简易数据分析 10 | Web Scraper 翻页——抓取「滚动加载」类型网页

这是简易数据分析系列的第 10 篇文章。
友情提示:这一篇文章的内容较多,信息量比较大,希望大家学习的时候多看几遍。
我们在刷朋友圈刷微博的时候,总会强调一个『刷』字,因为看动态的时候,当把内容拉到屏幕末尾的时候,APP 就会自动加载下一页的数据,从体验上来看,数据会源源不断的加载出来,永远没有尽头。

我们今天就是要讲讲,如何利用 Web Scraper 抓取滚动到底翻页的网页。
今天我们的练手网站是知乎数据分析模块的精华帖,网址为:
https://www.zhihu.com/topic/19559424/top-answers
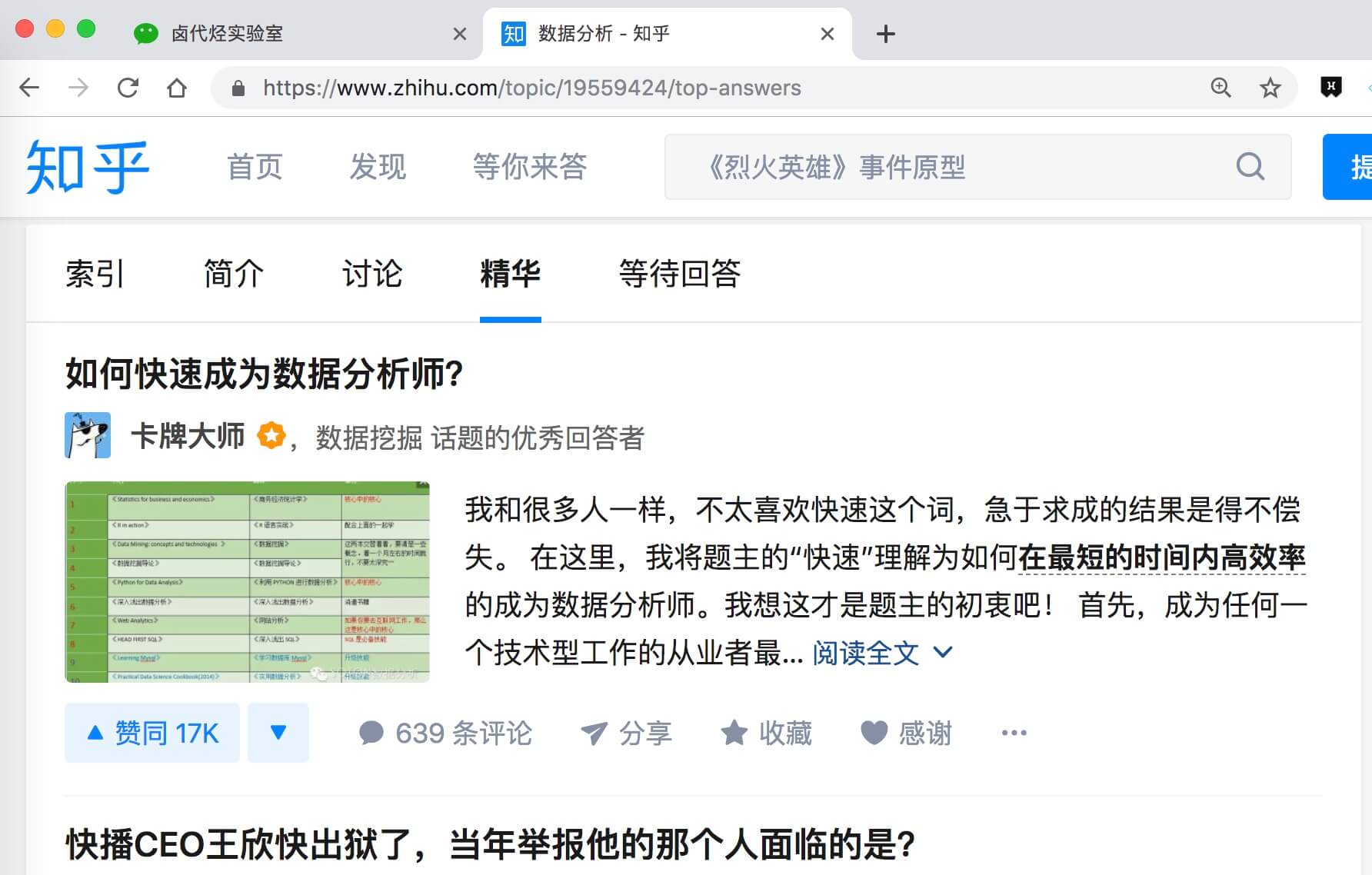
