【赵渝强老师】在MongoDB中使用MapReduce方式计算聚合

MapReduce 能够计算非常复杂的聚合逻辑,非常灵活,但是,MapReduce非常慢,不应该用于实时的数据分析中。MapReduce能够在多台Server上并行执行,每台Server只负责完成一部分wordload,最后将wordload发送到Master Server上合并,计算出最终的结果集,返回客户端。
MapReduce的基本思想,如下图所示:
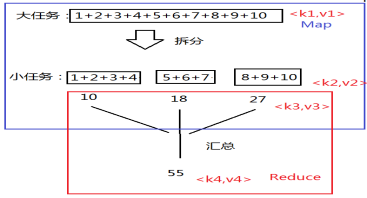
在这个例子中,我们以一个求和为例。首先执行Map阶段,把一个大任务拆分成若干个小任务,每个小任务运行在不同的节点上,从而支持分布式计算,这个阶段叫做Map(如蓝框所示);每个小任务输出的结果再进行二次计算,最后得到结果55,这个阶段叫做Reduce(如红框所示)。
使用MapReduce方式计算聚合,主要分为三步:Map,Shuffle(拼凑)和Reduce,Map和Reduce需要显式定义,shuffle由MongoDB来实现。
- Map:将操作映射到每个doc,产生Key和Value
- Shuffle:按照Key进行分组,并将key相同的Value组合成数组
- Reduce:把Value数组化简为单值
我们以下面的测试数据(员工数据)为例,来为大家演示。
db.emp.insert(
[
{_id:7369,ename:'SMITH' ,job:'CLERK' ,mgr:7902,hiredate:'17-12-80',sal:800,comm:0,deptno:20},
{_id:7499,ename:'ALLEN' ,job:'SALESMAN' ,mgr:7698,hiredate:'20-02-81',sal:1600,comm:300 ,deptno:30},
{_id:7521,ename:'WARD' ,job:'SALESMAN' ,mgr:7698,hiredate:'22-02-81',sal:1250,comm:500 ,deptno:30},
{_id:7566,ename:'JONES' ,job:'MANAGER' ,mgr:7839,hiredate:'02-04-81',sal:2975,comm:0,deptno:20},
{_id:7654,ename:'MARTIN',job:'SALESMAN' ,mgr:7698,hiredate:'28-09-81',sal:1250,comm:1400,deptno:30},
{_id:7698,ename:'BLAKE' ,job:'MANAGER' ,mgr:7839,hiredate:'01-05-81',sal:2850,comm:0,deptno:30},
{_id:7782,ename:'CLARK' ,job:'MANAGER' ,mgr:7839,hiredate:'09-06-81',sal:2450,comm:0,deptno:10},
{_id:7788,ename:'SCOTT' ,job:'ANALYST' ,mgr:7566,hiredate:'19-04-87',sal:3000,comm:0,deptno:20},
{_id:7839,ename:'KING' ,job:'PRESIDENT',mgr:0,hiredate:'17-11-81',sal:5000,comm:0,deptno:10},
{_id:7844,ename:'TURNER',job:'SALESMAN' ,mgr:7698,hiredate:'08-09-81',sal:1500,comm:0,deptno:30},
{_id:7876,ename:'ADAMS' ,job:'CLERK' ,mgr:7788,hiredate:'23-05-87',sal:1100,comm:0,deptno:20},
{_id:7900,ename:'JAMES' ,job:'CLERK' ,mgr:7698,hiredate:'03-12-81',sal:950,comm:0,deptno:30},
{_id:7902,ename:'FORD' ,job:'ANALYST' ,mgr:7566,hiredate:'03-12-81',sal:3000,comm:0,deptno:20},
{_id:7934,ename:'MILLER',job:'CLERK' ,mgr:7782,hiredate:'23-01-82',sal:1300,comm:0,deptno:10}
]
);
(案例一)求员工表中,每种职位的人数
var map1=function(){emit(this.job,1)}
var reduce1=function(job,count){return Array.sum(count)}
db.emp.mapReduce(map1,reduce1,{out:"mrdemo1"})
(案例二)求员工表中,每个部门的工资总和
var map2=function(){emit(this.deptno,this.sal)}
var reduce2=function(deptno,sal){return Array.sum(sal)}
db.emp.mapReduce(map2,reduce2,{out:"mrdemo2"})
(案例三)Troubleshoot the Map Function
定义自己的emit函数:
var emit = function(key, value) {
print("emit");
print("key: " + key + " value: " + tojson(value));
} 测试一条数据:
emp7839=db.emp.findOne({_id:7839})
map2.apply(emp7839)
输出以下结果:
emit
key: 10 value: 5000 测试多条数据:
var myCursor=db.emp.find()
while (myCursor.hasNext()) {
var doc = myCursor.next();
print ("document _id= " + tojson(doc._id));
map2.apply(doc);
print();
}
(案例四)Troubleshoot the Reduce Function
一个简单的测试案例
var myTestValues = [ 5, 5, 10 ];
var reduce1=function(key,values){return Array.sum(values)}
reduce1("mykey",myTestValues) 测试:Reduce的value包含多个值
测试数据:薪水、奖金:
var myTestObjects = [
{ sal: 1000, comm: 5 },
{ sal: 2000, comm: 10 },
{ sal: 3000, comm: 15 }
];
开发reduce方法:
var reduce2=function(key,values) {
reducedValue = { sal: 0, comm: 0 };
for(var i=0;i<values.length;i++) {
reducedValue.sal += values[i].sal;
reducedValue.comm += values[i].comm;
}
return reducedValue;
} 测试:
reduce2("aa",myTestObjects)
【赵渝强老师】在MongoDB中使用MapReduce方式计算聚合的更多相关文章
- 【转载】MongoDB中的MapReduce 高级操作介绍
转载自残缺的孤独 1.概述 MongoDB中的MapReduce相当于关系数据库中的group by.使用MapReduce要实现两个函数Map和Reduce函数.Map函数调用emit(key,va ...
