windows下在idea用maven导入spark2.3.1源码并编译并运行示例
一、前提
1.配置好maven:intellij idea maven配置及maven项目创建
2.下载好spark源码:
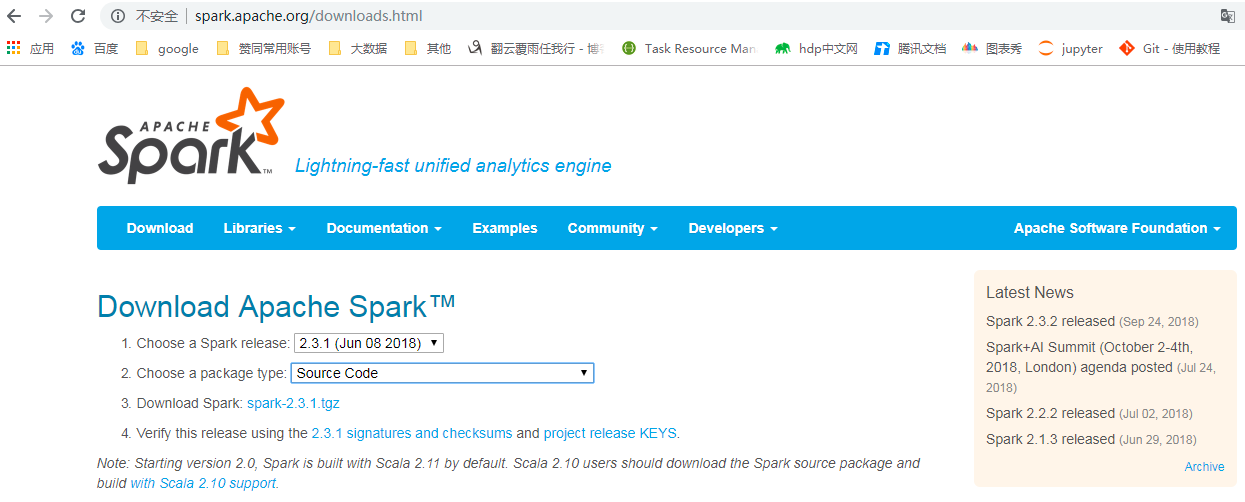
二、导入源码:
1.将下载的源码包spark-2.3.1.tgz解压(E:\spark-2.3.1.tgz\spark-2.3.1.tar)至E:\spark-2.3.1-src
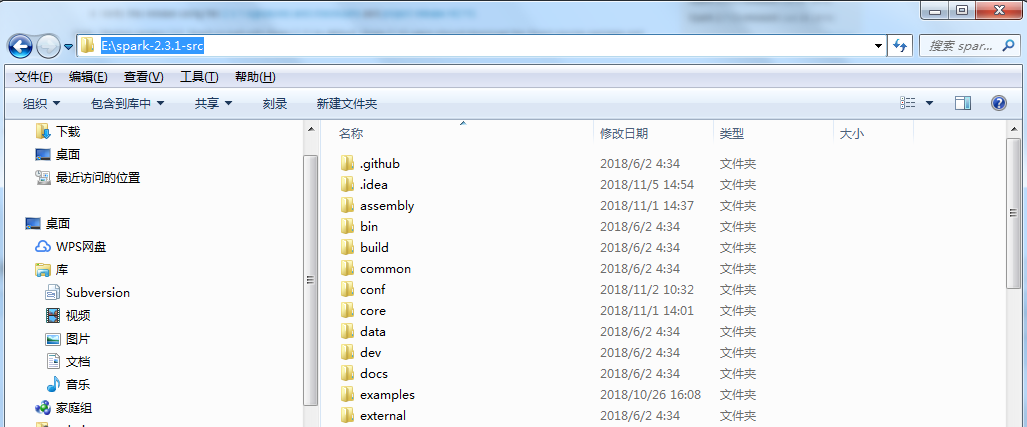