这次要抓取的内容是精华帖的标题、答题人和赞同数。下面是今天的教程。
1.制作 Sitemap
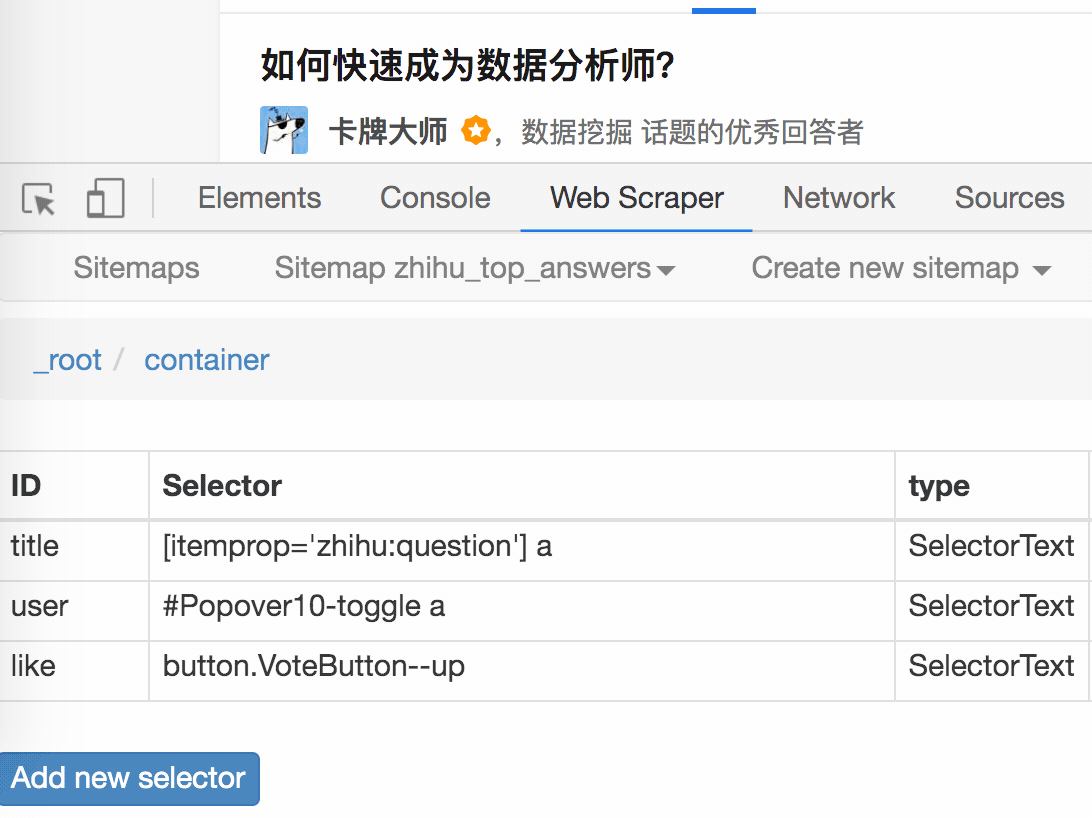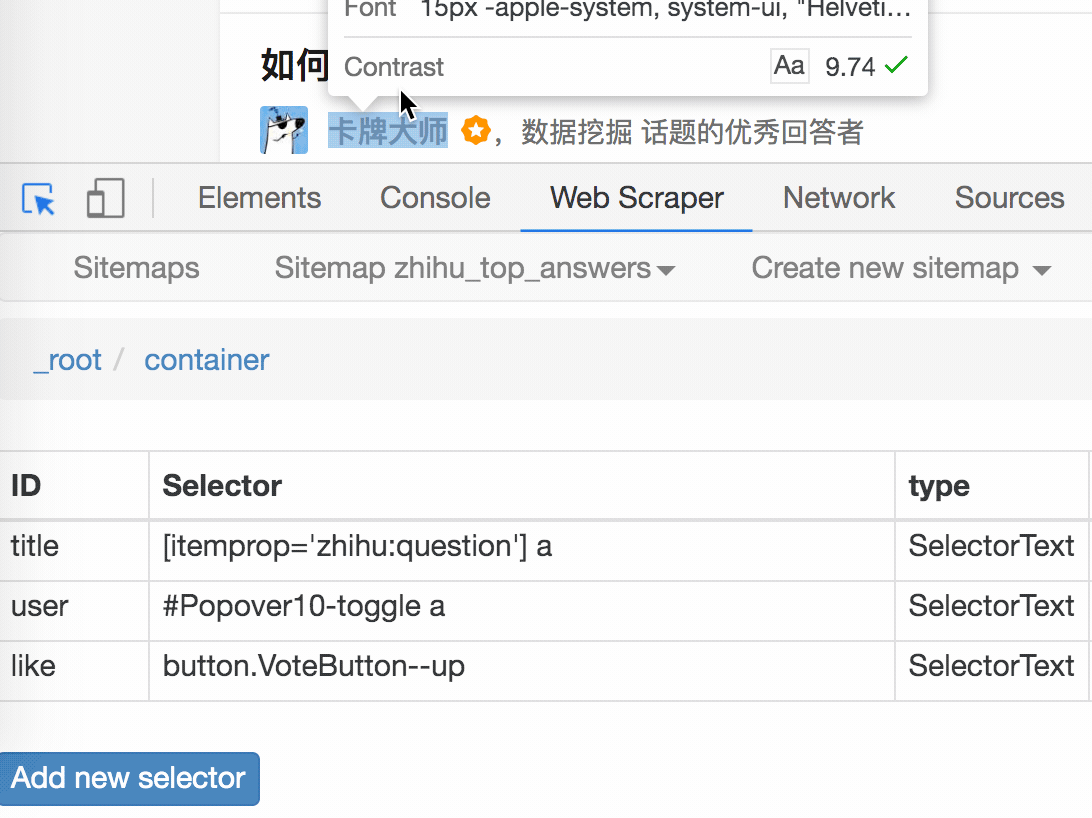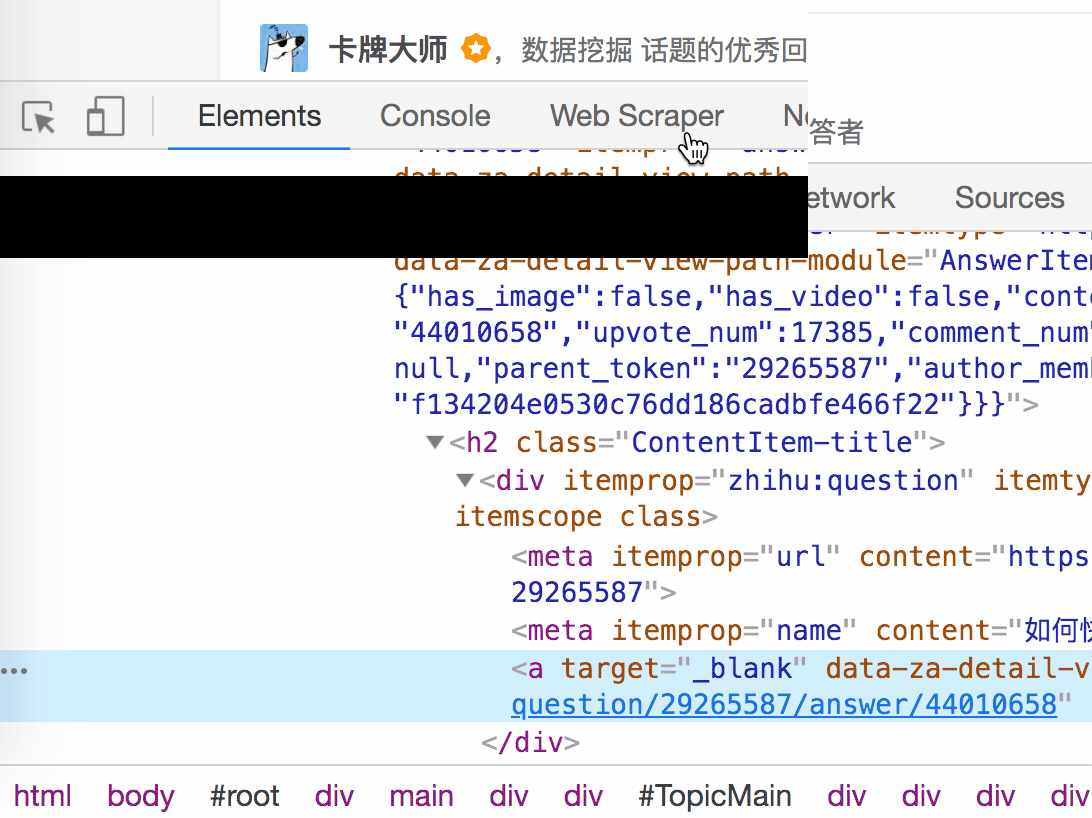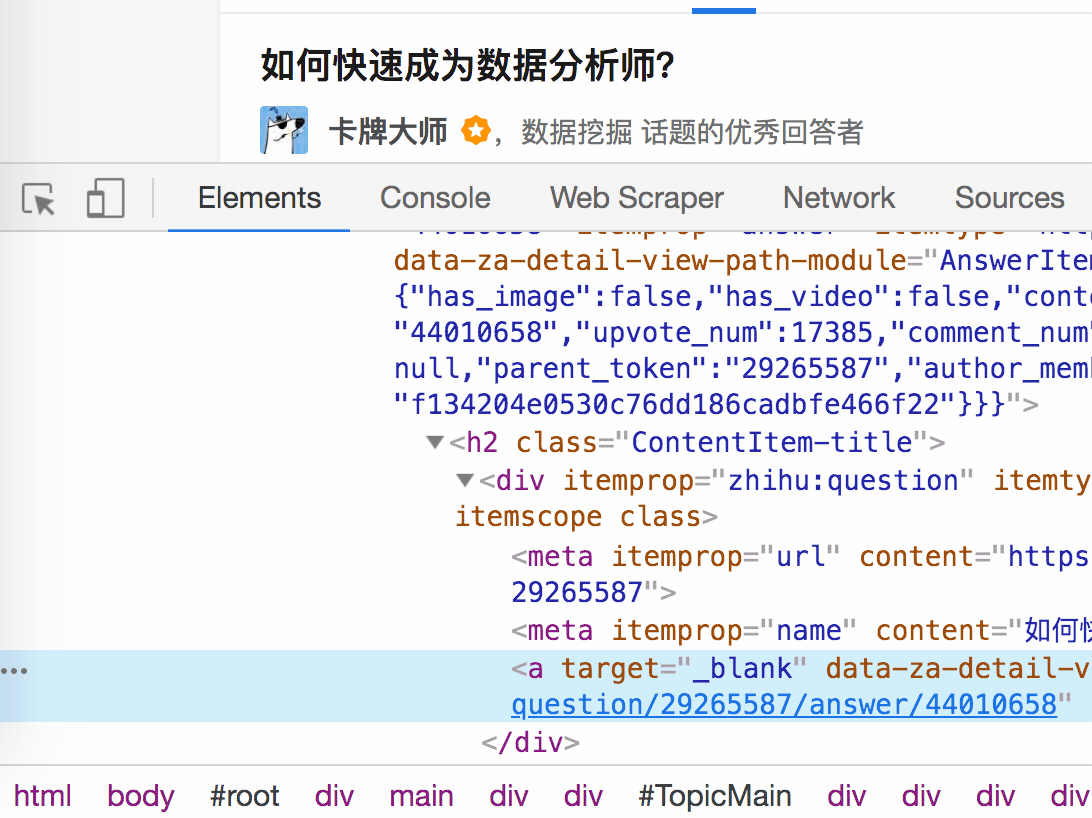
刚开始我们要先创建一个 container,包含要抓取的三类数据,为了实现滚动到底加载数据的功能,我们把 container 的 Type 选为 Element scroll down,就是滚动到网页底部加载数据的意思。
