[python爬虫]爬取学校教务处成绩
学校教务处网站
登陆窗口
表单数据
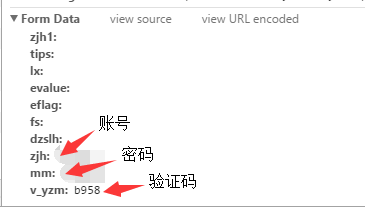
观察登陆窗口和提交的表单数据可知只要将账号、密码、验证码正确赋值提交即可模拟登陆。
账号和密码都有,问题的关键就在验证码上。
右键验证码图片审查观察源码如下图:
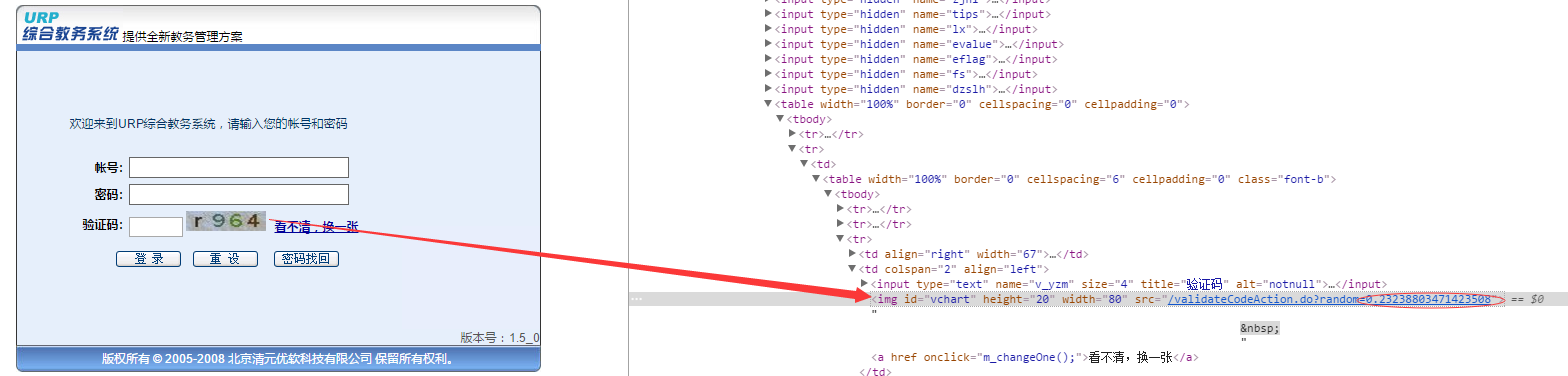
刚开始很纠结random那段随机数,以为是确定的随机数对应确定的验证码,可是一直没有解决获取这个随机数的方法(直接抓取的话src总为空),然后去网上各种查发现这句话
一般验证码只是判断cookie 后面的随机值是为了防止浏览器读取图片缓存,造成验证码输入错误
然后自己就复制了一个带random的验证码网址刷新了两下结果发现验证码真的会变,不是根据random,于是从网上查找得知只输入random参数前的地址即可,于是继续向下开展。
具体的思路是登陆将验证码下载下来,然后手动输入,提交账号、密码、验证码三个数据进行模拟登陆。
模拟登陆
# coding:utf8 import re
import urllib
import urllib2
import cookielib loginUrl = 'http://115.24.160.162/loginAction.do' #cookie
cookie = cookielib.CookieJar()
handler = urllib2.HTTPCookieProcessor(cookie)
opener = urllib2.build_opener(handler)
#postdata
values = {
'zjh':'xxxxxx',
'mm':'xxxxxx',
'v_yzm':''
}
postdata = urllib.urlencode(values)
#headers
header = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36',
'Referer':'http://115.24.160.162/loginAction.do'
} #第一次请求网页得到cookie
request = urllib2.Request(loginUrl,postdata,headers=header)
response = opener.open(request)
print '第一次请求网页得到cookie:'
print response.getcode() #获取验证码----------------!!!问题一直出在这,要用带cookie的方法访问验证码的网页---这样的话进入的验证码的页面对应的验证码就是登陆页面的验证码了哈哈哈哈哈(之前用的是不带cookie的urlopen()方法...)
