TensorFlow GPU版本的安装与调试
笔者采用python3.6.7+TensorFlow1.12.0+CUDA10.0+CUDNN7.3.1构建环境
PC端配置为GTX 1050+Intel i7 7700HQ 4核心8线程@2.8GHZ
TensorFlow-gpu的安装经历实在是坎坷的很
首先显卡一定要支持
没想到的是GTX 1050TI,GTX 1070TI等主流显卡竟然都不支持
(还好我买的是GTX 1050)
(并没有暗示需要一块TESLA)
其次需要对好版本号,不同的TensorFlow版本对应的CUDA驱动程序版本号也有所不同
然而这还不够,还需要安装CUDNN才能完美运行,CUDNN的版本号和CUDA的版本号也要对好
但是下载CUDNN需要注册NVIDIA账号,那就点击join注册喽
注册的时候刚开始我使用了QQ邮箱,按道理这没毛病
但是到了验证邮箱一步又嗝屁了
你的验证邮件呢,验证邮件呢,邮件呢?????
经过百度多方查阅,原来不能用QQ邮箱
坑爹的是过了三个小时它又发过来了,没错,就是QQ邮箱,它发过来了。。。
不过我的163邮箱都注册好了。。。。。
所以就使用163邮箱注册了一个账号
终于顺利下载
下载完了也很懵逼
压缩包里面是长这样的:

使用这样的东西已经完全超出了我的能力范围了呀,怎么办
于是乎又百度,原来是放在CUDA的安装目录下呀。。。。
好的安装好了,听度娘说可以用安装目录\extras\demo_suite下的bandwidthTest.exe和deviceQuery.exe来检测
检测出来好像没什么问题
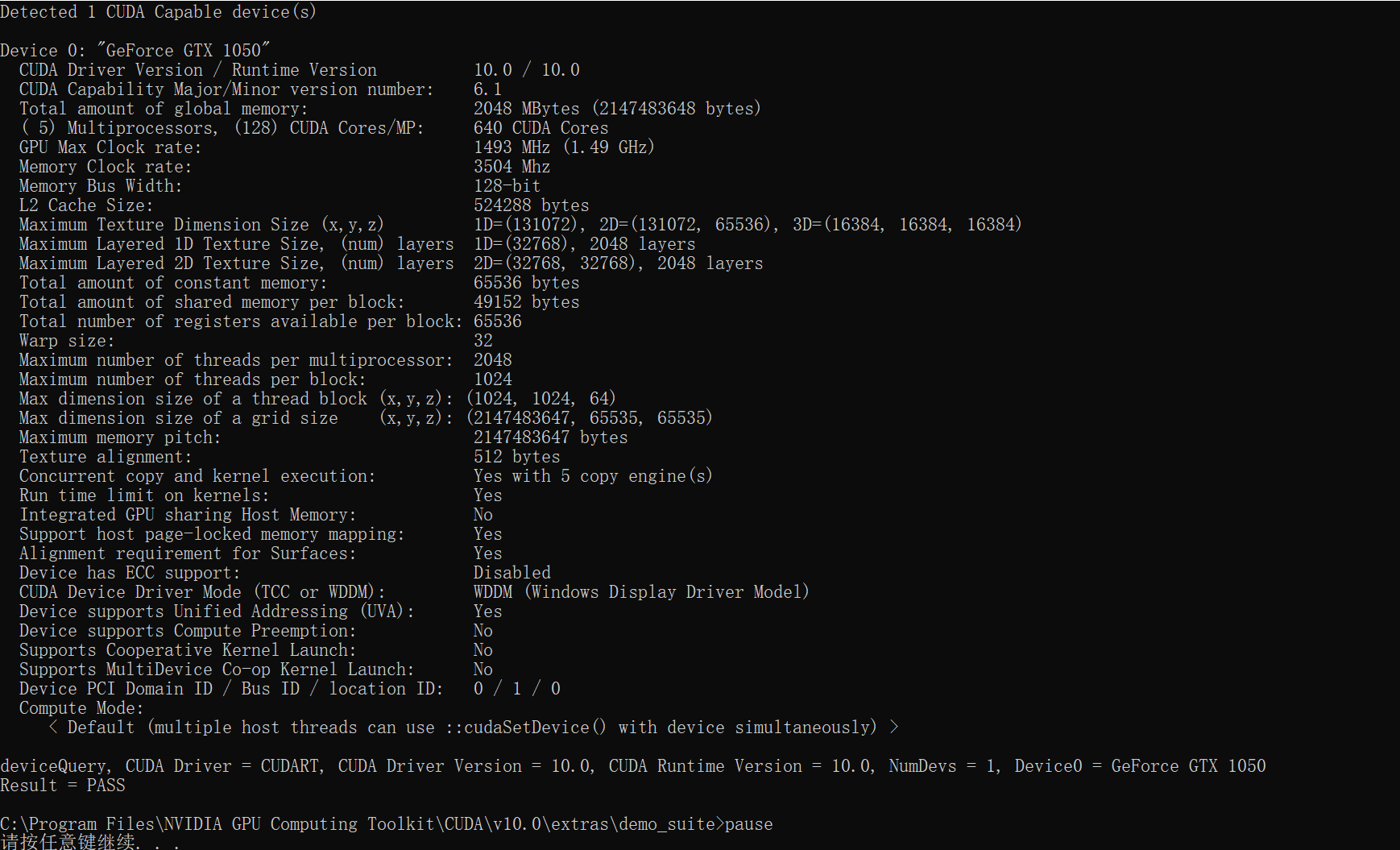
(图片中用了pause暂停来查看的)
然后环境搭载完成,到了万众瞩目的安装环节
pip install tensorflow-gpu
当然是需要卸载之前的版本的tensorflow 的
20KB/s的高速下了不知道多久
反正最后是装好了
大概是这样的

看起来还不错有没有
但是运行一下吧
。。。。。。。
下面的错误我都不忍心看,红了一片。。。。。
(画面太过血腥,已被屏蔽)
然后继续求助万能的度娘
最后找到了这个帖子
Win10 +VS2017+ python3.66 + CUDA10 + cuDNNv7.3.1 + tensorflow-gpu 1.12.0
你早说不支持CUDA10.0嘛,害的我费那么大力
于是就看了下这个贴子里面所附带的大佬创作的安装包
tensorflow_gpu-1.12.0-cp36-cp36m-win_amd64.whl
CUDA10.0+CUDNN7.3.1