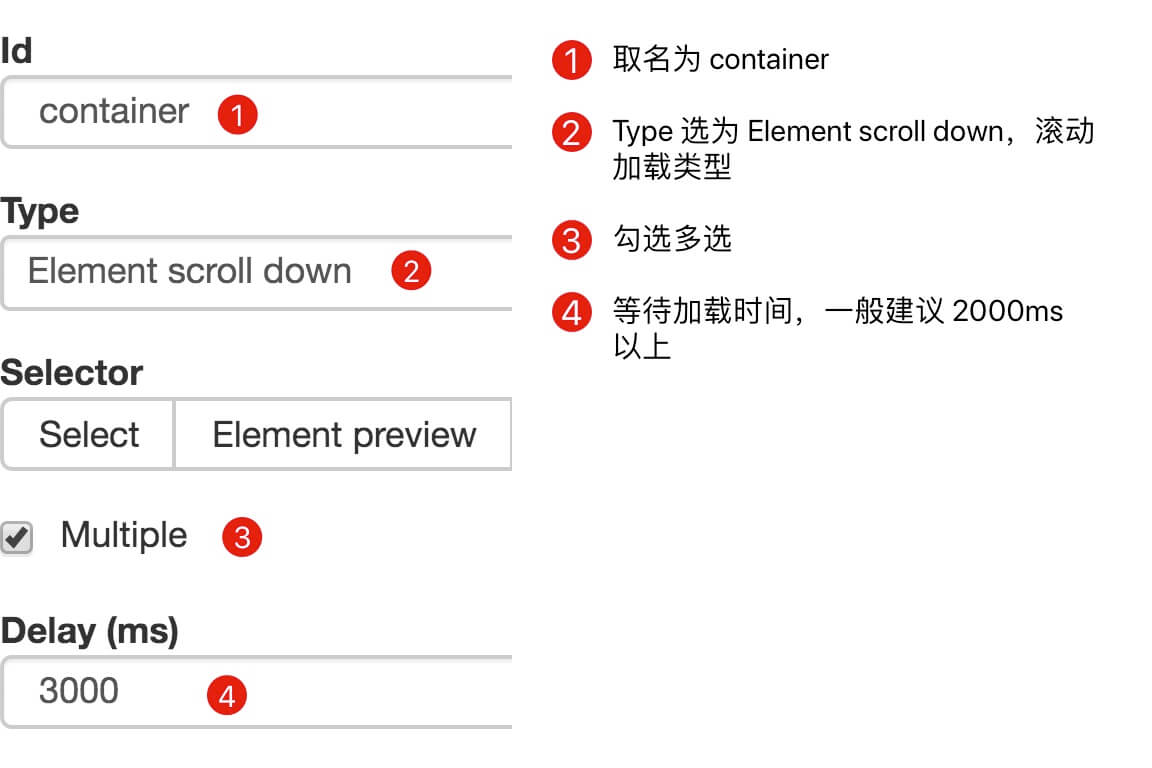
在这个案例里,选择的元素名字为 div.List-item。
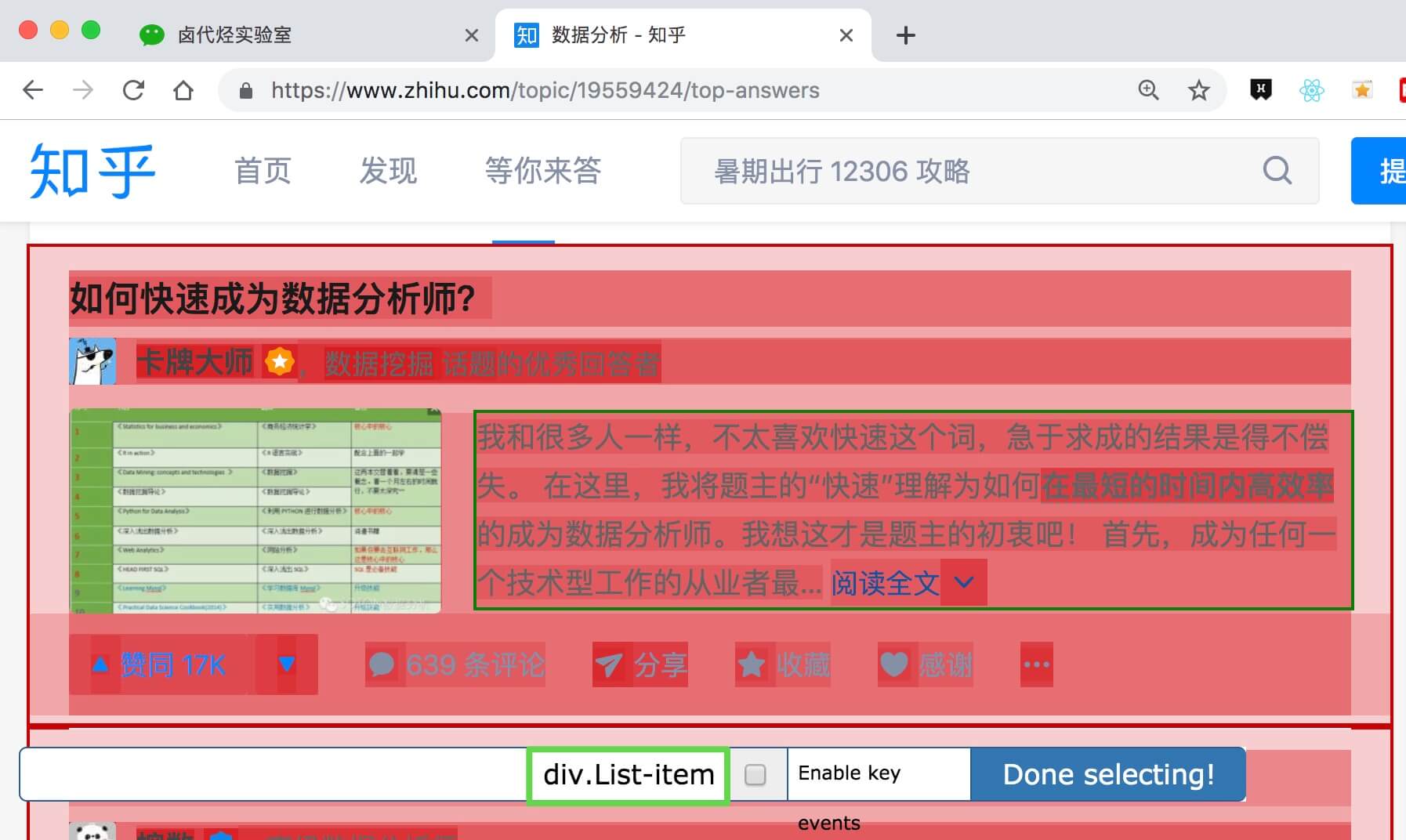
为了复习上一节通过数据编号控制条数的方法,我们在元素名后加个 nth-of-type(-n+100) ,暂时只抓取前 100 条数据。
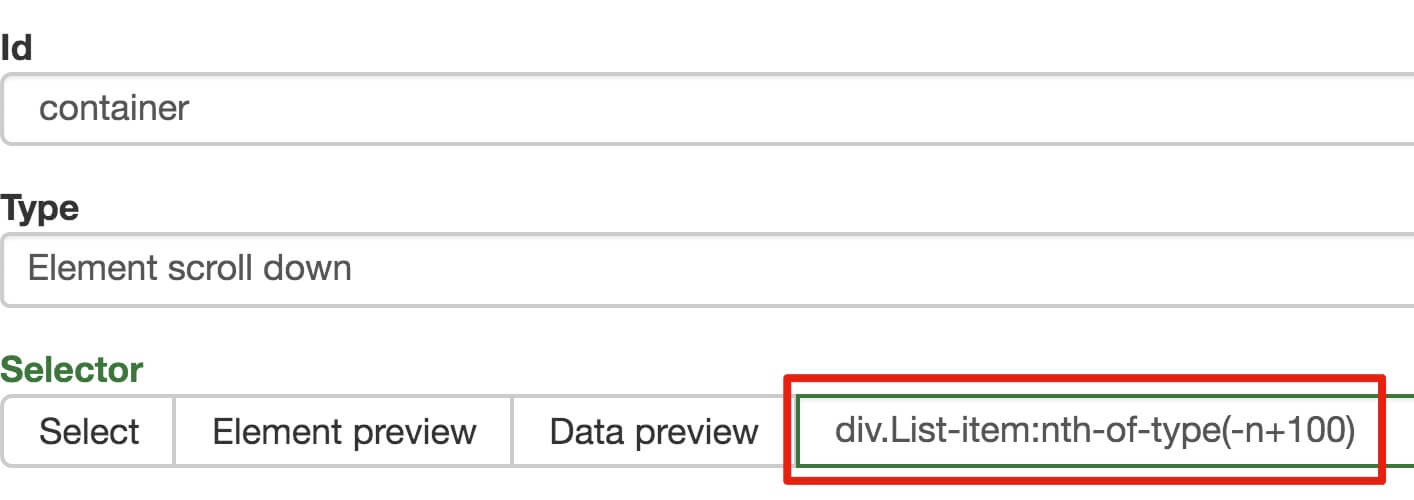
然后我们保存 container 这个节点,并在这个节点下选择要抓取的三个数据类型。
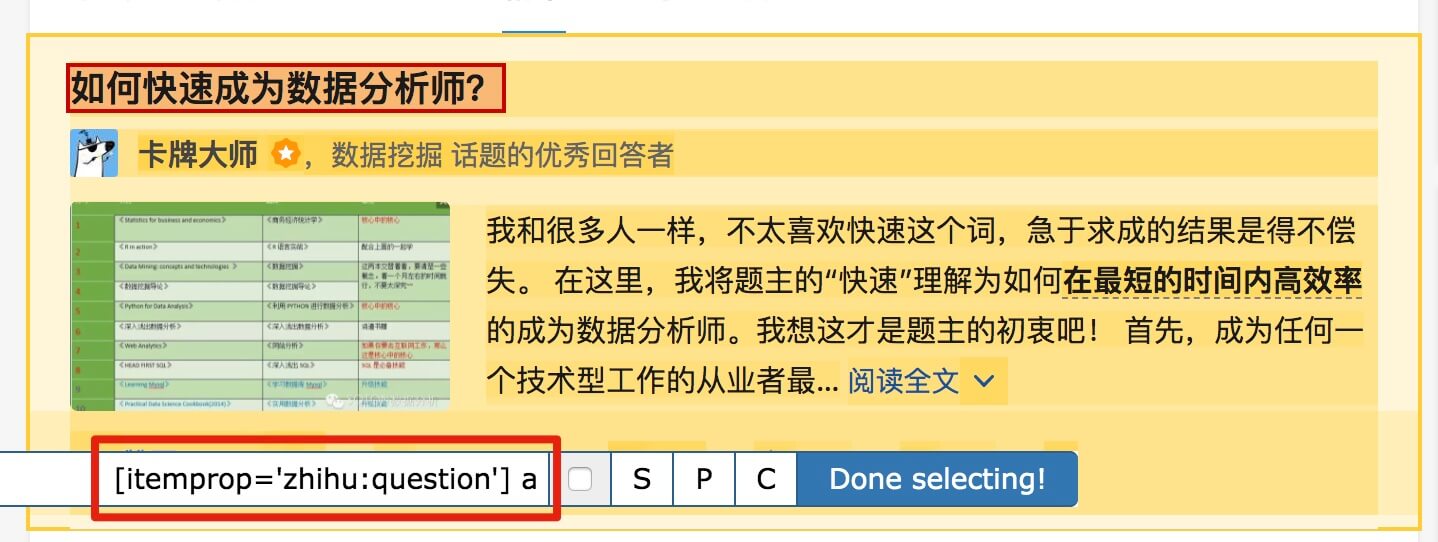
