虚拟机spark集群搭建
RDD弹性分布式数据集 (Resilient Distributed Dataset)
RDD只读可分区,数据集可以缓存在内存中,在多次计算间重复利用。
弹性是指内存不够时可以与磁盘进行交互
join操作就是笛卡尔积的操作过程
spark streaming
实时数据流
Discretized Streams (DStreams) 离散流
Graphx
图计算
spark sql
使用SchemaRDD来操作SQL
MLBase机器学习
MLlib算法库
Tachyon
高容错分布式文件系统
scala环境
tar -xvf scala-2.11.8.tgz
mv scala-2.11.8/ scala
#配置环境变量
export SCALA_HOME=/usr/local/scala
export PATH=$SCALA_HOME/bin:$PATH
[root@sjck-node01 ~]# scala -version
Scala code runner version 2.11.8 -- Copyright 2002-2016, LAMP/EPFL
spark环境
tar -xvf spark-2.4.0-bin-hadoop2.7.tgz
mv scala-2.11.8/ scala
export SPARK_HOME=/usr/local/spark-2.4.0-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin
spark配置
cp spark-env.sh.template spark-env.sh
export JAVA_HOME=/usr/local/src/jdk/jdk1.8
export SCALA_HOME=/usr/local/scala
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export SPARK_MASTER_IP=sjck-node01
export SPARK_MASTER_HOST=sjck-node01
export SPARK_LOCAL_IP=sjck-node01
export SPARK_WORKER_MEMORY=1g
export SPARK_WORKER_CORES=2
export SPARK_HOME=/usr/local/spark-2.4.0-bin-hadoop2.7