2.在ideal导入源码:
a.选择解压的源代码文件夹
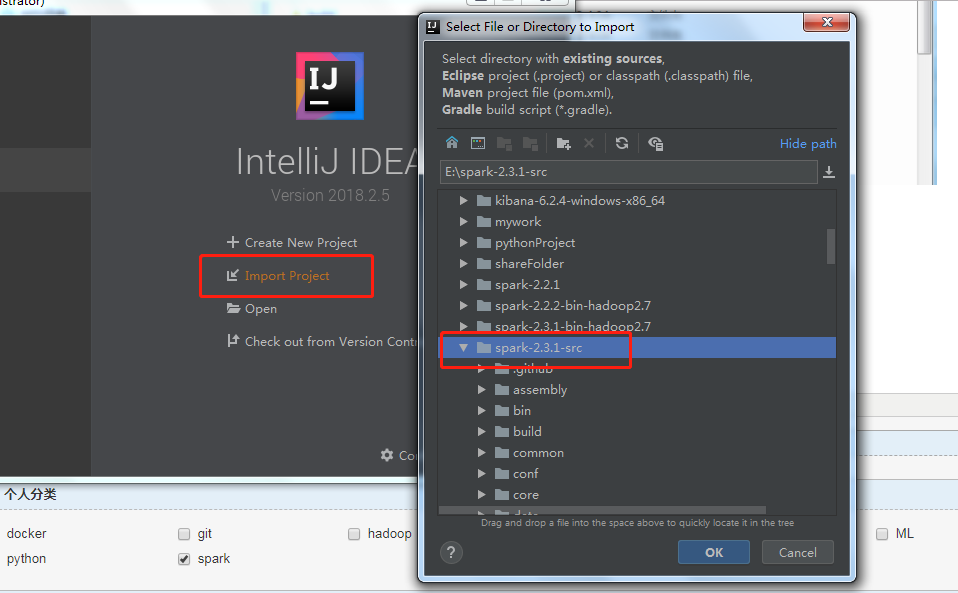
b.使用maven导入工程
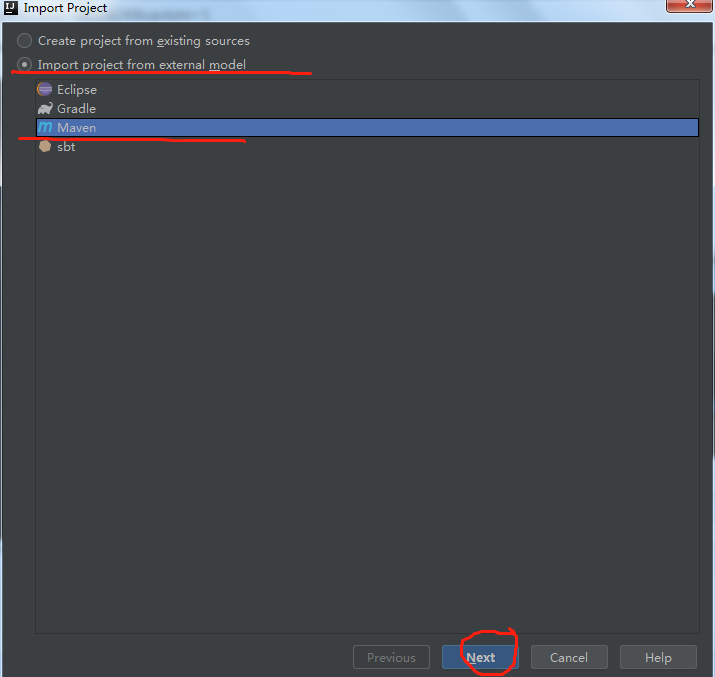
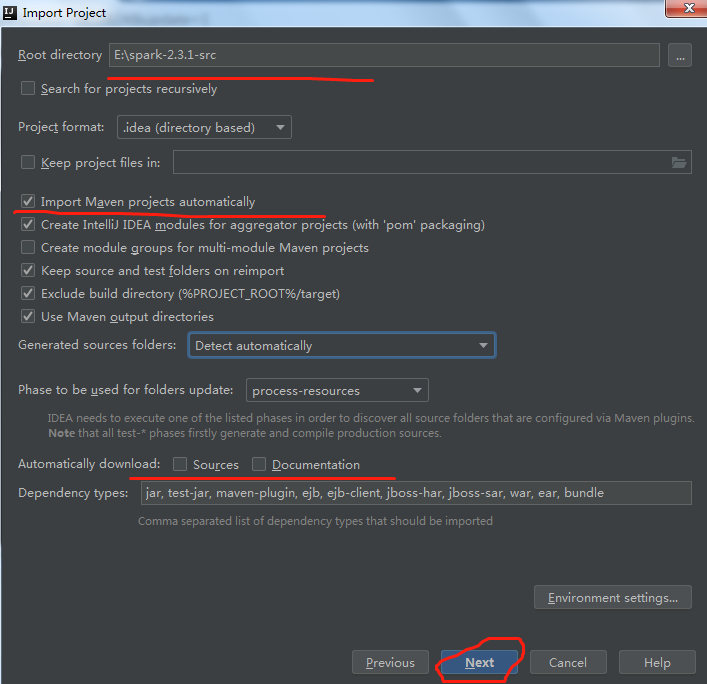
c.选择对应组件的版本
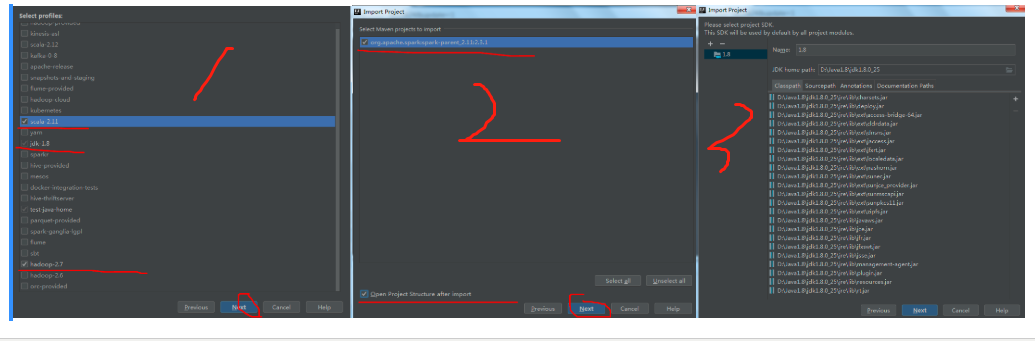
然后点击下一步:
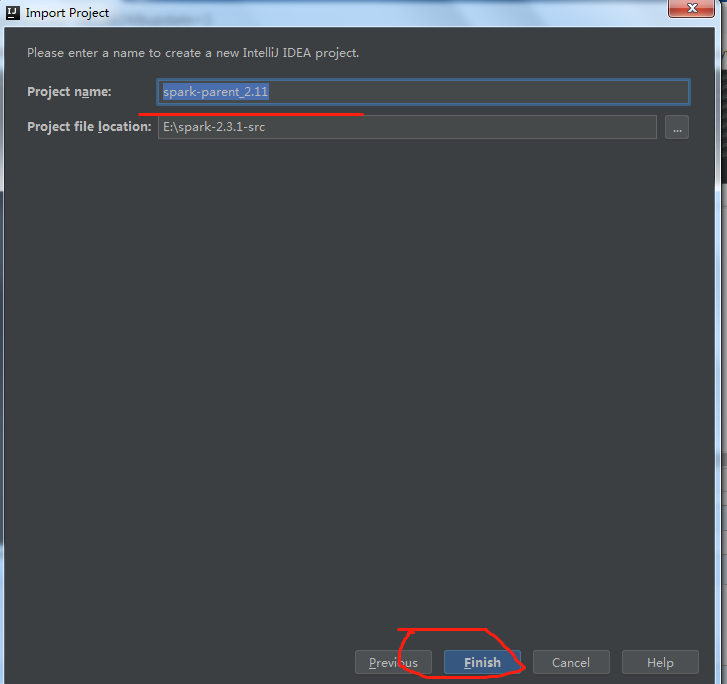 点击finish后,等待maven下载相关的依赖包,之后工程界面如下:
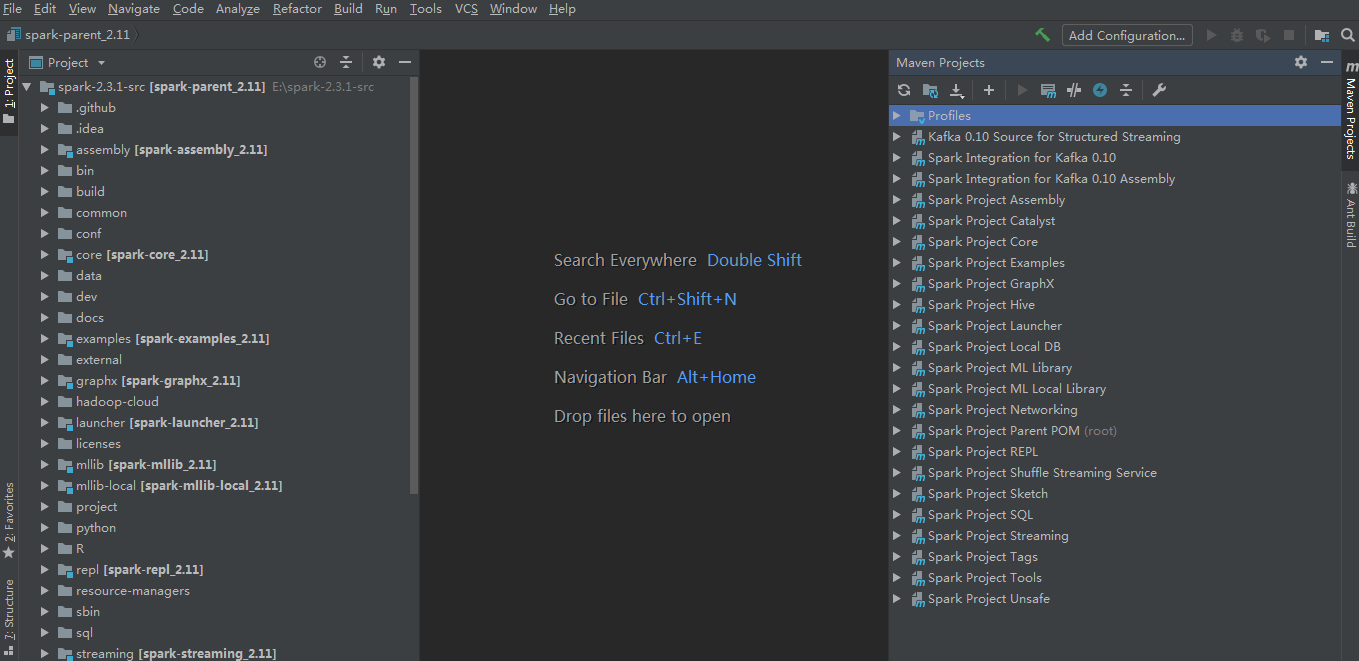
点击finish后,等待maven下载相关的依赖包,之后工程界面如下:
修改E:\spark-2.3.1-src\pom.xml文件,以避免这俩变量未定义,导致最终在E:\spark-2.3.1-src\assembly\target\scala-2.11\没有jar包

开始使用maven对spark源码进行编译打包成jar:
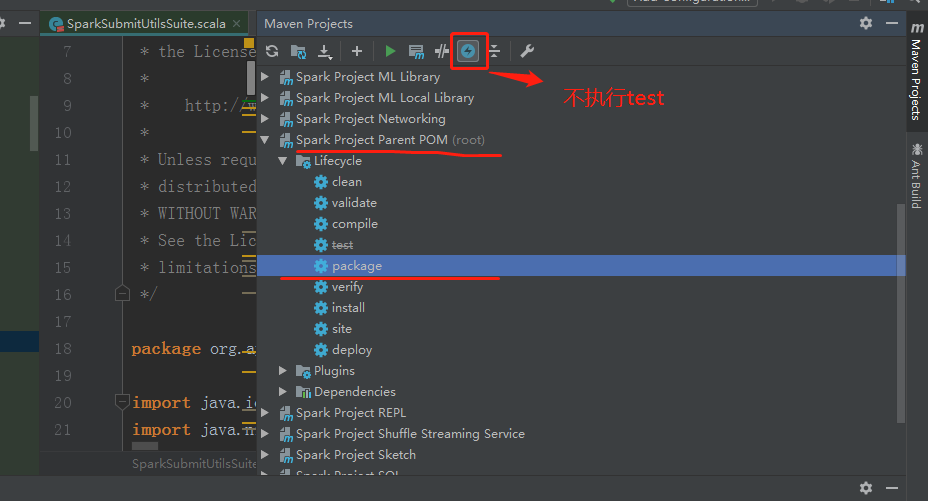
编译结果如下:
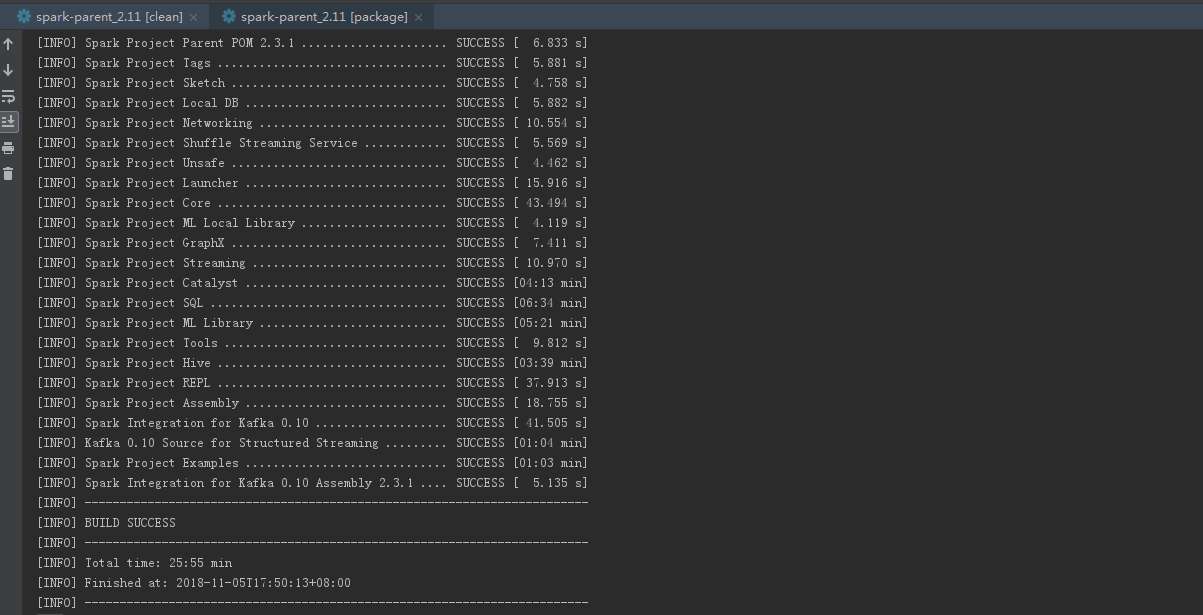
会在每个模块的target目录生成对应的jar,并在assembly\target\scala-2.11\jar下生成spark需要的全部jar包

解决办法如下,在E:\spark-2.3.1-src\sql\catalyst\target目录下会出现antlr4相关的类:


三.运行spark自带示例(前提:需要配置spark在windows下的运行环境,参见win7下配置spark)
1.SparkPi
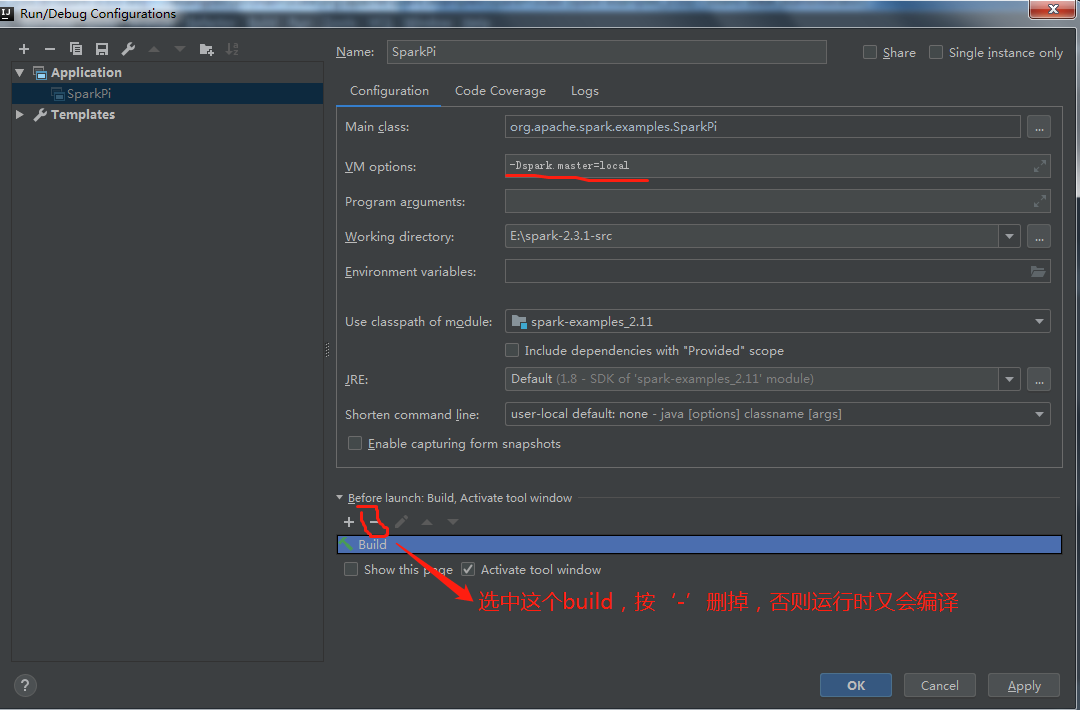