首先是标题,我们取名为 title,选择的元素名为 [itemprop='zhihu:question'] a:
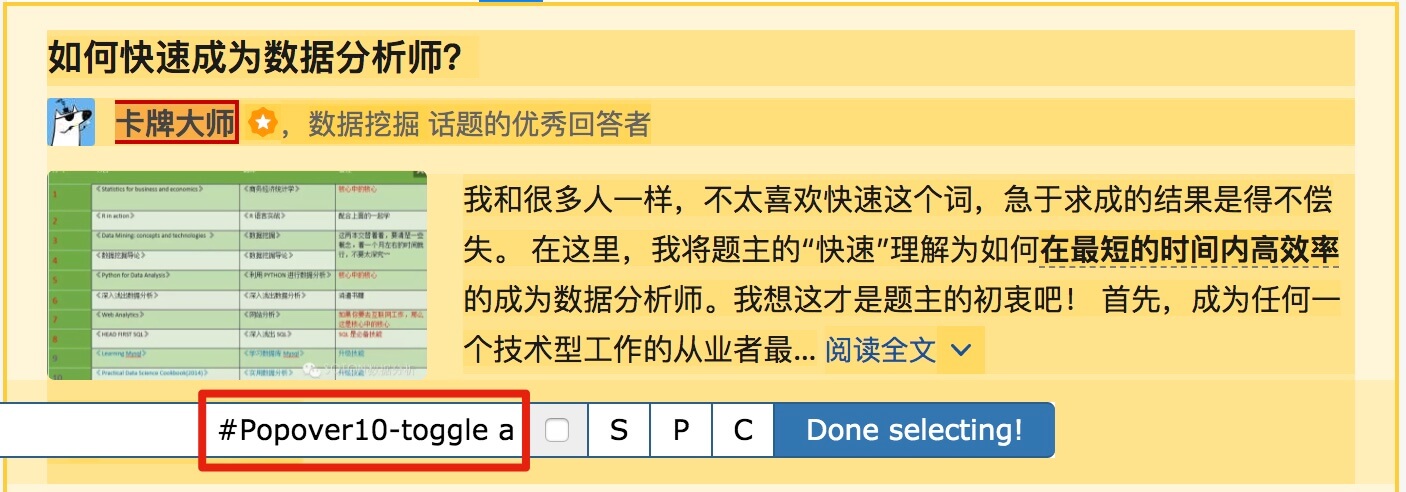
然后是答题人名字 name 与 赞同数 like,选择的元素名分别为 #Popover10-toggle a 和 button.VoteButton--up:

2.爬取数据,发现问题
元素都选择好了,我们按 Sitemap zhihu_top_answers -> Scrape -> Start craping 的路径进行数据抓取,等待十几秒结果出来后,内容却让我们傻了眼:
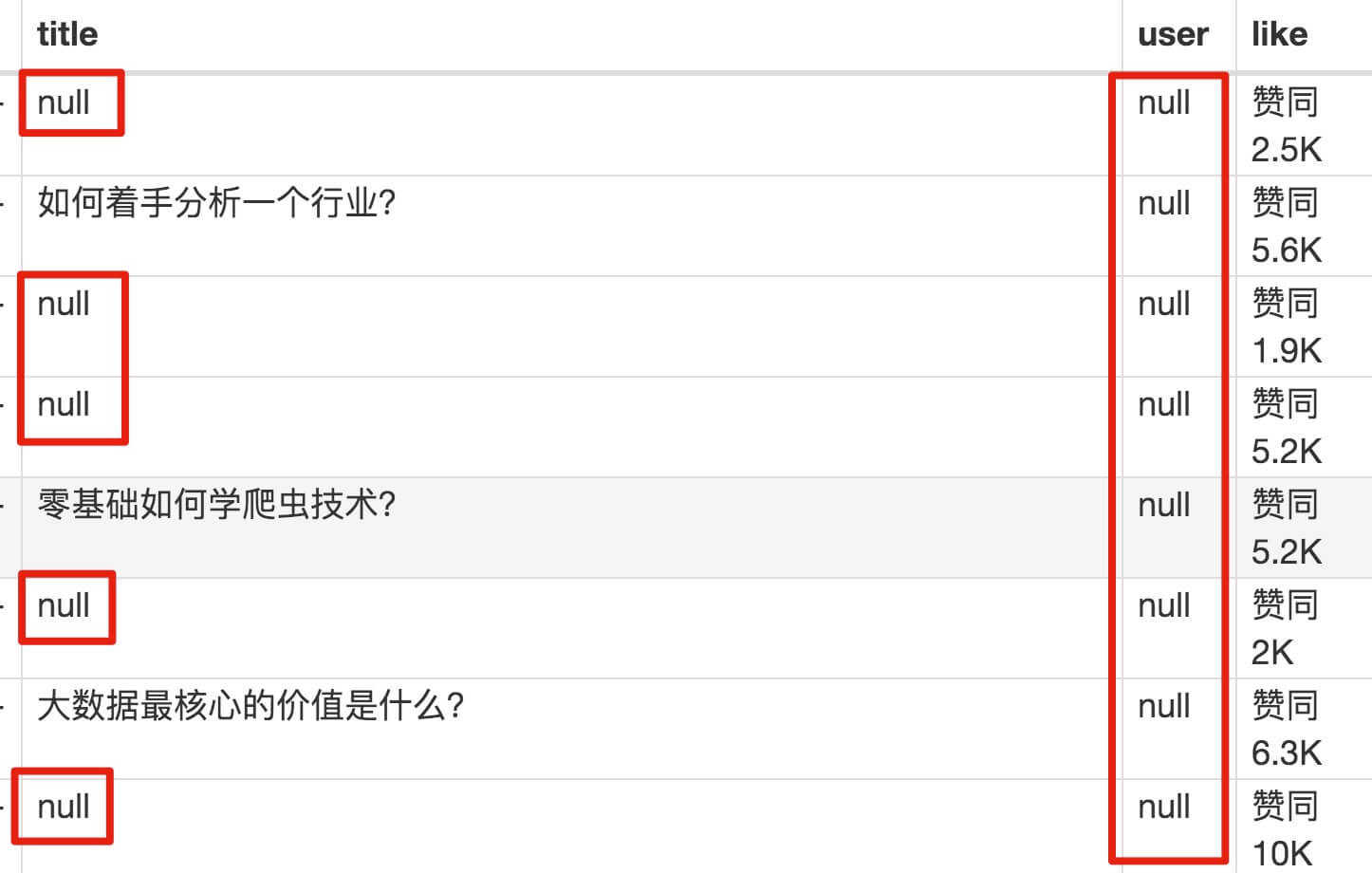
数据呢?我要抓的数据呢?怎么全变成了 null?