- MongoDB中的MapReduce介绍与使用
一.简介 在用MongoDB查询返回的数据量很大的情况下,做一些比较复杂的统计和聚合操作做花费的时间很长的时候,可以用MongoDB中的MapReduce进行实现 MapReduce是个非常灵活和强大 ...
- MongoDB中通过MapReduce实现合计Sum功能及返回格式不一致问题分析
建立下述测试数据,通过MapReduce统计每个班级学生数及成绩和. 代码如下: public string SumStudentScore() { var collection = _dataBas ...
- 在MongoDB中实现聚合函数 (转)
随着组织产生的数据爆炸性增长,从GB到TB,从TB到PB,传统的数据库已经无法通过垂直扩展来管理如此之大数据.传统方法存储和处理数据的成本将会随着数据量增长而显著增加.这使得很多组织都在寻找一种经济的 ...
- MongoDB中MapReduce介绍与使用
一.简介 在用MongoDB查询返回的数据量很大的情况下,做一些比较复杂的统计和聚合操作做花费的时间很长的时候,可以用MongoDB中的MapReduce进行实现 MapReduce是个非常灵活和强大 ...
- 在MongoDB中实现聚合函数
在MongoDB中实现聚合函数 随着组织产生的数据爆炸性增长,从GB到TB,从TB到PB,传统的数据库已经无法通过垂直扩展来管理如此之大数据.传统方法存储和处理数据的成本将会随着数据量增长而显著增加. ...
- 部署mongodb中需要注意的调参
部署mongodb的生产服务器,给出如下相关建议: 使用虚拟化环境: 系统配置 1)推荐RAID配置 RAID(Redundant Array of Independent Disk,独立磁盘冗余阵列 ...
- 201871010136—赵艳强《面向对象程序设计(java)》第十三周学习总结
201871010136—赵艳强<面向对象程序设计(java)>第十三周学习总结 博文正文开头格式:(2分) 项目 内容 <面向对象程序设计(java)> https:// ...
- MongoDB中的数据类型
mongoDB中存储的数据单元被称作文档.文档的格式与JSON很类似,只不过由于JSON表达的数据类型范围太小(null,boolean,numeric,string和object),mongoDB对 ...
- java中使用mongodb的几种方式
最近有时间看了一下mongodb,因为mongodb更容易扩展所以考虑使用mongodb来保存数据. 首先下载安装mongodb,这是很简单的,装好后使用mongod命令就可以启动数据库.正式部署的话 ...
随机推荐
- FusionAccess liteAD
回车回车 fusion access完成 进入access网页 https://IP:8443进入web网页 输入用户名:admin:密码:IaaS@PORTAL-CLOUD8! 输入完账号密码后改密 ...
- python raise异常处理
python raise异常处理 一般最简单的异常处理是try except: try: f = open('test.txt') except Exception as e: print(e) f ...
- 《Python数据可视化之matplotlib实践》 源码 第一篇 入门 第一章
最近手上有需要用matplotlib画图的活,在网上淘了本实践书,发现没有代码,于是手敲了一遍,mark下. 第一篇 第一章 图1.1 import matplotlib.pyplot as p ...
- 标准DQN在测试算法性能时为什么要将探索概率epsilon设置为0.05呢,而不是使用其他探索概率的epsilon-greedy策略或者直接使用greedy探索策略呢?
标准dqn的策略网络参数更新所采用的规则为Q-learning中的更新规则,总所周知的是Q-learning是异策略算法,异策略算法就是行为策略和评估策略(更新所得策略)是不同的. 更新规则: q-l ...
- java Hutool工具类之Excel的操作
1.背景 程序中上传下载excel是家常便饭,因此hutool给我们提供了非充强大的工具类,使用如下...... 2.使用 官方地址:https://hutool.cn/docs/#/poi/Exce ...
- grpc断路器之hystrix
上一章介绍了grpc断路器sentinel, grpc断路器之sentinel 但是由于公司线上系统用的告警与监控组件是prometheus,而sentinel暂时还没有集成prometheus,所以 ...
- 微服务全链路跟踪:grpc集成zipkin
微服务全链路跟踪:grpc集成zipkin 微服务全链路跟踪:grpc集成jaeger 微服务全链路跟踪:springcloud集成jaeger 微服务全链路跟踪:jaeger集成istio,并兼容u ...
- 远程采集服务器指标信息(一) 远程通过SSH执行命令
远程采集服务器信息,比如说磁盘信息.内存信息. 现介绍java通过SSH执行命令采集服务器信息,比如说执行df.ls.top. /** * * SSH远程执行shell类 */ public clas ...
- sc2 天梯地图
没记错的话以前 7 张 ban 3 张,非常合理,现在 9 张怎么还是 ban 3 张 好哥哥达蒙星际2教学 Goldenaura ban 三四矿近,挂运输机的地方长,架坦克的点位多,ZvT 打不了一 ...
- 22.11.20 ICPC合肥站 打星记录
A,B,H签到. B题:注意区分相对误差与绝对误差!!小数相对误差小于1e-6,至少要输出十二位! G题优先队列.场上十几分钟就想出来了,表扬自己一波,留个坑位写题解. M题情况不多直接暴搜, 最后一 ...