然后又跑去重新安装CUDNN7.3.1
再cd到安装包目录下
pip install tensorflow_gpu-1.12.0-cp36-cp36m-win_amd64.whl
效果拔群,最终安装完成

如图
(当时看到可把我激动惨了)
至此安装完成
既然安装了就来测试一下喽,不测试的话显得自己很捞
求助度娘找到了大佬写的五层卷积神经网络的代码
Tensorflow对比AlexNet的CPU和GPU运算效率
为了简便起见,就直接放经过我魔改的大佬的代码
from datetime import datetime
import math
import time
import tensorflow as tf
import os
#os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
#os.environ["CUDA_VISIBLE_DEVICES"] = "-1"
batch_size = 32
num_batches = 100
# 该函数用来显示网络每一层的结构,展示tensor的尺寸 def print_activations(t):
print(t.op.name, ' ', t.get_shape().as_list()) # with tf.name_scope('conv1') as scope # 可以将scope之内的variable自动命名为conv1/xxx,便于区分不同组件 def inference(images):
parameters = []
# 第一个卷积层
with tf.name_scope('conv1') as scope:
# 卷积核、截断正态分布
kernel = tf.Variable(tf.truncated_normal([11, 11, 3, 64],
dtype=tf.float32, stddev=1e-1), name='weights')
conv = tf.nn.conv2d(images, kernel, [1, 4, 4, 1], padding='SAME')
# 可训练
biases = tf.Variable(tf.constant(0.0, shape=[64], dtype=tf.float32), trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv1 = tf.nn.relu(bias, name=scope)
print_activations(conv1)
parameters += [kernel, biases]