在计算机领域里,null 一般表示空值,表示啥都没有,放在 Web Scraper 里,就表示没有抓取到数据。
我们可以回想一下,网页上的的确确存在数据,我们在整个的操作过程中,唯一的变数就是选择元素这个操作上。所以,肯定是我们选择元素时出错了,导致内容匹配上出了问题,无法正常抓取数据。要解决这个问题,我们就要查看一下网页的构成。
3.分析问题
查看一下网页的构成,就要用浏览器的另一个功能了,那就是选择查看元素。
1.我们点击控制面板左上角的箭头,这时候箭头颜色会变蓝。
2.然后我们把鼠标移动到标题上,标题会被一个蓝色的半透明遮罩盖住。
3.我们再点击一下标题,会发现我们会跳转到 Elements 这个子面板,内容是一些花花绿绿看不大懂的代码
做到这里心里别发怵,这些 HTML 代码不涉及什么逻辑,在网页里就是个骨架,提供一些排版的作用。如果你平常用 markdown 写作,就可以把 HTML 理解为功能更复杂的 markdown。
结合 HTML 代码,我们先看看 [itemprop='zhihu:question'] a 这个匹配规则是怎么回事。
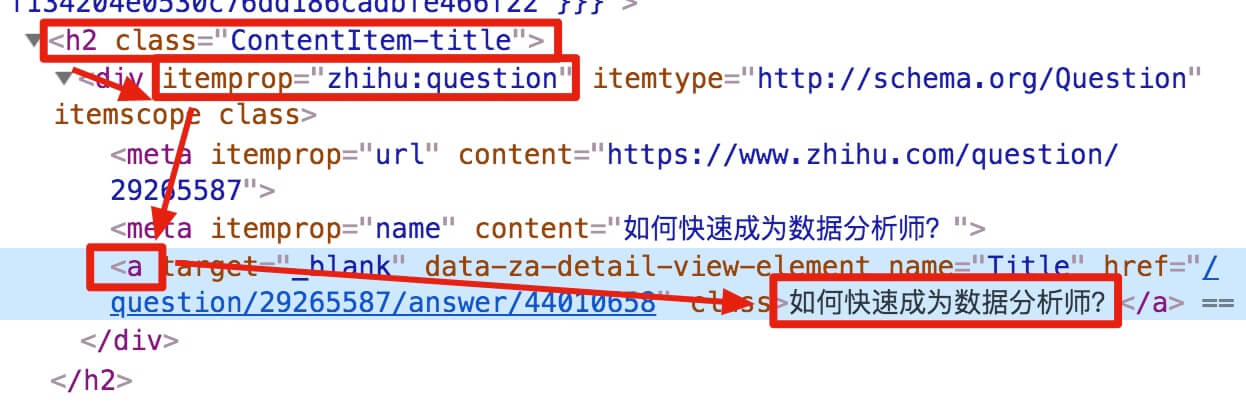
首先这是个树形的结构:
- 先是一个名字为 h2 的标签
<h2>...</h2>,它有个class='ContentItem-title'的属性; - 里面又有个名为 div 的标签
<div>...</div>,它有个itemprop='zhihu:question'的属性; - div 标签里又有一个 名字为 a 的标签
<a>...</a>; - a 标签里有一行字,就是我们要抓取的标题:
如何快速成为数据分析师?
上句话从可视化的角度分析,其实就是一个嵌套的结构,我把关键内容抽离出来,内容结构是不是清晰了很多?
<h2 class='ContentItem-title'/>
<div itemprop='zhihu:question'/>
<a>如何快速成为数据分析师?</a>
</div>
</h2>
我们再分析一个抓取标题为 null 的标题 HTML 代码。
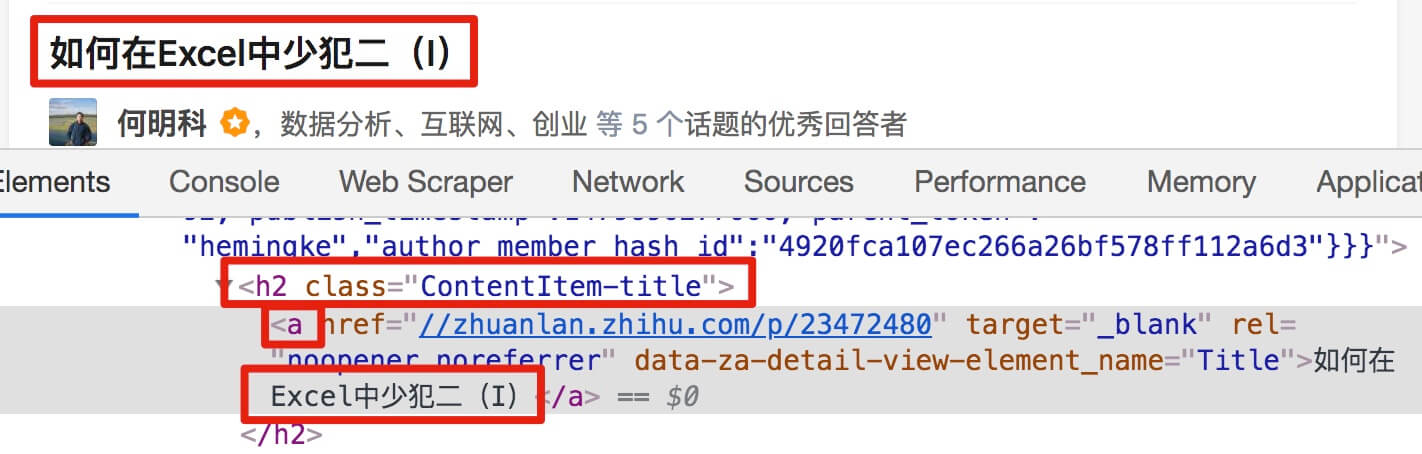
我们可以很清楚的观察到,在这个标题的代码里,少了名为 div 属性为 itemprop='zhihu:question' 的标签!这样导致我们的匹配规则匹配时找不到对应标签,Web Scraper 就会放弃匹配,认为找不到对应内容,所以就变成 null 了。
找到原因后我们就好解决问题了。
4.解决问题
我们发现,选择标题时,无论标题的嵌套关系怎么变,总有一个标签不变,那就是包裹在最外层的,属性名为 class='ContentItem-title' 的 h2 标签。我们如果能直接选择 h2 标签,不就可以完美匹配标题内容了吗?
