bm25
BM25算法,通常用来作搜索相关性平分。一句话概况其主要思想:对Query进行语素解析,生成语素qi;然后,对于每个搜索结果D,计算每个语素qi与D的相关性得分,最后,将qi相对于D的相关性得分进行加权求和,从而得到Query与D的相关性得分。
BM25算法的一般性公式如下:
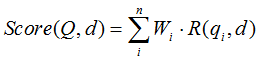
其中,Q表示Query,qi表示Q解析之后的一个语素(对中文而言,我们可以把对Query的分词作为语素分析,每个词看成语素qi。);d表示一个搜索结果文档;Wi表示语素qi的权重;R(qi,d)表示语素qi与文档d的相关性得分。
下面我们来看如何定义Wi。判断一个词与一个文档的相关性的权重,方法有多种,较常用的是IDF。这里以IDF为例,公式如下:
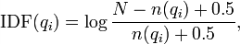
其中,N为索引中的全部文档数,n(qi)为包含了qi的文档数。
根据IDF的定义可以看出,对于给定的文档集合,包含了qi的文档数越多,qi的权重则越低。也就是说,当很多文档都包含了qi时,qi的区分度就不高,因此使用qi来判断相关性时的重要度就较低。
我们再来看语素qi与文档d的相关性得分R(qi,d)。首先来看BM25中相关性得分的一般形式:
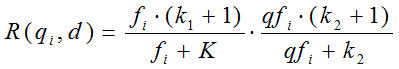
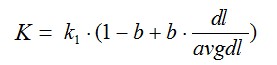
其中,k1,k2,b为调节因子,通常根据经验设置,一般k1=2,b=0.75;fi为qi在d中的出现频率,qfi为qi在Query中的出现频率。dl为文档d的长度,avgdl为所有文档的平均长度。由于绝大部分情况下,qi在Query中只会出现一次,即qfi=1,因此公式可以简化为:
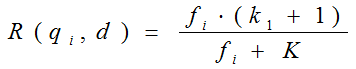
从K的定义中可以看到,参数b的作用是调整文档长度对相关性影响的大小。b越大,文档长度的对相关性得分的影响越大,反之越小。而文档的相对长度越长,K值将越大,则相关性得分会越小。这可以理解为,当文档较长时,包含qi的机会越大,因此,同等fi的情况下,长文档与qi的相关性应该比短文档与qi的相关性弱。
综上,BM25算法的相关性得分公式可总结为:
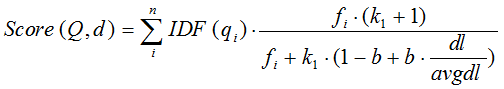
从BM25的公式可以看到,通过使用不同的语素分析方法、语素权重判定方法,以及语素与文档的相关性判定方法,我们可以衍生出不同的搜索相关性得分计算方法,这就为我们设计算法提供了较大的灵活性。
原文地址:http://ipie.blogbus.com/logs/104136815.html
bm25的更多相关文章
- BM25相关度打分公式
BM25算法是一种常见用来做相关度打分的公式,思路比较简单,主要就是计算一个query里面所有词和文档的相关度,然后在把分数做累加操作,而每个词的相关度分数主要还是受到tf/idf的影响.公式如下: ...
- 概率检索模型及BM25
概率排序原理 以往的向量空间模型是将query和文档使用向量表示然后计算其内容相似性来进行相关性估计的,而概率检索模型是一种直接对用户需求进行相关性的建模方法,一个query进来,将所有的文档分为两类 ...
- BM25和Lucene Default Similarity比较 (原文标题:BM25 vs Lucene Default Similarity)
原文链接: https://www.elastic.co/blog/found-bm-vs-lucene-default-similarity 原文 By Konrad Beiske 翻译 By 高家 ...
- 文本相似度 — TF-IDF和BM25算法
1,$TF-IDF$算法 $TF$是指归一化后的词频,$IDF$是指逆文档频率.给定一个文档集合$D$,有$d_1, d_2, d_3, ......, d_n \in D$.文档集合总共包含$m$个 ...
- 文本相似度-BM25算法
BM25 is a bag-of-words retrieval function that ranks a set of documents based on the query terms app ...
- 概率检索模型:BIM+BM25+BM25F
1. 概率排序原理 以往的向量空间模型是将query和文档使用向量表示然后计算其内容相似性来进行相关性估计的,而概率检索模型是一种直接对用户需求进行相关性的建模方法,一个query进来,将所有的文档分 ...
- BM25 调参调研
1. 搜索 ES 计算文本相似度用的 BM25,参数默认,不适合电商场景,可调整 BM25 参数使其适用于电商短文本场景 2. k1.b.tf.L.tfScore 的关系如下图红框内所示(注:这里的 ...
- Solr相似度算法二:Okapi BM25
地址:https://en.wikipedia.org/wiki/Okapi_BM25 In information retrieval, Okapi BM25 (BM stands for Be ...
- 相关度算法BM25
BM25算法,通常用来作搜索相关性平分.一句话概况其主要思想:对Query进行语素解析,生成语素qi:然后,对于每个搜索结果D,计算每个语素qi与D的相关性得分,最后,将qi相对于D的相关性得分进行加 ...
随机推荐
- vbs脚本发送邮件
NameSpace = "http://schemas.microsoft.com/cdo/configuration/"Set Email = CreateObject(&quo ...
- [React] React Fundamentals: Add-on ClassSet() for ClassName
To get the add-ons, use react-with-addons.js (and its minified counterpart) rather than the common r ...
- perl 线程创健
http://www.cnblogs.com/zhangchaoyang/articles/2057178.html
- 理解URI和URL
1)定义: URI: Uniform Resource Identifier,通用资源标识符 ---是一个用于标识某一互联网资源名称的字符串(by 维基百科) URL:Uniform Resource ...
- Java常见异常总结
算术异常类:ArithmeticExecption 空指针异常类:NullPointerException 类型强制转换异常:ClassCastException 数组负下标异常:NegativeAr ...
- 自己动手,丰衣足食!一大波各式各样的ImageView来袭!
工作略忙,一直想自己打造一个开源控件却苦于没有时间,可是这种事情如果不动手就会一直拖下去,于是最近抽时间做了个简单的自定义形状的ImageView控件. 时间紧迫,目前仅支持正六边形.圆形.菱形.椭圆 ...
- javascript进击(五)JS对象
JavaScript中是所有事物都是对象.JavaScript允许自定义对象. 对象是带有属性和方法的特殊数据类型. 访问对象的属性: 常见属性 访问对象的方法: 常用方法 (创建JavaScript ...
- Github + Hexo 搭建博客
服务加速 brew 加速 http://blog.suconghou.cn/post/homebrew-speedup/ github加速 http://www.selfrebuild.net/201 ...
- (转+整理) oracle authid definer 与 authid current_user
转:http://blog.csdn.net/indexman/article/details/17067531 http://blog.csdn.net/liqfyiyi/article/detai ...
- 监听列表ListVIew的滑动状态
/*监听列表的滑动状态:暂时用不到 * SCROLL_STATE_FLING 时让图片不显示,提高滚动性能让滚动小姑更平滑 * SCROLL_STATE_IDLE 时显示当前屏幕可见的图片*/ mLi ...