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
slaves配置
cp slaves.template slaves
sjck-node02
sjck-node03
copy到slave节点,配置对应的环境变量
scp -r /usr/local/scala/ sjck-node02:/usr/local/
scp -r /usr/local/spark-2.4.0-bin-hadoop2.7/ sjck-node02:/usr/local/
vim spark-env.sh
把SPARK_LOCAL_IP改成对应的ip
启动顺序,先启动hadoop,再启动spark
/usr/local/hadoop/sbin/start-all.sh
/usr/local/spark-2.4.0-bin-hadoop2.7/sbin/start-all.sh
/usr/local/hadoop/sbin/stop-all.sh
/usr/local/spark-2.4.0-bin-hadoop2.7/sbin/stop-all.sh
[root@sjck-node01 ~]# /usr/local/spark-2.4.0-bin-hadoop2.7/sbin/start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /usr/local/spark-2.4.0-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.master.Master-1-sjck-node01.out
sjck-node02: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark-2.4.0-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-sjck-node02.out
sjck-node03: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark-2.4.0-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-sjck-node03.out
查看集群jps状态
[root@sjck-node01 ~]# jps
5233 Master
4595 NameNode
4788 SecondaryNameNode
5305 Jps
4942 ResourceManager
[root@sjck-node02 conf]# jps
3808 Worker
3538 DataNode
3853 Jps
3645 NodeManager
[root@sjck-node03 conf]# jps
3962 NodeManager
3851 DataNode
4173 Jps
4126 Worker
查看集群状态
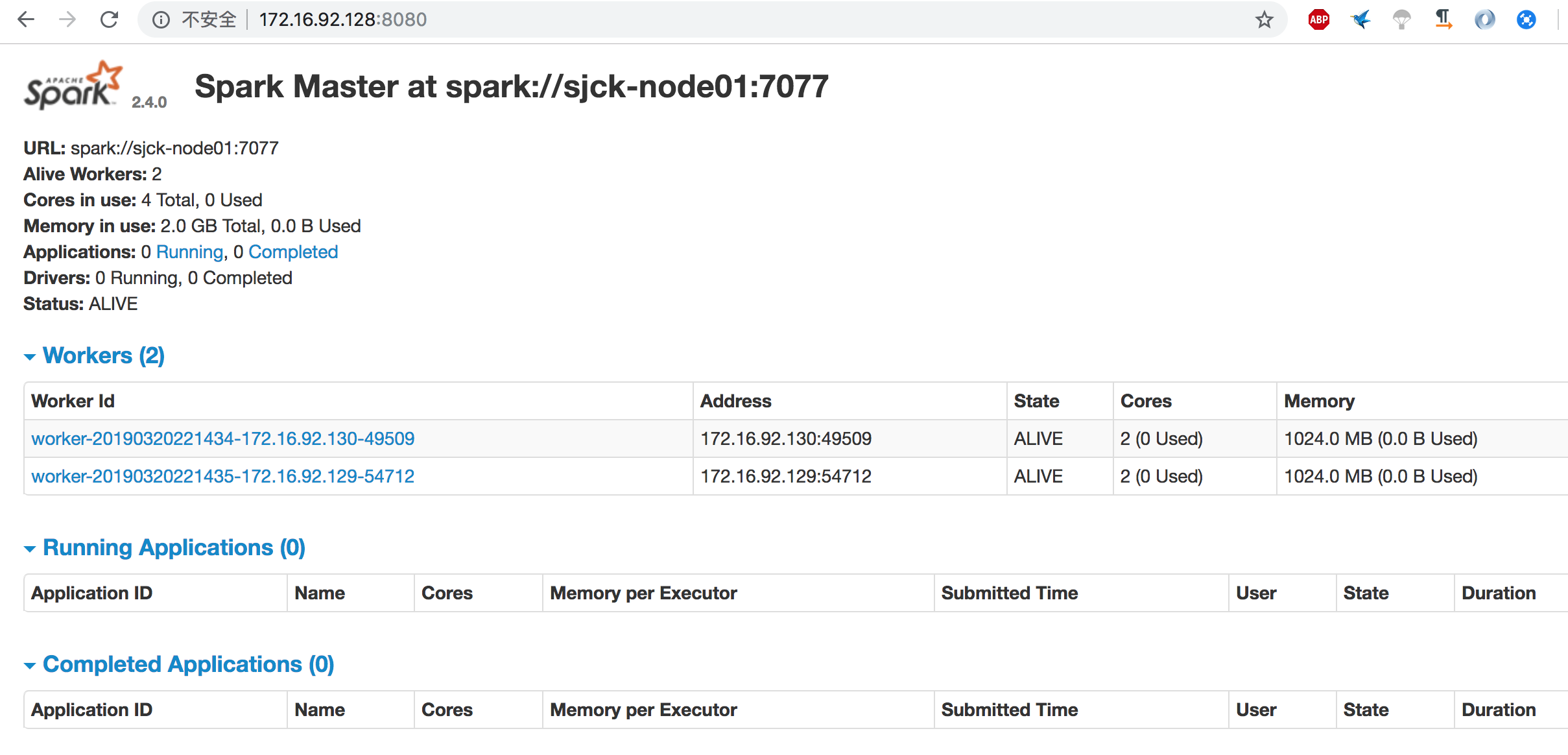
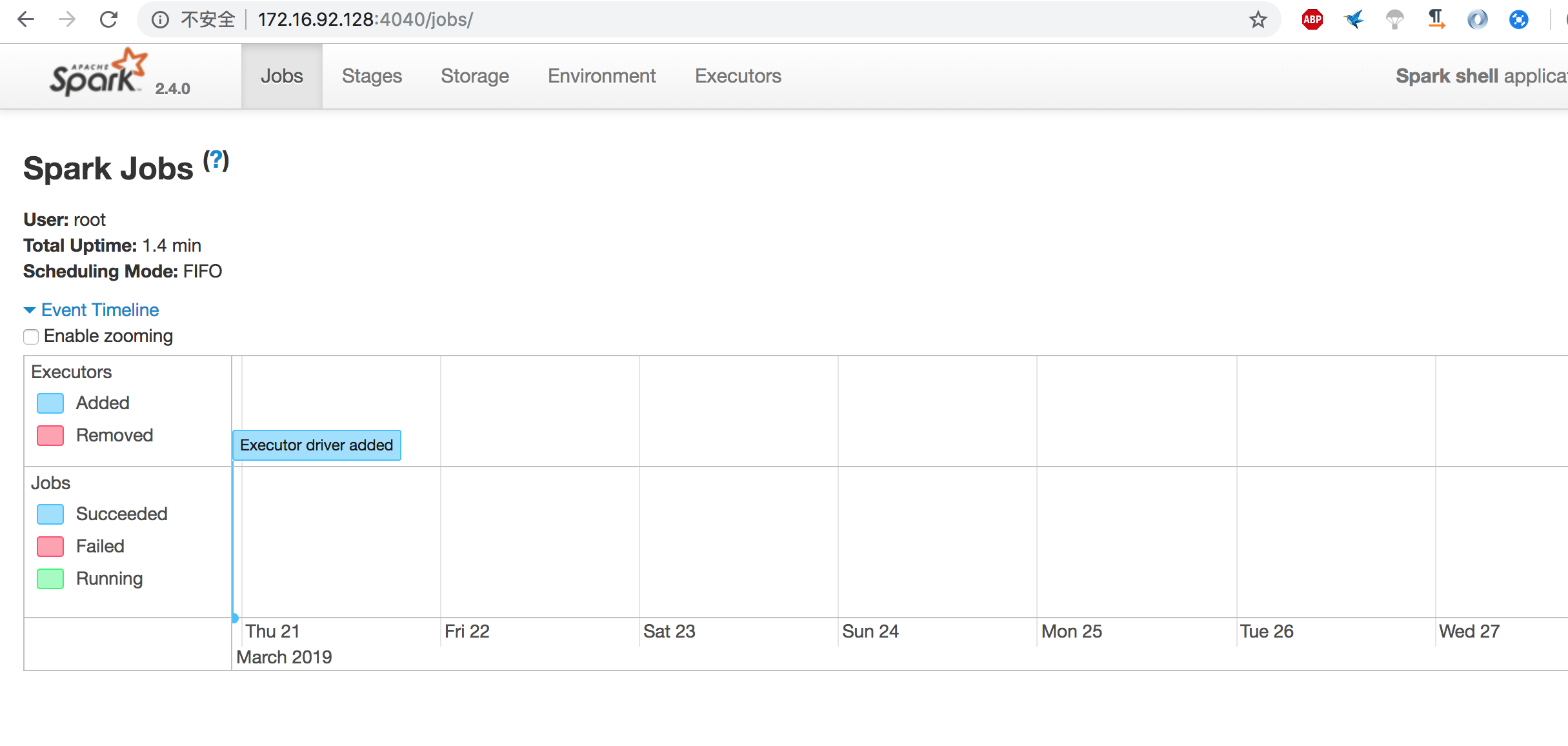
查看webui的jobs
http://172.16.92.128:4040/jobs/
pyspark,scall的是spark-shell
[root@sjck-node01 bin]# pyspark
Python 2.7.4 (default, Mar 21 2019, 00:09:49)
[GCC 4.4.7 20120313 (Red Hat 4.4.7-23)] on linux2
2019-03-21 20:53:11 WARN NativeCodeLoader:62 - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 2.4.0
/_/
Using Python version 2.7.4 (default, Mar 21 2019 00:09:49)
SparkSession available as 'spark'.
>>>
上传文件本地文件至HDFS
[root@sjck-node01 data]# hadoop fs -put /data/READ.md
[root@sjck-node01 data]# hadoop fs -ls
Found 1 items
-rw-r--r-- 2 root supergroup 3952 2019-03-23 21:07 READ.md
虚拟机spark集群搭建的更多相关文章
- Spark集群搭建简配+它到底有多快?【单挑纯C/CPP/HADOOP】
最近耳闻Spark风生水起,这两天利用休息时间研究了一下,果然还是给人不少惊喜.可惜,笔者不善JAVA,只有PYTHON和SCALA接口.花了不少时间从零开始认识PYTHON和SCALA,不少时间答了 ...