逻辑上理清了关系,我们如何用 Web Scraper 操作?这时我们就可以用上一篇文章介绍的内容,利用键盘 P 键选择元素的父节点:
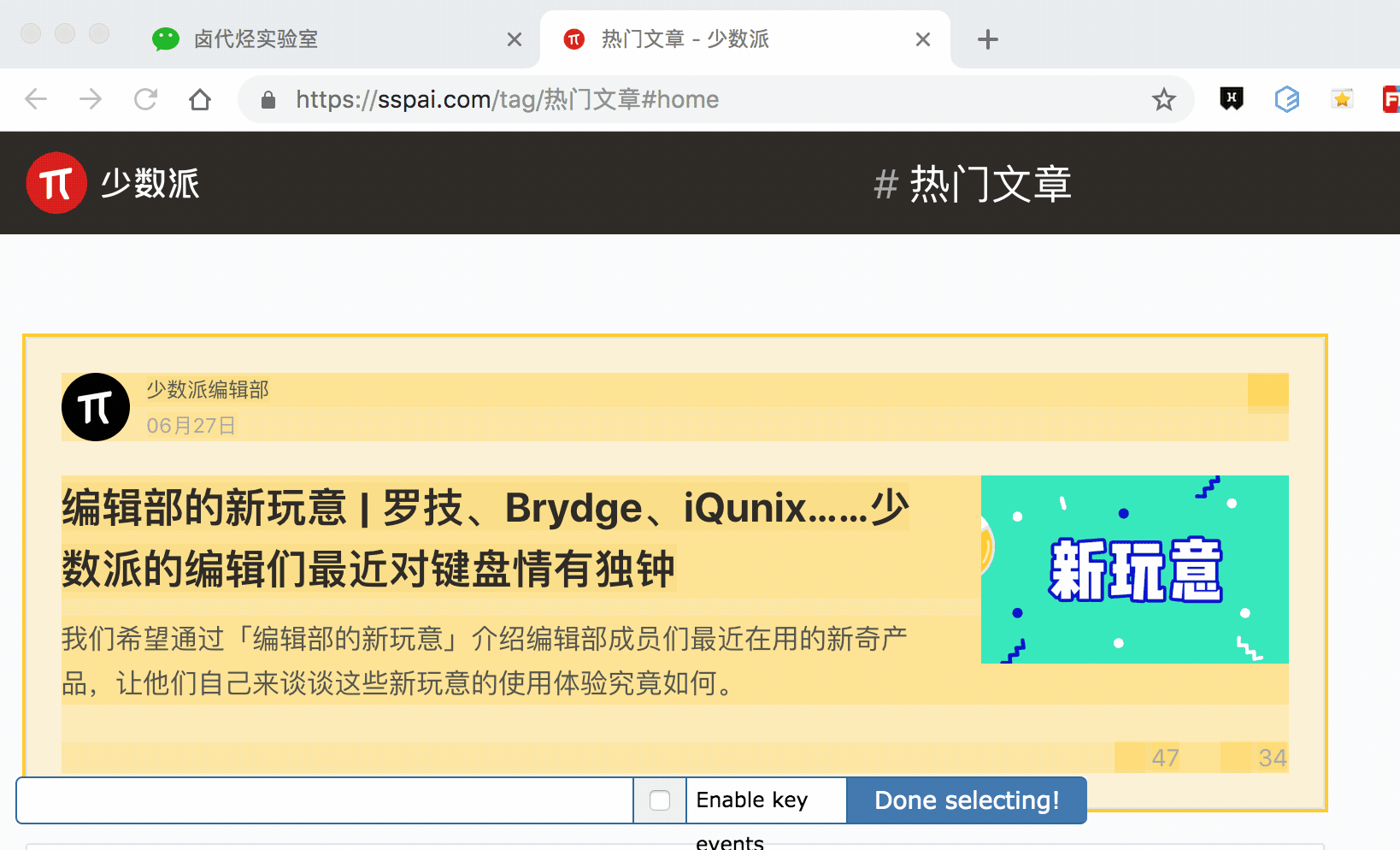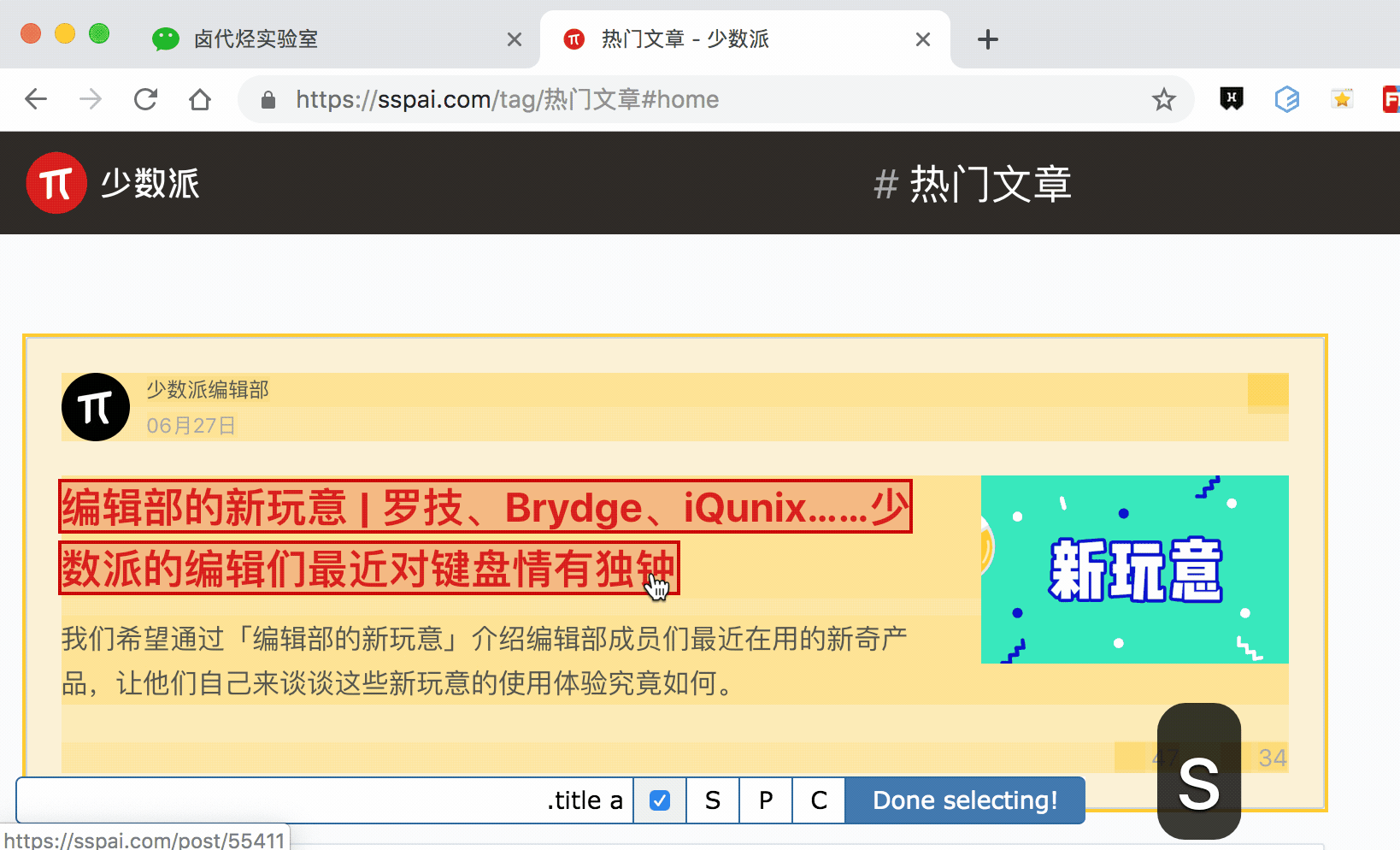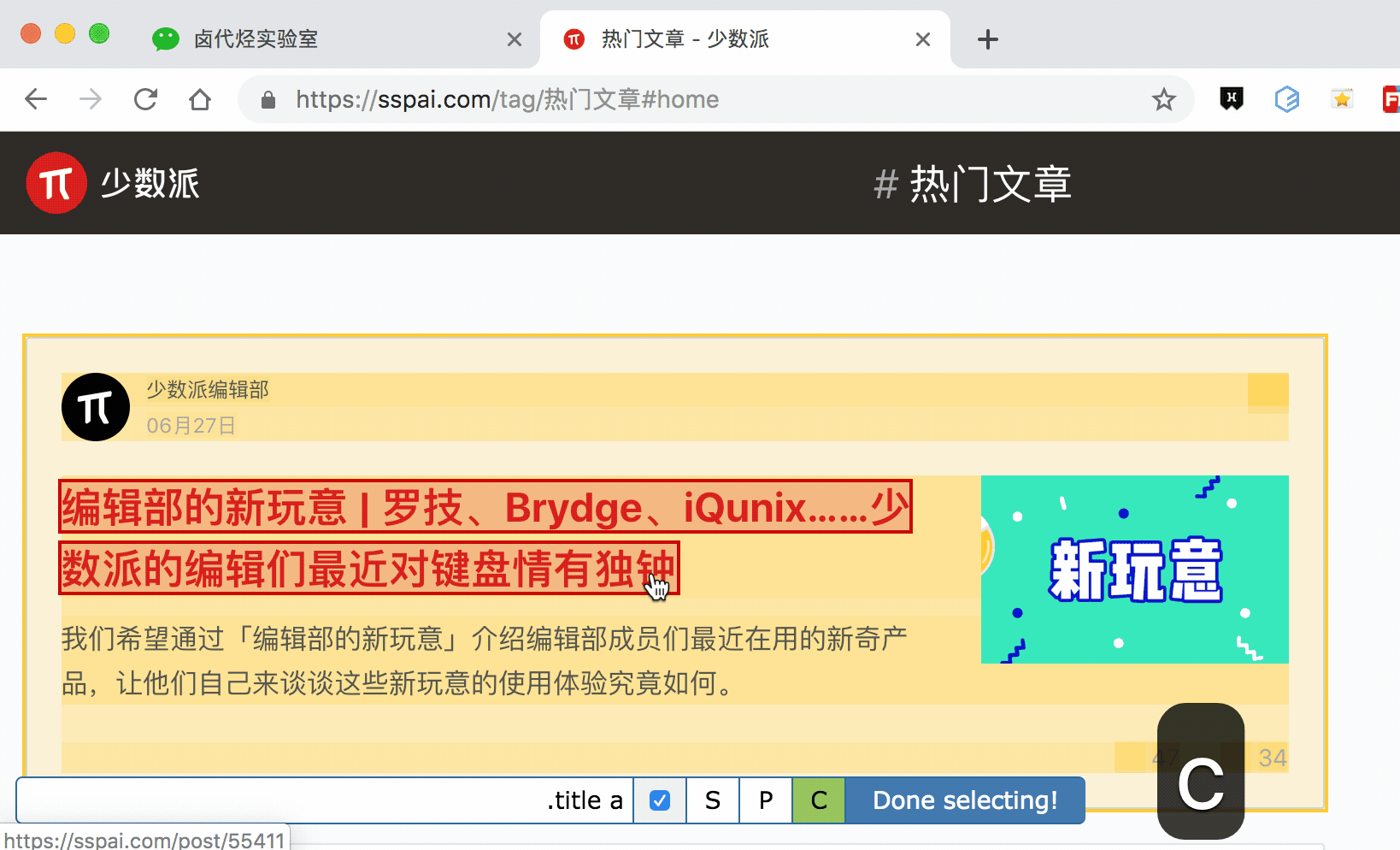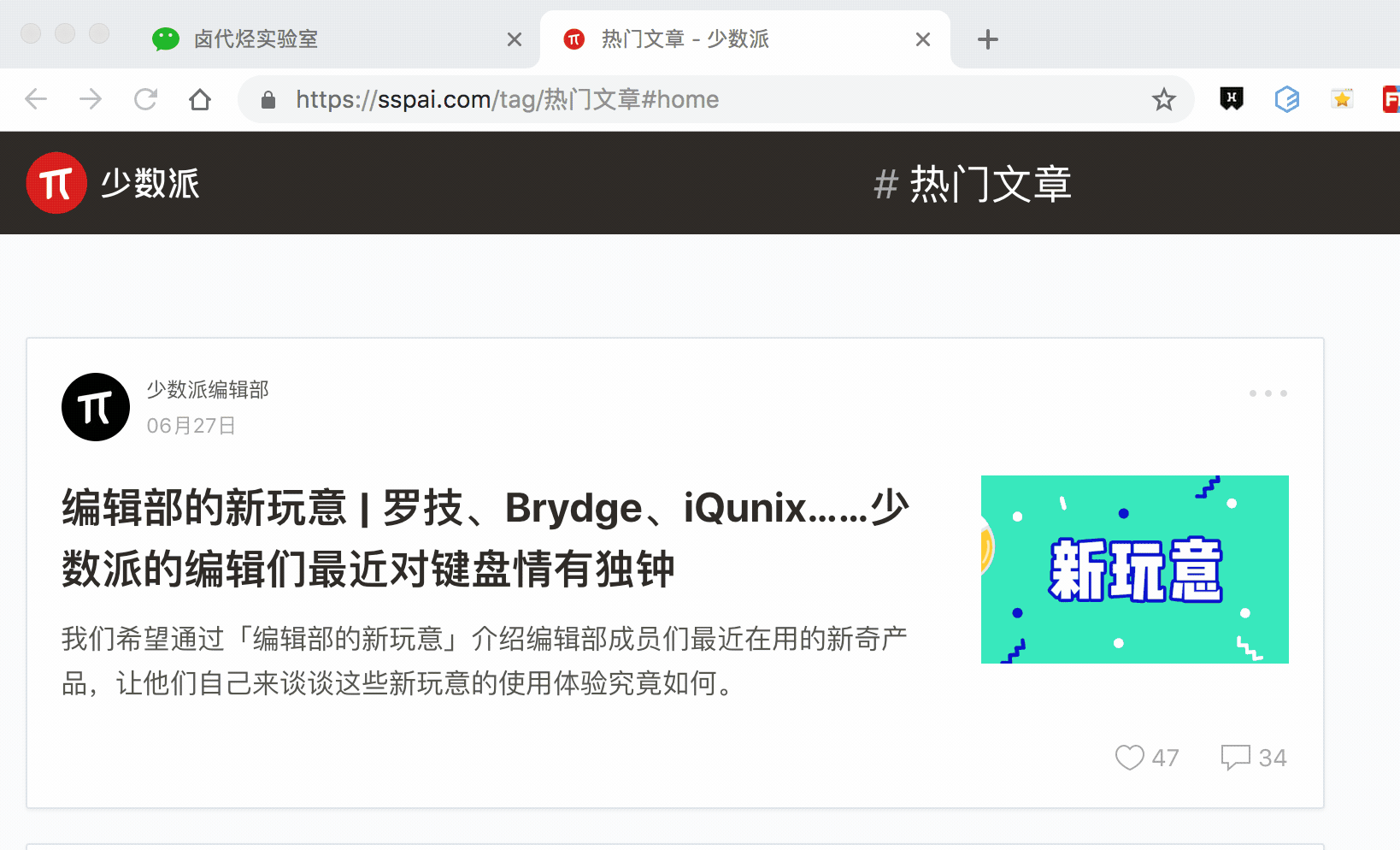
放在今天的课程里,我们点击两次 P 键,就可以匹配到标题的父标签 h2 (或 h2.ContentItem-title):