yzm = opener.open('http://115.24.160.162/validateCodeAction.do')
yzm_data = yzm.read()
yzm_pic = file('yzm.jpg','wb')
yzm_pic.write(yzm_data)
yzm_pic.close() #用户输入验证码
print '请输入验证码:'
values['v_yzm'] = raw_input()
#带验证码模拟登陆
postdata = urllib.urlencode(values)
request = urllib2.Request(loginUrl,postdata,header)
response = opener.open(request)
print 'Response of loginAction.do'
print response.read().decode('gbk')
爬取成绩
根据最后打印出的网址源代码可知成功登陆。现在我们来爬取成绩。
成绩页面:
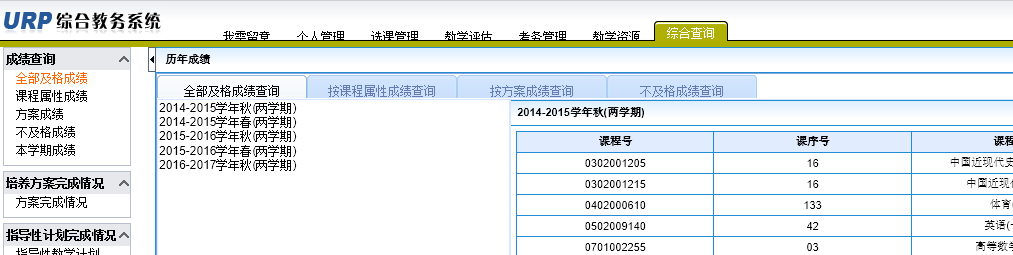
刚开始以为相应的按钮会有对应的超链接,比如有一个专门的成绩网址,然后就去源代码里苦苦寻找,半天无获,而且点击不同按钮浏览器显示的连接根本不变。后来F12看了看网络那一栏发现了玄机
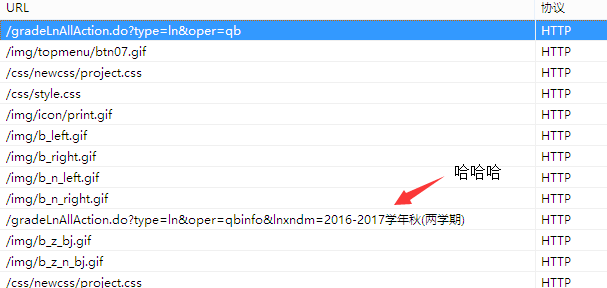
再看这个链接的响应正文,完美获得成绩页面。
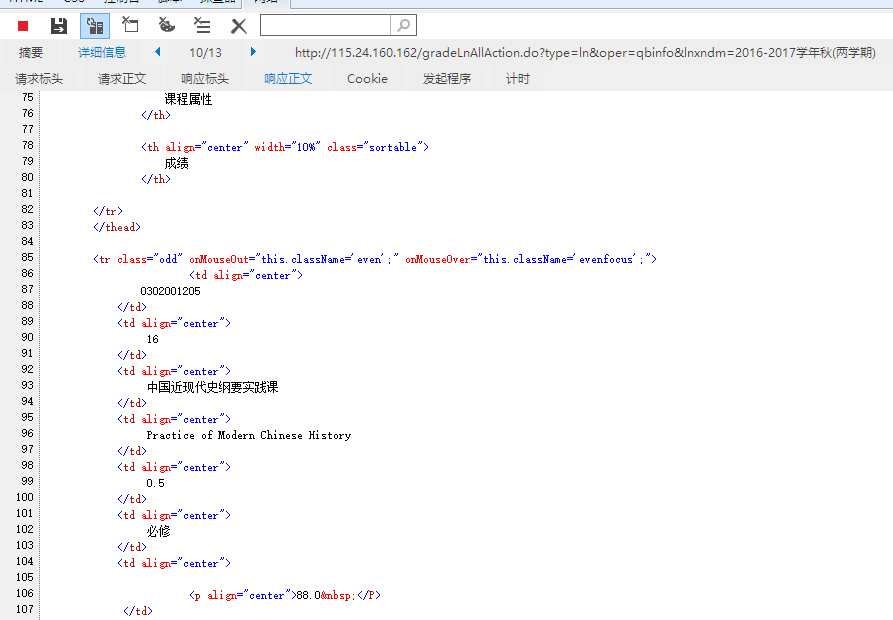
接下来就是正则表达式匹配得到课程名称和成绩了
#bingo
top_url = 'http://115.24.160.162/gradeLnAllAction.do?type=ln&oper=qbinfo&lnxndm=2016-2017学年秋(两学期)'
response = opener.open(top_url)
print 'Response of top.jsp'
content = response.read().decode('gbk') pattern = re.compile('<tr.*?class="odd".*?</td>.*?</td>.*?<td align="center">(.*?)</td>.*?<p align="center">(.*?) </P>', re.S)
grades = re.findall(pattern, content)
for grade in grades:
print grade[0], grade[1]
正则表达式的说明(引用自http://cuiqingcai.com/990.html)
1).*? 是一个固定的搭配,.和*代表可以匹配任意无限多个字符,加上?表示使用非贪婪模式进行匹配,也就是我们会尽可能短地做匹配,以后我们还会大量用到 .*? 的搭配。
2)(.*?)代表一个分组,在这个正则表达式中我们匹配了两个分组,在后面的遍历grades中,grade[0]就代表第一个(.*?)所指代的内容,grade[1]就代表第二个(.*?)所指代的内容,以此类推。
3)re.S 标志代表在匹配时为点任意匹配模式,点 . 也可以代表换行符。
抓取结果

结语
感谢攀哥(他的csdn:http://m.blog.csdn.net/blog/index?username=E80FA)
[python爬虫]爬取学校教务处成绩的更多相关文章
- 用Python爬虫爬取广州大学教务系统的成绩(内网访问)
用Python爬虫爬取广州大学教务系统的成绩(内网访问) 在进行爬取前,首先要了解: 1.什么是CSS选择器? 每一条css样式定义由两部分组成,形式如下: [code] 选择器{样式} [/code ...
- Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理 源代码如下: # 改进版, 增加了 .strip()方法的使用 # coding=utf-8 ...
- 使用Python爬虫爬取网络美女图片
代码地址如下:http://www.demodashi.com/demo/13500.html 准备工作 安装python3.6 略 安装requests库(用于请求静态页面) pip install ...
- Python爬虫|爬取喜马拉雅音频
"GOOD Python爬虫|爬取喜马拉雅音频 喜马拉雅是知名的专业的音频分享平台,用户规模突破4.8亿,汇集了有声小说,有声读物,儿童睡前故事,相声小品等数亿条音频,成为国内发展最快.规模 ...
- python爬虫爬取内容中,-xa0,-u3000的含义
python爬虫爬取内容中,-xa0,-u3000的含义 - CSDN博客 https://blog.csdn.net/aiwuzhi12/article/details/54866310
- Python爬虫爬取全书网小说,程序源码+程序详细分析
Python爬虫爬取全书网小说教程 第一步:打开谷歌浏览器,搜索全书网,然后再点击你想下载的小说,进入图一页面后点击F12选择Network,如果没有内容按F5刷新一下 点击Network之后出现如下 ...
- python爬虫—爬取英文名以及正则表达式的介绍
python爬虫—爬取英文名以及正则表达式的介绍 爬取英文名: 一. 爬虫模块详细设计 (1)整体思路 对于本次爬取英文名数据的爬虫实现,我的思路是先将A-Z所有英文名的连接爬取出来,保存在一个cs ...
- 一个简单的python爬虫,爬取知乎
一个简单的python爬虫,爬取知乎 主要实现 爬取一个收藏夹 里 所有问题答案下的 图片 文字信息暂未收录,可自行实现,比图片更简单 具体代码里有详细注释,请自行阅读 项目源码: # -*- cod ...
- python爬虫-爬取百度图片
python爬虫-爬取百度图片(转) #!/usr/bin/python# coding=utf-8# 作者 :Y0010026# 创建时间 :2018/12/16 16:16# 文件 :spider ...
随机推荐
- CSS3知识点整理(三)----变形与动画
一.CSS3中的变形 1)旋转 rotate() rotate()函数通过指定的角度参数使元素相对原点进行旋转. 它主要在二维空间内进行操作,设置一个角度值,用来指定旋转的幅度. 如果这个值为正值,元 ...
- SpringMvc拦截器小测试
前言 俗话说做项目是让人成长最快的方案,最近小编写项目的时候遇到了一个小问题.小编在项目中所负责的后台系统,但是后台系统是通过系统的页面是通过ifame联动的,那么这时候问题就来了,后台所做的所有操作 ...
- SQL基础笔记
Codecademy中Learn SQL, SQL: Table Transformaton和SQL: Analyzing Business Metrics三门课程的笔记,以及补充的附加笔记. Cod ...
- 将vim打造成php的IDE开发环境
将vim打造成IDE开发环境 本文主要介绍将vim打造成IDE开发环境,如代码补全,高亮显示,函数跳转,函数自动注释等 首先介绍2款VIM插件管理器:Vbundle,Pathogen 本文中的vim插 ...
- 201521123014 java第一周总结
201521123014 java第一周总结 1.本周学习总结 刚认识这一门新语言,我就充满了好奇心,想看看Java和学过C语言,C++有什么区别.在这一周的学习中,我认识到,对于初学者而言,Java ...
- BI数据分析中KPI,KGI,CSF概念
1. 行为产生数据 先来谈一谈,自己对数据基础概念的思考.我认为首先要建立的核心观点是:行为产生数据. 翻译一下这个核心观点.意思就是,当我们在思考或描述数据相关需求的时候,必然要包含这样的语素:&q ...
- 极光推送CTO黄鑫:技术人员要建立自己的知识图谱
本周,我们邀请到了极光推送CTO兼首席科学家黄鑫进行人物专访,在展示风采的同时,也分享会员们对技术.对工作.对人生的感悟. 扎实的底层服务是扩张关键 极光推送是一个做第三方云服务的公司,在 ...
- linux 之程序管理
一个程序的父进程可以用PPID来判断 命令ps -l 可以用来观察程序相关的输出信息 被关闭的程序又产生:crontab或者父进程产生的 我们将常驻在系统中的程序称为:服务(daemon) ...
- 问题 : lang.NoClassDefFoundError: org/springframework/core/annotation/AnnotatedElementUtils,的解决方法
今天在做junit 测试的时候 出现了一个问题,花了一段时间 才解决. java.lang.NoClassDefFoundError: org/springframework/core/annota ...
- Jemter+Badboy实战经验一(Badboy录制及基础功能)
1. 使用工具: Apache Jemeter:http://jmeter.apache.org/download_jmeter.cgi (免费官网下载地址) BadBoy: http://www ...