# 再加LRN和最大池化层,除了AlexNet,基本放弃了LRN,说是效果不明显,还会减速?
lrn1 = tf.nn.lrn(conv1, 4, bias=1.0, alpha=0.001 / 9, beta=0.75, name='lrn1')
pool1 = tf.nn.max_pool(lrn1, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1], padding='VALID', name='pool1')
print_activations(pool1)
# 第二个卷积层,只有部分参数不同
with tf.name_scope('conv2') as scope:
kernel = tf.Variable(tf.truncated_normal([5, 5, 64, 192], dtype=tf.float32, stddev=1e-1), name='weights')
conv = tf.nn.conv2d(pool1, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[192], dtype=tf.float32), trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv2 = tf.nn.relu(bias, name=scope)
parameters += [kernel, biases]
print_activations(conv2)
# 稍微处理一下
lrn2 = tf.nn.lrn(conv2, 4, bias=1.0, alpha=0.001 / 9, beta=0.75, name='lrn2')
pool2 = tf.nn.max_pool(lrn2, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1], padding='VALID', name='pool2')
print_activations(pool2)
# 第三个
with tf.name_scope('conv3') as scope:
kernel = tf.Variable(tf.truncated_normal([3, 3, 192, 384], dtype=tf.float32, stddev=1e-1), name='weights')
conv = tf.nn.conv2d(pool2, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[384], dtype=tf.float32), trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv3 = tf.nn.relu(bias, name=scope)
parameters += [kernel, biases]
print_activations(conv3)
# 第四层
with tf.name_scope('conv4') as scope:
kernel = tf.Variable(tf.truncated_normal([3, 3, 384, 256], dtype=tf.float32, stddev=1e-1), name='weights')