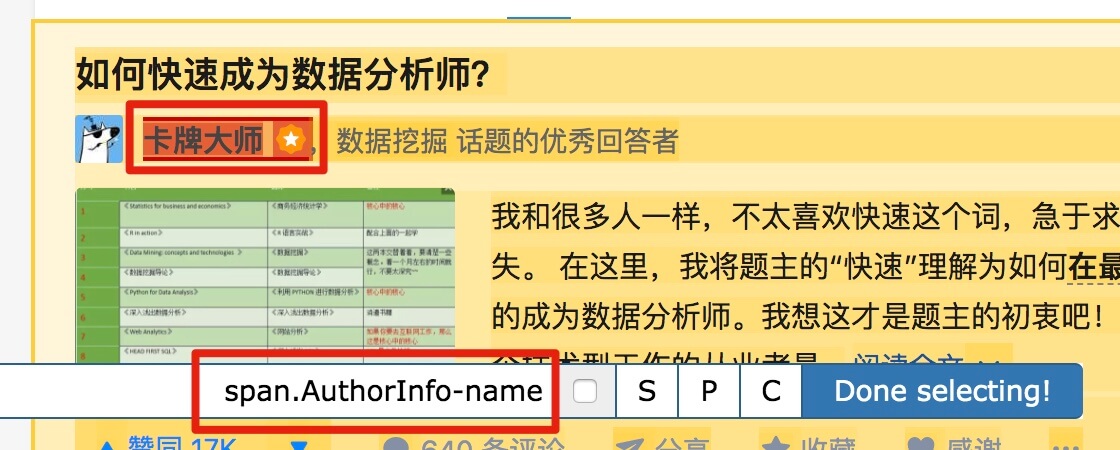
以此类推,因为答题人名字也出现了 null,我们分析了 HTML 结构后选择名字的父标签 span.AuthorInfo-name,具体的分析操作和上面差不多,大家可以尝试一下。
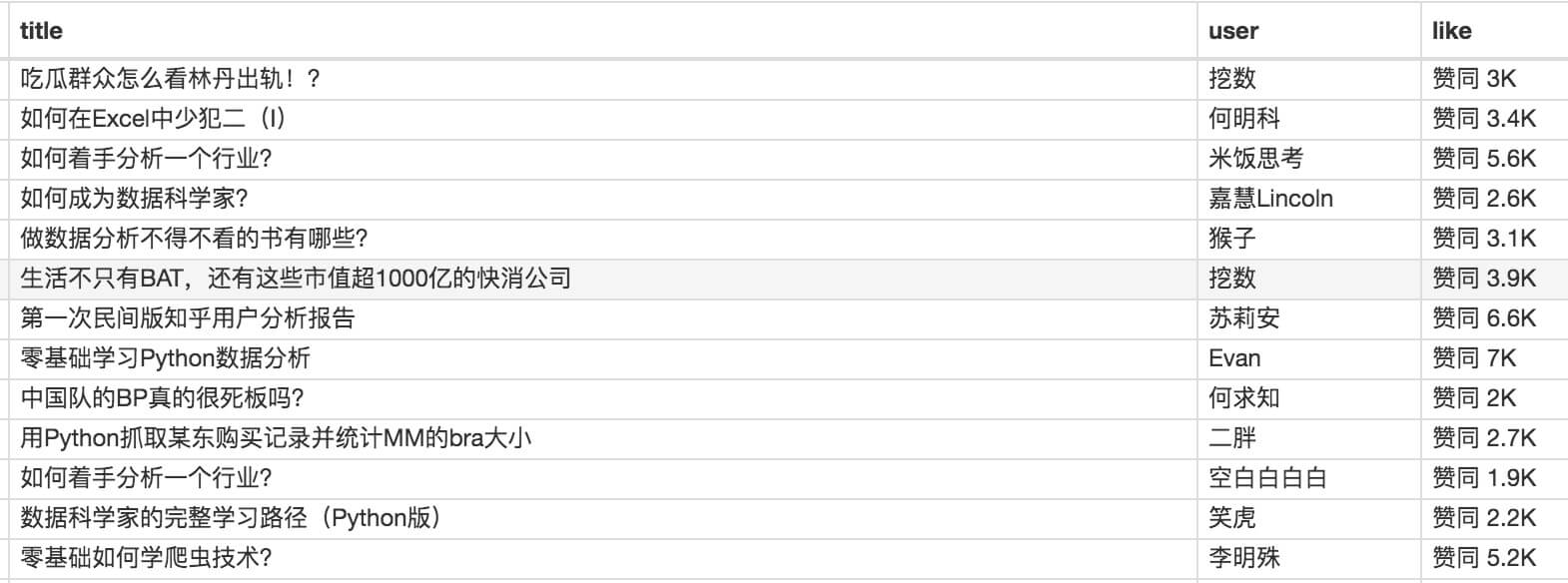
我的三个子内容的选择器如下,可以作为一个参考:

最后我们点击 Scrape 爬取数据,检查一下结果,没有出现 null,完美!