报错如下:
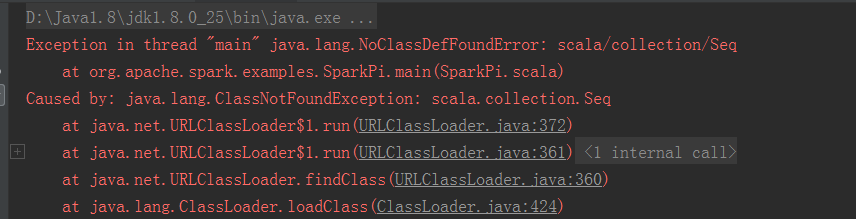
刚才生成的spark相关的依赖包没找到,解决办法如下:


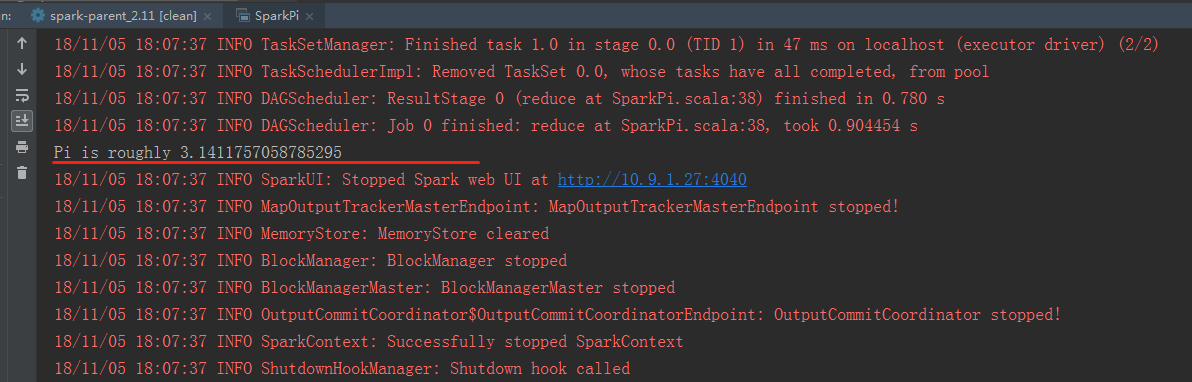
再次运行,结果如下:
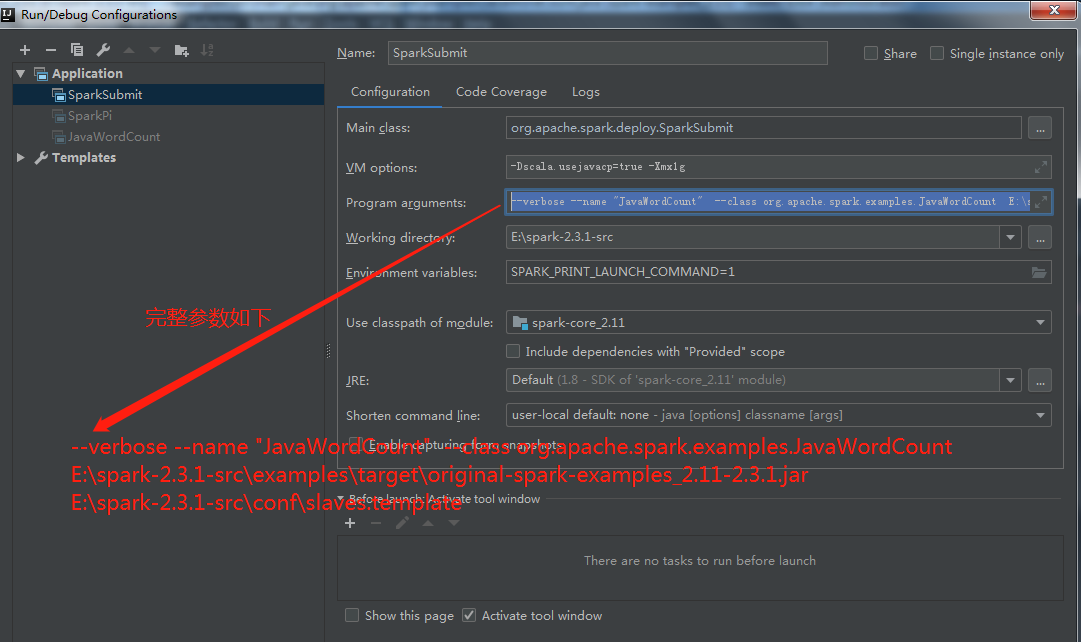
2.通过org.apache.spark.deploy.SparkSubmit提交任务并运行(前提是像运行SparkPi一样,把assembly\target\jars的依赖加进该模块,方法同上):
