在ElasticSearch中使用 IK 中文分词插件
我这里集成好了一个自带IK的版本,下载即用,
https://github.com/xlb378917466/elasticsearch5.2.include_IK
添加了IK插件意味着你可以使用ik_smart(最粗粒度的拆分)和ik_max_word(最细粒度的拆分)两种analyzer。
你也可以从下面这个地址获取最新的IK源码,自己集成,
https://github.com/medcl/elasticsearch-analysis-ik,
里面还提供了使用说明,可以很快上手。
一般使用elasticsearch-head测试比较方便。
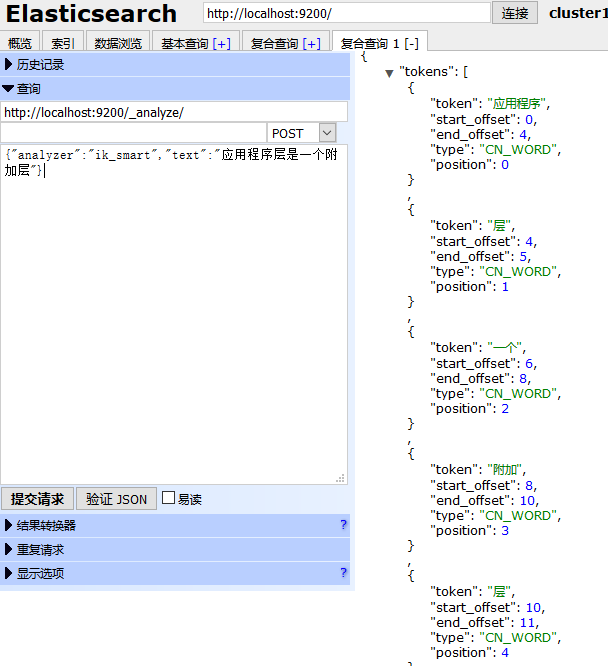
这个IK分词插件挺好用的,支持自定义分词,更重要的是支持热更新。
比如上面这个应用程序层是被分成了两个词,如果你把应用程序层作为一个词添加到你的自定义词典中,那么结果就会发生微妙的变化,通过这样不断的完善词库,相信搜索的体验会越来越好。
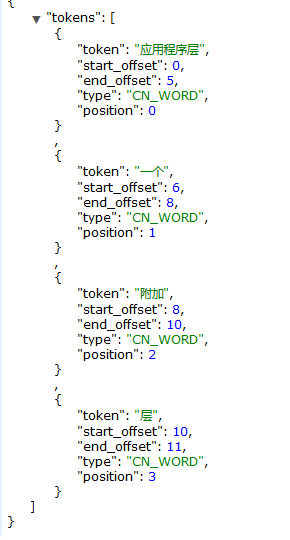
现在IK分词插件也算集成好了,如何使用?
首先新建一个索引,并且给这个索引下的文档类型设置Mapping关系
这里还是继续使用昨天新建的索引twitter作例子,所以只需要给文档类型tweet 新建一个字段Content,并设置这一个字段的Mapping来举例:
http://localhost:9200/twitter/_mapping/tweet/
{
"properties": {
"content": {
"type": "text",
"store": "no",
"term_vector": "with_positions_offsets",
"analyzer": "ik_smart",
"search_analyzer": "ik_smart",
"include_in_all": "true",
"boost": 8
}
}
}
这样一来,后面添加的Content就会使用ik_smart来分词,
添加一条测试数据:
http://localhost:9200/twitter/tweet/1/ 选择Put Method
{
"content": "应用程序层是一个附加层"
}
查询测试:
http://localhost:9200/twitter/_search/