conv = tf.nn.conv2d(conv3, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[256], dtype=tf.float32), trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv4 = tf.nn.relu(bias, name=scope)
parameters += [kernel, biases]
print_activations(conv4)
# 第五个
with tf.name_scope('conv5') as scope:
kernel = tf.Variable(tf.truncated_normal([3, 3, 256, 256], dtype=tf.float32, stddev=1e-1), name='weights')
conv = tf.nn.conv2d(conv4, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[256], dtype=tf.float32), trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv5 = tf.nn.relu(bias, name=scope)
parameters += [kernel, biases]
print_activations(conv5)
# 之后还有最大化池层
pool5 = tf.nn.max_pool(conv5, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1], padding='VALID', name='pool5')
print_activations(pool5)
return pool5, parameters
# 全连接层
# 评估每轮计算时间,第一个输入是tf得Session,第二个是运算算子,第三个是测试名称
# 头几轮有显存加载,cache命中等问题,可以考虑只计算第10次以后的
def time_tensorflow_run(session, target, info_string):
num_steps_burn_in = 10
total_duration = 0.0
total_duration_squared = 0.0
# 进行num_batches+num_steps_burn_in次迭代
# 用time.time()记录时间,热身过后,开始显示时间
for i in range(num_batches + num_steps_burn_in):
start_time = time.time()
_ = session.run(target)
duration = time.time() - start_time
if i >= num_steps_burn_in:
if not i % 10:
print('%s:step %d, duration = %.3f' % (datetime.now(), i - num_steps_burn_in, duration))
total_duration += duration