2.1 org.apache.spark.repl.Main
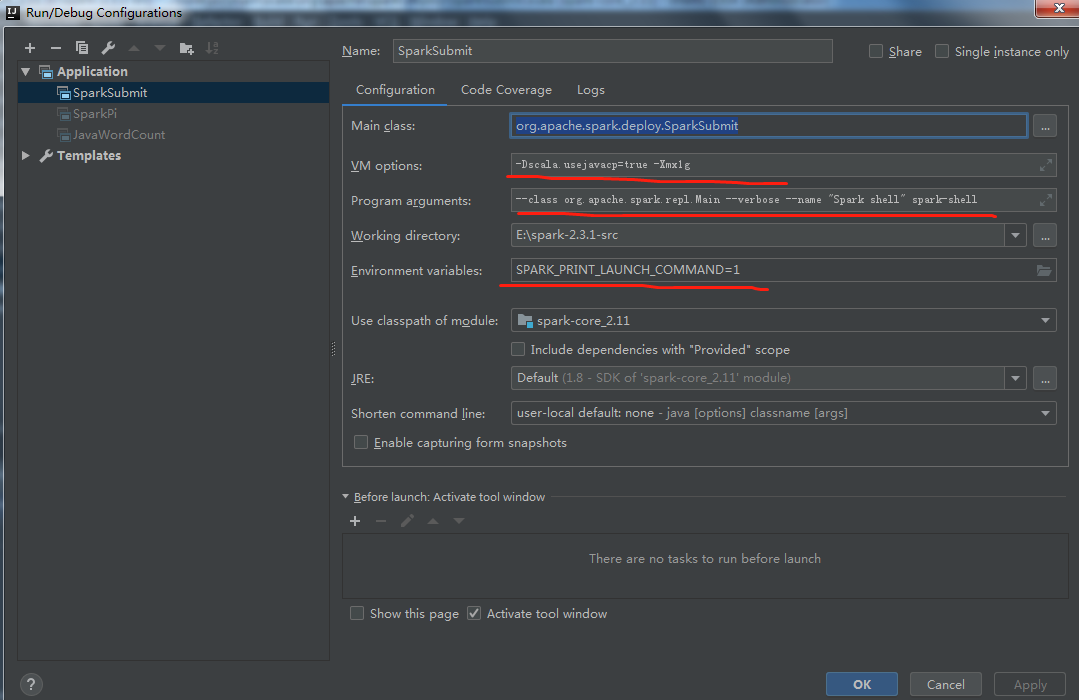
结果:
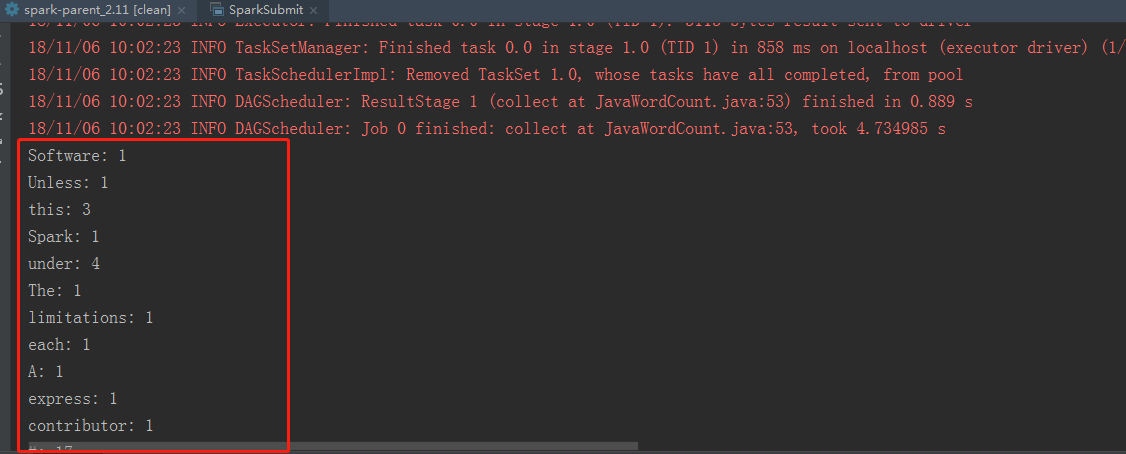
2.2 自定义spark代码类运行(以自带的org.apache.spark.examples.JavaWordCount为例)

windows下在idea用maven导入spark2.3.1源码并编译并运行示例的更多相关文章
- 导入spark2.3.3源码至intellij idea
检查环境配置 maven环境 2.检查scala插件 没有的话可以到https://plugins.jetbrains.com/plugin/1347-scala/versions 下载与idea对应 ...
- spark最新源码下载并导入到开发环境下助推高质量代码(Scala IDEA for Eclipse和IntelliJ IDEA皆适用)(以spark2.2.0源码包为例)(图文详解)
不多说,直接上干货! 前言 其实啊,无论你是初学者还是具备了有一定spark编程经验,都需要对spark源码足够重视起来. 本人,肺腑之己见,想要成为大数据的大牛和顶尖专家,多结合源码和操练编程. ...