使用POST Method,因为我使用ElasticSearch Head 在Get的情况下不返回highlight信息,
{
"query" : { "match" : { "content" : "应用程序层是一个附加层" }},
"highlight" : {
"pre_tags" : ["<tag1>", "<tag2>"],
"post_tags" : ["</tag1>", "</tag2>"],
"fields" : {
"content" : {}
}
}
}
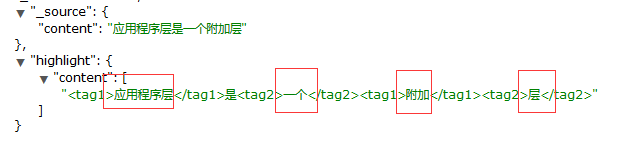
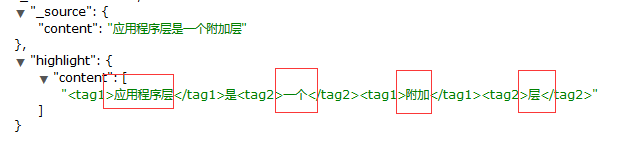
返回如下:
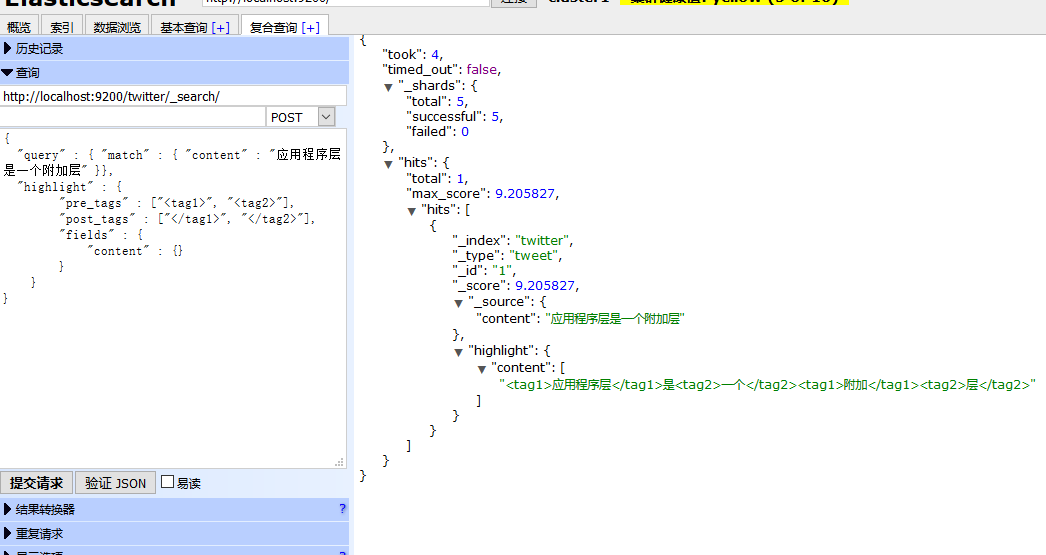
使用应用程序关键词是搜不到内容的,因为分词器不识别 这个词,就是说你要用被你拆分之后的词来搜索,才有匹配的记录。
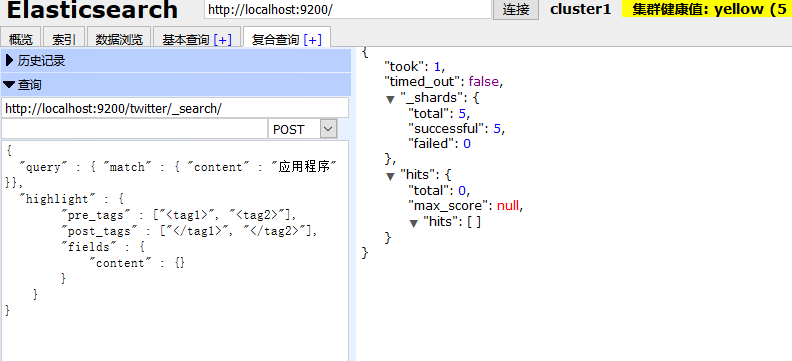
比如下面几个就是被拆分出来的词
在ElasticSearch中使用 IK 中文分词插件的更多相关文章
- ElasticSearch速学 - IK中文分词器远程字典设置
前面已经对”IK中文分词器“有了简单的了解: 但是可以发现不是对所有的词都能很好的区分,比如: 逼格这个词就没有分出来. 词库 实际上IK分词器也是根据一些词库来进行分词的,我们可以丰富这个词库. ...
- Elasticsearch安装ik中文分词插件(四)
一.IK简介 IK Analyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包.从2006年12月推出1.0版开始, IKAnalyzer已经推出了4个大版本.最初,它是以开源项目Lu ...
- es(elasticsearch)安装IK中文分词器
IK压缩包下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases?after=v6.7.0,需要下载对应的版本 我也上传了 h ...
- 30.IK中文分词器的安装和简单使用
在之前我们学的都是英文,用的也是英文的standard分词器.从这一节开始,学习中文分词器.中国人基本上都是中文应用,很少是英文的,而standard分词器是没有办法对中文进行合理分词的,只是将每个中 ...