total_duration_squared += duration * duration
# 计算每轮迭代品均耗时和标准差sd
mn = total_duration / num_batches
vr = total_duration_squared / num_batches - mn * mn
sd = math.sqrt(vr)
print('%s: %s across %d steps, %.3f +/- %.3f sec / batch' % (datetime.now(), info_string, num_batches, mn, sd))
def run_benchmark():
# 首先定义默认的Graph
with tf.Graph().as_default():
# 并不实用ImageNet训练,知识随机计算耗时
image_size = 224
images = tf.Variable(tf.random_normal([batch_size, image_size, image_size, 3], dtype=tf.float32, stddev=1e-1))
pool5, parameters = inference(images)
init = tf.global_variables_initializer()
sess = tf.Session(config=tf.ConfigProto(allow_soft_placement=True, log_device_placement=False))
sess.run(init)
# 下面直接用pool5传入训练(没有全连接层)
# 只是做做样子,并不是真的计算
time_tensorflow_run(sess, pool5, "Forward")
# 瞎弄的,伪装
objective = tf.nn.l2_loss(pool5)
grad = tf.gradients(objective, parameters)
time_tensorflow_run(sess, grad, "Forward-backward")
run_benchmark()
如果使用TensorFlow-GPU的话这个默认是用GPU运行的
GPU运行结果:
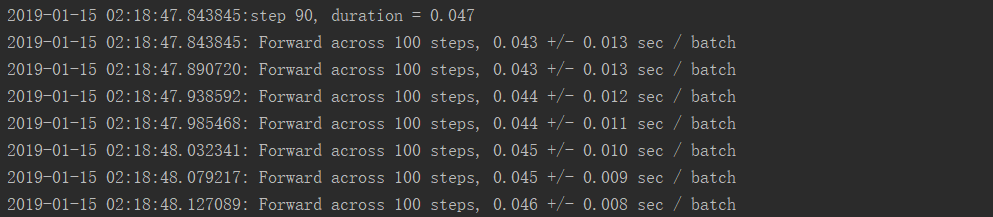
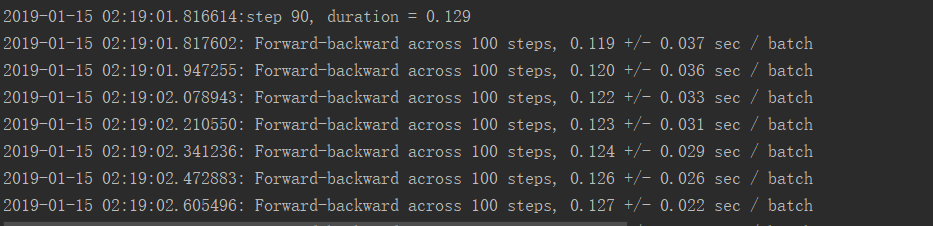
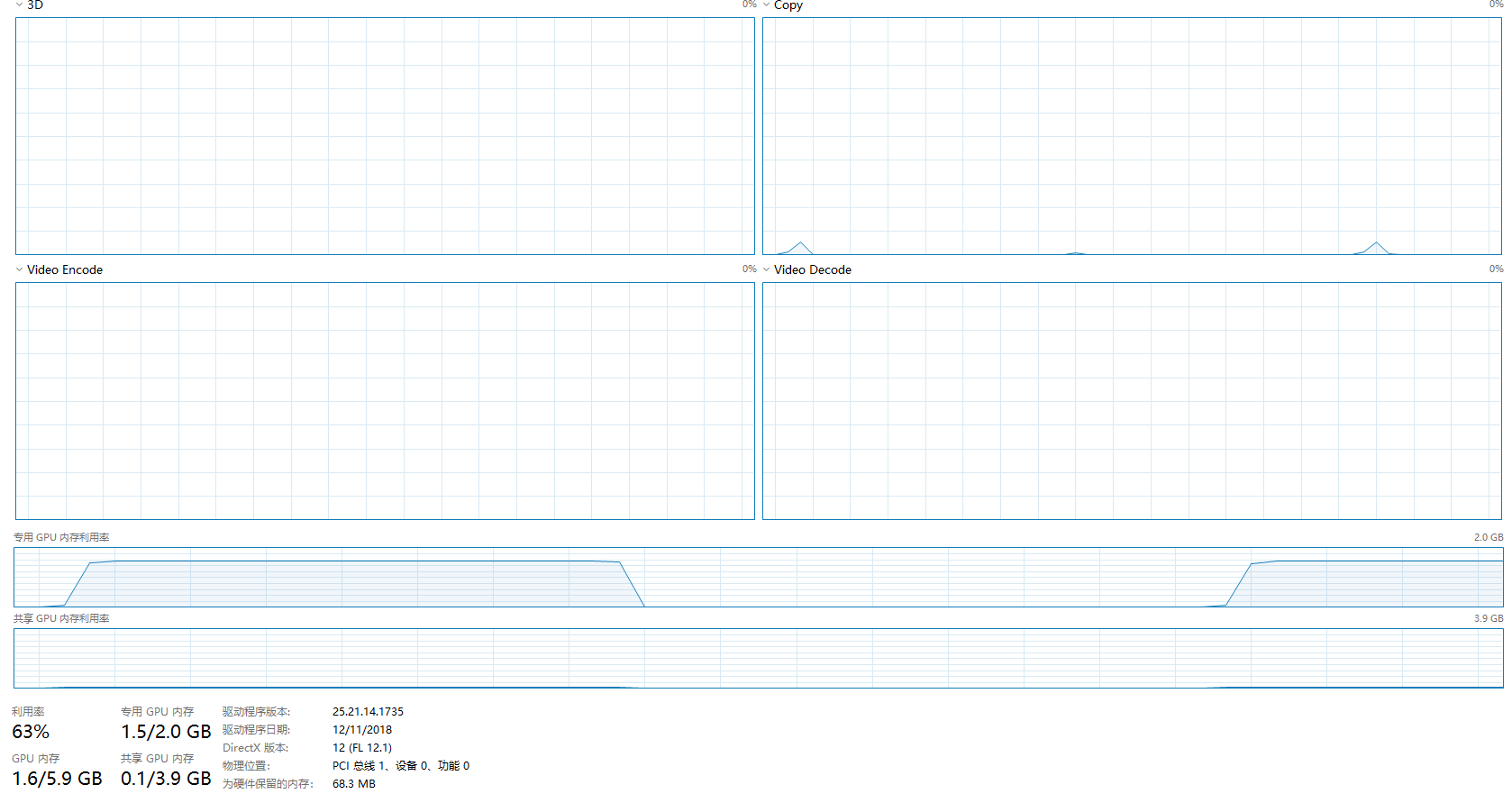
GPU使用率:
CPU使用率:
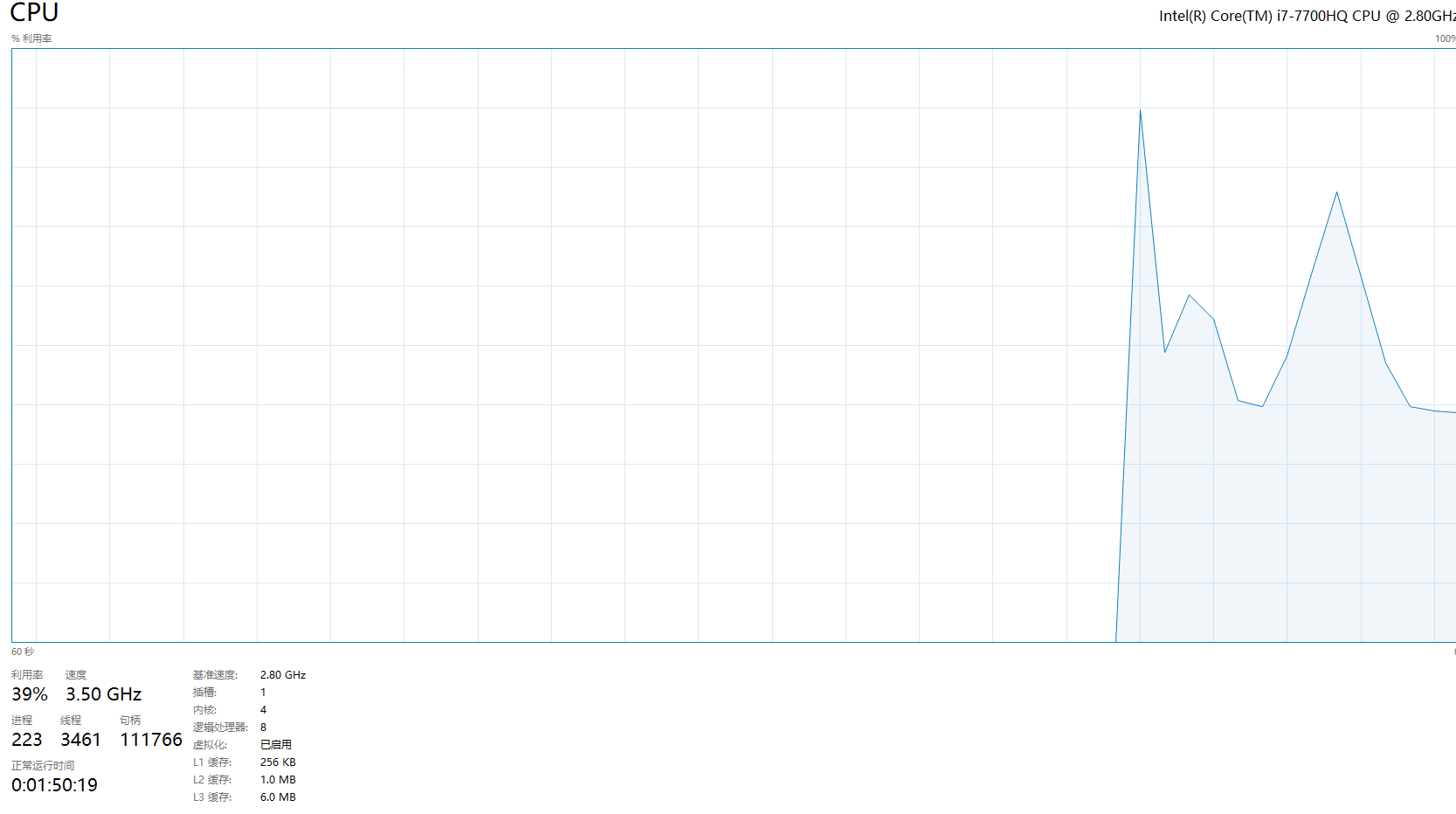
可以看出较为占用显存
将上面代码的6到7行注释解除即为CPU运行
CPU运行结果:
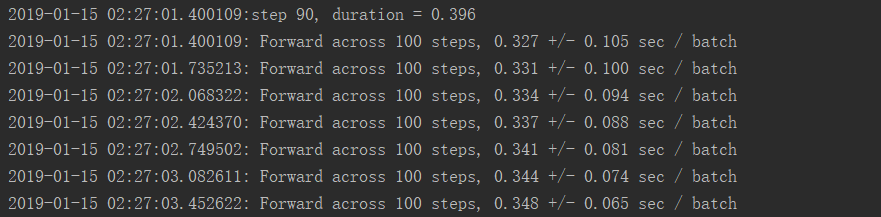
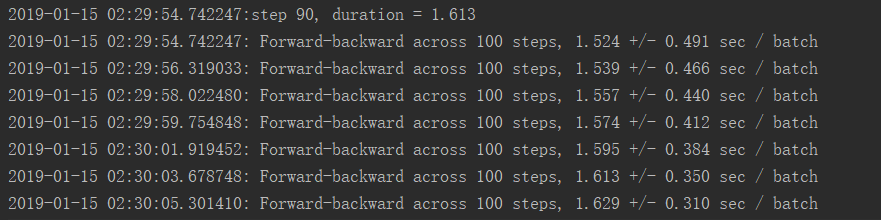
CPU利用率:

我2.8GHZ的CPU都跑到3.4GHZ了
这么对我的CPU真的好么
测试结果:
正向GPU运行时间效率是CPU运行效率的8.42倍
反向GPU运行时间效率是CPU运行效率的12.50倍
并且GPU运行模式下GPU占用率仅仅只有大约65%,CPU占用率仅仅只有45%左右
而CPU运行模式下CPU占用率长时间到达100%,且效率低下