- Windows上IDEA搭建最新Spark2.4.3源码调试的开发环境
相信很多同学都想通过阅读一些框架的源码,来提高自己的代码能力,但往往在第一步,搭建环境的时候就碰了壁. 本篇就来介绍下如何在Windows下,将最新版的Spark2.4.3编译,并导入到IDEA编译器 ...
- 如何在IDEA里给大数据项目导入该项目的相关源码(博主推荐)(类似eclipse里同一个workspace下单个子项目存在)(图文详解)
不多说,直接上干货! 如果在一个界面里,可以是单个项目 注意:本文是以gradle项目的方式来做的! 如何在IDEA里正确导入从Github上下载的Gradle项目(含相关源码)(博主推荐)(图文详解 ...
- 使用 IntelliJ IDEA 导入 Spark 最新源码及编译 Spark 源代码(博主强烈推荐)
前言 其实啊,无论你是初学者还是具备了有一定spark编程经验,都需要对spark源码足够重视起来. 本人,肺腑之己见,想要成为大数据的大牛和顶尖专家,多结合源码和操练编程. 准备工作 1.sca ...
- 使用 IntelliJ IDEA 导入 Spark 最新源码及编译 Spark 源代码
前言 其实啊,无论你是初学者还是具备了有一定spark编程经验,都需要对spark源码足够重视起来. 本人,肺腑之己见,想要成为大数据的大牛和顶尖专家,多结合源码和操练编程. 准备工作 1.sca ...
- Spark2.0.0源码编译
Hive默认使用MapReduce作为执行引擎,即Hive on mr,Hive还可以使用Tez和Spark作为其执行引擎,分别为Hive on Tez和Hive on Spark.由于MapRedu ...
- 一步步实现windows版ijkplayer系列文章之七——终结篇(附源码)
一步步实现windows版ijkplayer系列文章之一--Windows10平台编译ffmpeg 4.0.2,生成ffplay 一步步实现windows版ijkplayer系列文章之二--Ijkpl ...
- 一步步实现windows版ijkplayer系列文章之二——Ijkplayer播放器源码分析之音视频输出——视频篇
一步步实现windows版ijkplayer系列文章之一--Windows10平台编译ffmpeg 4.0.2,生成ffplay 一步步实现windows版ijkplayer系列文章之二--Ijkpl ...
随机推荐
- Python 3 与 Javascript escape 传输确保数据正确方法和中文乱码解决方案
注意:现在已不推荐 escape 函数,推荐使用 encodeURIComponent 函数,其中方法更简单,只需进行URL解码即可. 当然了,如下文章解决方案一样可行. 前几天用Python的Bo ...
- 【转】Android中获取应用程序(包)的信息-----PackageManager的使用(一)
转载请注明出处:http://blog.csdn.net/qinjuning 本节内容是如何获取Android系统中应用程序的信息,主要包括packagename.label.icon.占 ...
- virtualbox+vagrant学习-3-Vagrant Share-4-Vagrant Connect
Vagrant Connect vagrant可以共享到vagrant环境的任何或每个端口,而不仅仅是SSH和HTTP.“vagrant connect”命令为连接人员提供一个静态IP,他们可以使用该 ...
- Debian 8 安装 Qt5 和 go-qml
一.安装相关依赖 ~ ᐅ sudo apt-get install build-essential libgl1-mesa-dev ~ ᐅ sudo apt-get install qt5-defau ...
- “error : unknown filesystem”的解决的方法
解决方法例如以下: 1:首先使用ls命令显示出ubuntu分区的安装信息: 1 grub rescue>ls 通常会罗列出全部磁盘的分区信息,比方(hd0,msdos1)(hd0,msdos2) ...
- where语句中不能直接使用聚合函数
1.问题描述 select deptno ,avg(sal) from emp where count(*)>3 group by deptno; 在where 句中使用聚合函数count(*) ...
- Java面向对象之多态(来源于身边的案例)
2019年1月3日 星期四 Java面向对象之多态(来源于身边的案例) 1. 为什么要用多态? 1.1 多态是面向对象的三大特性之一 1.2 多态是基于接口设计的模型 1.3 多态具有横向扩展特性 1 ...
- window.open 防止浏览器拦截
https://blog.csdn.net/sinat_37255207/article/details/89374416 网上试了很多方法 最终只有一种可以 var newWin = window. ...
- Linux用户管理及用户信息查询
useradd 创建用户,更改用户信息 1.工作原理流程 使用此命令式,若不加任何参数选项,直接跟用户名,那么系统会首先读取/etc/login.defs(用户定义文件)和/etc/default/u ...
- 从0开始学golang--2.2--如何去爬园子的数据👉进阶篇,面向对象的单任务版
执行页main.go-----------------------------------代码