- Solr学习笔记之2、集成IK中文分词器
Solr学习笔记之2.集成IK中文分词器 一.下载IK中文分词器 IK中文分词器 此文IK版本:IK Analyer 2012-FF hotfix 1 完整分发包 二.在Solr中集成IK中文分词器 ...
- ElasticSearch搜索引擎安装配置中文分词器IK插件
近几篇ElasticSearch系列: 1.阿里云服务器Linux系统安装配置ElasticSearch搜索引擎 2.Linux系统中ElasticSearch搜索引擎安装配置Head插件 3.Ela ...
- Elasticsearch安装中文分词插件ik
Elasticsearch默认提供的分词器,会把每一个汉字分开,而不是我们想要的依据关键词来分词.比如: curl -XPOST "http://localhost:9200/userinf ...
- ElasticSearch 中文分词插件ik 的使用
下载 IK 的版本要与 Elasticsearch 的版本一致,因此下载 7.1.0 版本. 安装 1.中文分词插件下载地址:https://github.com/medcl/elasticsearc ...
- 搜索引擎ElasticSearch系列(五): ElasticSearch2.4.4 IK中文分词器插件安装
一:IK分词器简介 IK Analyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包.从2006年12月推出1.0版开始, IKAnalyzer已经推出了4个大版本.最初,它是以开源 ...
随机推荐
- jvm系列(八):jvm知识点总览-高级Java工程师面试必备
在江湖中要练就绝世武功必须内外兼备,精妙的招式和深厚的内功,武功的基础是内功.对于武功低(就像江南七怪)的人,招式更重要,因为他们不能靠内功直接去伤人,只能靠招式,利刃上优势来取胜了,但是练到高手之后 ...
- 初探Lambda表达式/Java多核编程【4】Lambda变量捕获
这周开学,上了两天感觉课好多,学校现在还停水,宿舍网络也还没通,简直爆炸,感觉能静下心看书的时间越来越少了...寒假还有些看过书之后的存货,现在写一点发出来.加上假期两个月左右都过去了书才看了1/7都 ...
- C# 字符串比较大小 string.Compare()方法
string.Compare方法,用来比较2个字符串值得大小 string.Compare(str1, str2, true); 返回值: 1 : str1大于str2 0 : str1等于str2 ...
- Asp.Net 常用工具类之Office—Excel导出(4)
开发过程中各类报表导入导出防不胜防,网上也是各种解决方法层出不穷,比如Excel,CSV,Word,PDF,HTML等等... 网上各种导出插件也是层出不穷,NPOI,微软Microsoft.Offi ...
- php与mysql之间操作原理
php和mysql相关扩展有:mysql.mysqli和pdo三种 mysql扩展从php5.5.0被废弃,并且从从php7.0.0开始被废除 mysql之前的使用---几个基本的函数:mysql_c ...
- 本机安装mysql服务,步骤教程(另附SQLyog和Navicat工具)
因为这段时间不是装系统就是换硬盘,导致装了还几次MySql,每次都记不住都要上网找教程,着实麻烦,所以这次干脆直接写到博客上好了,便于自己也便于他人: 百度云:http://pan.baidu.com ...
- Omi应用md2site-0.5.0发布-支持动态markdown拉取解析
写在前面 Md2site是基于Omi的一款Markdown转网站工具,使用简单,生成的文件轻巧,功能强大. 官网:http://alloyteam.github.io/omi/md2site/ Git ...
- solr home 目录设置
对于在tomcat 中部署solr 来说,有以下三处可以配置 solr.solr.home(即solr的数据文件位置): 1. 在解压缩solr.war后的webapps/solr 中的WEB-INF ...
- Asp.NetCore1.1版本没了project.json,这样来生成跨平台包
本章将要和大家分享的是Asp.NetCore1.1版本去掉了project.json后如何打包生成跨平台包, 为了更好跟进AspNetCore的发展,把之前用来做netcore开发的vs2015卸载后 ...
- Alamofire源码解读系列(七)之网络监控(NetworkReachabilityManager)
Alamofire源码解读系列(七)之网络监控(NetworkReachabilityManager) 本篇主要讲解iOS开发中的网络监控 前言 在开发中,有时候我们需要获取这些信息: 手机是否联网 ...