- Spark集群搭建中的问题
参照<Spark实战高手之路>学习的,书籍电子版在51CTO网站 资料链接 Hadoop下载[链接](http://archive.apache.org/dist/hadoop/core/ ...
- spark集群搭建
文中的所有操作都是在之前的文章scala的安装及使用文章基础上建立的,重复操作已经简写: 配置中使用了master01.slave01.slave02.slave03: 一.虚拟机中操作(启动网卡)s ...
- hadoop+spark集群搭建入门
忽略元数据末尾 回到原数据开始处 Hadoop+spark集群搭建 说明: 本文档主要讲述hadoop+spark的集群搭建,linux环境是centos,本文档集群搭建使用两个节点作为集群环境:一个 ...
- (四)Spark集群搭建-Java&Python版Spark
Spark集群搭建 视频教程 1.优酷 2.YouTube 安装scala环境 下载地址http://www.scala-lang.org/download/ 上传scala-2.10.5.tgz到m ...
- Spark集群搭建简要
Spark集群搭建 1 Spark编译 1.1 下载源代码 git clone git://github.com/apache/spark.git -b branch-1.6 1.2 修改pom文件 ...
- Spark集群搭建_Standalone
2017年3月1日, 星期三 Spark集群搭建_Standalone Driver: node1 Worker: node2 Worker: node3 1.下载安装 下载地址 ...
- Spark集群搭建_YARN
2017年3月1日, 星期三 Spark集群搭建_YARN 前提:参考Spark集群搭建_Standalone 1.修改spark中conf中的spark-env.sh 2.Spark on ...
- Spark 集群搭建
0. 说明 Spark 集群搭建 [集群规划] 服务器主机名 ip 节点配置 s101 192.168.23.101 Master s102 192.168.23.102 Worker s103 19 ...
随机推荐
- idea绘制activity流程图中文乱码解决
发现问题: 绘制activity的bpm工作流程图的时候,在name项中填写中文,开始的时候没问题,显示的确是中文,关闭文件再打开发现已经乱码,重启idea效果相同,如图 解决方案:修改idea启动参 ...
- LintCode 58: Compare Strings
LintCode 58: Compare Strings 题目描述 比较两个字符串A和B,确定A中是否包含B中所有的字符.字符串A和B中的字符都是大写字母. 样例 给出A = "ABCD&q ...
- 《区块链100问》第85集:资产代币化之对标美元USDT
USDT是Tether公司推出的对标美元(USD)的代币Tether USD.1USDT=1美元,用户可以随时使用USDT与USD进行1:1兑换.Tether公司执行1:1准备金保证制度,即每个USD ...
- UNIX网络编程 第4章 基本TCP套接字编程
本章的几个函数在很大程度上展示了面向对象与面向过程的不同之处.
- 安裝HA服務
**************************************************************************************************** ...
- ActiveMQ监听消息并进行转发,监听不同的mq服务器和不同的队列
工作中刚接触mq消息业务,其实也就是监听一下别的项目发送的消息然后进行对应的转发,但是监听的mq会有多个,而且转发的地址也可能有多个,这里就使用spring集成的方式!记录一下实现方式: 监听多个mq ...
- 【CTF WEB】文件包含
文件包含 题目要求: 请找到题目中FLAG 漏洞源码 <meta charset='utf-8'> <center><h1>文件阅读器</h1>< ...
- 【HASPDOG】Communication error
靠,防火墙没关,关了防火墙生成文件成功
- python 根据输入的内容输出类型
类型判断 from functools import singledispatch import numbers from collections import abc from collection ...
- maven2 up to maven3的'version' contains an expression but should be a constant
在Maven2时,为了保障版本一致,一般之前我们的做法时: Parent Pom中 <project xmlns="http://maven.apache.org/POM/4.0.0& ...