Python selenium+phantomjs的js动态爬取
Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE、Mozilla Firefox、Chrome等。
Phantom JS是一个服务器端的 JavaScript API 的 WebKit。其支持各种Web标准: DOM 处理, CSS 选择器, JSON, Canvas, 和 SVG。
基于js动态加载内容爬取的另一种方法——模拟浏览器
安装过程略。
下面写上最简单基础的
from selenium import webdriver
driver = webdriver.PhantomJS()
driver.get('http://www.baidu.com/')
print driver.title
driver.quit()
输出结果:
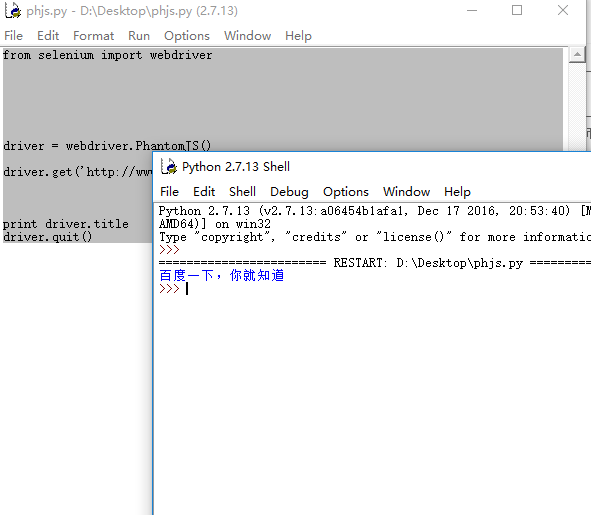
这样最基本的实现能解决了。
参考
http://www.cnblogs.com/front-Thinking/p/4321720.html
http://blog.csdn.net/qinglu000/article/details/52240508
——————
遇到问题————phantomjs没有输出,输出看不到内容
fromseleniumimportwebdriver importsys
reload(sys)
sys.setdefaultencoding('utf-8') driver=webdriver.PhantomJS() #这要可能需要制定phatomjs可执行文件的位置
driver.get("http://www.ip.cn/125.95.26.81")
#print driver.current_url
#print driver.page_source
printdriver.find_element_by_id('result').text.split('\n')[0].split('来自:')[1]
driver.quit
就是像开始因为编码问题加入这几行代码,输出看不到内容,一直以为哪里出错了,一番折腾删除后正常显示。
importsys
reload(sys)
sys.setdefaultencoding('utf-8')
Python selenium+phantomjs的js动态爬取的更多相关文章
- 学习用java基于webMagic+selenium+phantomjs实现爬虫Demo爬取淘宝搜索页面
由于业务需要,老大要我研究一下爬虫. 团队的技术栈以java为主,并且我的主语言是Java,研究时间不到一周.基于以上原因固放弃python,选择java为语言来进行开发.等之后有时间再尝试pytho ...
- Python爬虫(二十)_动态爬取影评信息
本案例介绍从JavaScript中采集加载的数据.更多内容请参考:Python学习指南 #-*- coding:utf-8 -*- import requests import re import t ...
- python爬虫:了解JS加密爬取网易云音乐
python爬虫:了解JS加密爬取网易云音乐 前言 大家好,我是"持之以恒_liu",之所以起这个名字,就是希望我自己无论做什么事,只要一开始选择了,那么就要坚持到底,不管结果如何 ...
- Node.js 爬虫爬取电影信息
Node.js 爬虫爬取电影信息 我的CSDN地址:https://blog.csdn.net/weixin_45580251/article/details/107669713 爬取的是1905电影 ...
- Python爬虫学习三------requests+BeautifulSoup爬取简单网页
第一次第一次用MarkDown来写博客,先试试效果吧! 昨天2018俄罗斯世界杯拉开了大幕,作为一个伪球迷,当然也得为世界杯做出一点贡献啦. 于是今天就编写了一个爬虫程序将腾讯新闻下世界杯专题的相关新 ...
- 初识python 之 爬虫:使用正则表达式爬取“糗事百科 - 文字版”网页数据
初识python 之 爬虫:使用正则表达式爬取"古诗文"网页数据 的兄弟篇. 详细代码如下: #!/user/bin env python # author:Simple-Sir ...
- selenium模块获得js动态数据-17track为例
通过selenium模块驱动Chrome浏览器,获得js动态数据,以17track为例:通过运单号查询最新的物流信息 1 import re 2 from time import sleep 3 fr ...
- python+selenium+PhantomJS爬取网页动态加载内容
一般我们使用python的第三方库requests及框架scrapy来爬取网上的资源,但是设计javascript渲染的页面却不能抓取,此时,我们使用web自动化测试化工具Selenium+无界面浏览 ...
- python+selenium实现动态爬取及selenuim的常用操作
应用实例可以参考博客中的12306自动抢票应用 https://www.cnblogs.com/mumengyun/p/10001109.html 动态网页数据抓取 什么是AJAX: AJAX(Asy ...
随机推荐
- Linux搭建nginx负载均衡(两台服务器之间)
负载均衡种类 第一种:通过硬件负载解决,常见的有NetScaler.F5.Radware和Array等商用的负载均衡器,价格比较昂贵 第二种:通过软件负载解决,常见的软件有LVS.Nginx.apac ...
- Codeforces Round #465 &935C. Fifa and Fafa计算几何
传送门 题意:在平面中,有一个圆,有一个点,问能在这个圆中围出最大的圆的圆心坐标和半径.要求这个最大圆不包含这个点. 思路:比较基础的计算几何,要分三种情况,第一种就是这个点在圆外的情况.第二种是点在 ...
- CodeForces 779D. String Game(二分答案)
题目链接:http://codeforces.com/problemset/problem/779/D 题意:有两个字符串一个初始串一个目标串,有t次机会删除初始串的字符问最多操作几次后刚好凑不成目标 ...
- NPOI导出Excel封装
直接上代码 public class ExcelUtils { public static ICellStyle CreateStyle(IWorkbook workbook, string font ...
- CSS动效集锦,视觉魔法的碰撞与融合(二)
引言 长久以来,我认识到.CSS,是存在极限的.正如曾经替你扛下一切的那个男人,也总有他眼含热泪地拼上一切,却也无法帮你做到的事情,他只能困窘地让你看到他的无能为力,怅然若失. 然后和曾经他成长的时代 ...
- 全网最实用的 Debug调试技巧汇总-Python大佬偷偷使用的神技
一.思考❓❔ 1.什么是debug? 找茬 找软件的茬 发现程序的缺陷 2.为什么需要debug? 谁都不敢保证,写的代码没有任何问题 高效查找软件异常 一位优秀的开发工程师 20%的时间写代码 80 ...
- centos7 kubernetes单机安装
单机版的kubernetes 适合初学者,对kuber有个很好的入门. 因为centos系统内置了安装源.我们可以直接安装 1.yum install -y etco kubernetes 2.whe ...
- jinfo Java配置信息工具
jinfo(Configuration info for Java) jinfo的作用是实时地查看和调整虚拟机各项参数. jinfo 命令格式: jinfo [ option ] pid pid是虚拟 ...
- ImageView的功能和使用
ImageView继承自View类,它的功能用于显示图片, 或者显示Drawable对象 xml属性: src和background区别 参考:http://hi.baidu.com/sunboy_2 ...
- CAS ABA问题
java.util.concurrent包的最底层基础CAS技术,原理很简单. CAS有3个操作数,内存值V,旧的预期值A,要修改的新值B.当且仅当预期值A和内存值V相同时,将内存值V修改为B,否则什 ...