5.吐槽时间
爬取知乎数据时,我们会发现滚动加载数据那一块儿很快就做完了,在元素匹配那里却花了很多时间。
这间接的说明,知乎这个网站从代码角度上分析,写的还是比较烂的。
如果你爬取的网站多了,就会发现大部分的网页结构都是比较「随心所欲」的。所以在正式抓取数据前,经常要先做小规模的尝试,比如说先抓取 20 条,看看数据有没有问题。没问题后再加大规模正式抓取,这样做一定程度上可以减少返工时间。
6.下期预告
这期内容比较多,大家可以多看几遍消化一下,下期我们说些简单的内容,讲讲如何抓取表格内容。
7.推荐阅读
简易数据分析 09 | Web Scraper 自动控制抓取数量 & Web Scraper 父子选择器
简易数据分析 08 | Web Scraper 翻页——点击「更多按钮」翻页
8.联系我
因为文章发在各大平台上,账号较多不能及时回复评论和私信,有问题可关注公众号 ——「卤蛋实验室」,(或 wx 搜索 egglabs)关注上车防失联。

简易数据分析 10 | Web Scraper 翻页——抓取「滚动加载」类型网页的更多相关文章
- 简易数据分析 12 | Web Scraper 翻页——抓取分页器翻页的网页
这是简易数据分析系列的第 12 篇文章. 前面几篇文章我们介绍了 Web Scraper 应对各种翻页的解决方法,比如说修改网页链接加载数据.点击"更多按钮"加载数据和下拉自动加载 ...
- 简易数据分析 08 | Web Scraper 翻页——点击「更多按钮」翻页
这是简易数据分析系列的第 8 篇文章. 我们在Web Scraper 翻页--控制链接批量抓取数据一文中,介绍了控制网页链接批量抓取数据的办法. 但是你在预览一些网站时,会发现随着网页的下拉,你需要点 ...
- 简易数据分析 04 | Web Scraper 初尝--抓取豆瓣高分电影
这是简易数据分析系列的第 4 篇文章. 今天我们开始数据抓取的第一课,完成我们的第一个爬虫.因为是刚刚开始,操作我会讲的非常详细,可能会有些啰嗦,希望各位不要嫌弃啊:) 有人之前可能学过一些爬虫知识, ...
- Web Scraper 翻页——利用 Link 选择器翻页 | 简易数据分析 14
这是简易数据分析系列的第 14 篇文章. 今天我们还来聊聊 Web Scraper 翻页的技巧. 这次的更新是受一位读者启发的,他当时想用 Web scraper 爬取一个分页器分页的网页,却发现我之 ...
- 简易数据分析 11 | Web Scraper 抓取表格数据
这是简易数据分析系列的第 11 篇文章. 今天我们讲讲如何抓取网页表格里的数据.首先我们分析一下,网页里的经典表格是怎么构成的. First Name 所在的行比较特殊,是一个表格的表头,表示信息分类 ...
- 简易数据分析 13 | Web Scraper 抓取二级页面
这是简易数据分析系列的第 13 篇文章. 不知不觉,web scraper 系列教程我已经写了 10 篇了,这 10 篇内容,基本上覆盖了 Web Scraper 大部分功能.今天的内容算这个系列的最 ...
- 简易数据分析 09 | Web Scraper 自动控制抓取数量 & Web Scraper 父子选择器
这是简易数据分析系列的第 9 篇文章. 今天我们说说 Web Scraper 的一些小功能:自动控制 Web Scraper 抓取数量和 Web Scraper 的父子选择器. 如何只抓取前 100 ...
- Web Scraper 翻页——控制链接批量抓取数据(Web Scraper 高级用法)| 简易数据分析 05
这是简易数据分析系列的第 5 篇文章. 上篇文章我们爬取了豆瓣电影 TOP250 前 25 个电影的数据,今天我们就要在原来的 Web Scraper 配置上做一些小改动,让爬虫把 250 条电影数据 ...
- 简易数据分析 07 | Web Scraper 抓取多条内容
这是简易数据分析系列的第 7 篇文章. 在第 4 篇文章里,我讲解了如何抓取单个网页里的单类信息: 在第 5 篇文章里,我讲解了如何抓取多个网页里的单类信息: 今天我们要讲的是,如何抓取多个网页里的多 ...
随机推荐
- 初识Grep
前言:grep这个命令都不陌生,最常用的就是和管道符结合,例如:ps -ef | grep docker,但是我还是想认识一下这个非常giao的命令... Grep称为全局正则表达式检索工具,在企业中 ...
- 【Aizu - 0033】Ball (简单搜索)
-->Ball 原文是日语,这里直接写中文了 Descriptions: 如图所示,容器中间有一枢轴,下方分为两路.容器上方开口,从1到10连续编号的小球从容器开口A放入.通过调整枢轴E的方向, ...
- 谷歌地球 Google Earth v7.3.2.5495 专业版
谷歌地球(Google Earth,GE)是一款谷歌公司开发的虚拟地球软件,它把卫星照片.航空照相和GIS布置在一个地球的三维模型上.谷歌地球于2005年向全球推出,被<PC 世界杂志>评 ...
- shell脚本常见错误一二三
1.$'\r': 未找到命令的解决 2.: 不是有效的标识符h: 3.cd "$path"/webapps/ROOT 不能正常进入ROOT文件夹,$path并未与后面的字符结合起来 ...
- Java编程思想:利用内部类实现的工厂模式
public class Test { public static void main(String[] args) { Factories.test(); } } /* 设计模式之禅中的工厂模式是这 ...
- java高并发系列 - 第14天:JUC中的LockSupport工具类,必备技能
这是java高并发系列第14篇文章. 本文主要内容: 讲解3种让线程等待和唤醒的方法,每种方法配合具体的示例 介绍LockSupport主要用法 对比3种方式,了解他们之间的区别 LockSuppor ...
- 6.1.初识Flutter应用之实现一个计数器
用Android Studio和VS Code创建的Flutter应用模板是一个简单的计数器示例,本节先仔细讲解一下这个计数器Demo的源码,让读者对Flutter应用程序结构有个基本了解,在随后小节 ...
- Excel催化剂开源第43波-Excel选择对象Selection在.Net开发中的使用
Excel的二次开发有一极大的优势所在,可以结合用户的交互进行程序的运行,大量用户的交互,都是从选择对象开始,用户选择了单元格区域.图形.图表等对象,之后再进行程序代码的加工处理,生成用户所需的最终结 ...
- 基于surging 的stage组件设计,谈谈我眼中的微服务。
一.前言 随着业务的发展,并发量的增多,业务的复杂度越来越大,对于系统架构能力要求越来越高,这时候微服务的设计思想应运而生,但是对于微服务需要引擎进行驱动,这时候基于.NET CORE 的微服务引擎s ...
- Java 面向对象面试题
1.Java面向对象的三种特性 封装:封装是把数据和操作数据的方法封装起来,对数据的访问只能通过已定义的接口进行访问. Java的四种访问控制符: - 默认的(default):不使用任何修饰符,在同 ...