来越大.大家都知道,现在大数据有多火爆,都认为21世纪是大数据的世纪.当然我也想打上时代的便车.所以今天来学习一下大数据存储和处理. 随着数据的不断变大, ...
随机推荐
- 图解leetcode —— 128. 最长连续序列
前言: 每道题附带动态示意图,提供java.python两种语言答案,力求提供leetcode最优解. 描述: 给定一个未排序的整数数组,找出最长连续序列的长度. 要求算法的时间复杂度为 O(n). ...
- python多线程编程-queue模块和生产者-消费者问题
摘录python核心编程 本例中演示生产者-消费者模型:商品或服务的生产者生产商品,然后将其放到类似队列的数据结构中.生产商品中的时间是不确定的,同样消费者消费商品的时间也是不确定的. 使用queue ...
- python基础之字符串讲解(上)
字符串 字符串是 Python 中最常用的数据类型.我们可以使用引号('或者")来创建字符串. 创建字符串很简单,只要为变量分配一个值即可.For example: 为str输入一个变量,p ...
- laravel身份验证-Auth的使用
laravel自带了auth类和User模型来帮助我们很方便的实现用户登陆.判断.首先,先配置一下相关参数 app/config/auth.php: model 指定模型table 指定用户表这里我只 ...
- Spring Cloud Finchley.SR1 版本的坑:placeholer占位符无法解析!
接入nacos 之后,想把所有的配置丢上去. 启动程序是: @EnableDiscoveryClient @RestController @ComponentScan(basePackages = { ...
- Spring Cloud进阶之路 | 一:服务注册与发现(nacos)
转载请注明作者及出处: 作者:银河架构师 原文链接:https://www.cnblogs.com/luas/p/12068846.html 1.版本 最新稳定版本为1.1.4,也可以从发版说明.博客 ...
- RabbitMQ异常注意 reply-code=404, reply-text=NOT_FOUND - no exchange 'topic' in vhost '/', class-id=50, method-id=
第一次,一定要先启动Provider再启动Consumer!!! rabbitmq为初始状态没有队列信息,然后我又没有启动consumer,所以导致provider找不到queue和exchange. ...
- 初窥R(基本说明、获取帮助、工作空间、输入输出、包)
本篇简要介绍使用R的一些基本概念,包括基本说明.获取帮助.工作空间.输入输出,每个知识点中都会通过一个例子来练习. 一.R基本情况说明 1.R是一种区分大小写的解释性语言. 2.控制台默认使用命令提示 ...
- library: Vulnhub Walkthrough
网络主机探测: 端口主机扫描: ╰─ nmap -p1-65535 -sV -A -O -sT 10.10.202.136 21/tcp open ftp vsftpd 3.0.380/tcp ope ...
- ORM映射(对象关系映射)
ORM映射(对象关系映射)分创建表和操作表两个部分创建单表创建关联表(foreignKey) 一对一 一对多(重点) 多对多(重点) 创建表后加str方法把打印的地址转换成对应字符表的操作(增删改查) ...