看出GPU能够直接完爆CPU运行的
注意事项:
1.本次测试仅仅采用了卷积神经网络进行运行,不代表所有情况下GPU一定有优势;
2.鉴于CPU的瓶颈,可能CPU运行效率并不是非常理想,若采用更加高端的CPU运行效果可能会有大幅度提升;
3.仅代表作者个人观点,希望各位大佬能够评论或打赏哦。
2019-01-15 02:41:24 Author:Lance Yu
TensorFlow GPU版本的安装与调试的更多相关文章
- 【转】Ubuntu 16.04安装配置TensorFlow GPU版本
之前摸爬滚打总是各种坑,今天参考这篇文章终于解决了,甚是鸡冻\(≧▽≦)/,电脑不知道怎么的,安装不了16.04,就安装15.10再升级到16.04 requirements: Ubuntu 16.0 ...
- 查看TensorFlow的版本以及安装路径
查看TensorFlow的版本以及安装路径 进入到Python环境 import tensorflow as tf tf.__version__ # 查看版本 tf.__path__ # 查看安装路径 ...
- tensorflow 一些好的blog链接和tensorflow gpu版本安装
pading :SAME,VALID 区别 http://blog.csdn.net/mao_xiao_feng/article/details/53444333 tensorflow实现的各种算法 ...
- win10系统下安装TensorFlow GPU版本
首先要说,官网上的指南是最好的指南. https://www.tensorflow.org/install/install_windows 需要FQ看. 想要安装gpu版本的TensorFlow.我们 ...
- 通过Anaconda在Ubuntu16.04上安装 TensorFlow(GPU版本)
一. 安装环境 Ubuntu16.04.3 LST GPU: GeForce GTX1070 Python: 3.5 CUDA Toolkit 8.0 GA1 (Sept 2016) cuDNN v6 ...
- Win10上安装Keras 和 TensorFlow(GPU版本)
一. 安装环境 Windows 10 64bit 家庭版 GPU: GeForce GTX1070 Python: 3.5 CUDA: CUDA Toolkit 8.0 GA1 (Sept 2016 ...
- 说说Windows7 64bits下安装TensorFlow GPU版本会遇到的一些坑
不多说,直接上干货! 再写博文,回顾在Windows7上安装TensorFlow-GPU的一路坑 Windows7上安装TensorFlow的GPU版本后记 欢迎大家,加入我的微信公众号:大数据躺过的 ...
- Windows7 64bits下安装TensorFlow GPU版本(图文详解)
不多说,直接上干货! Installing TensorFlow on Windows的官网 https://www.tensorflow.org/install/install_windows 首先 ...
- MySQL5.7.22版本的安装和调试
1:安装前的准备工作 需要的软件: boost_1_59_0.tar.gz,cmake-3.6.1.tar.gz,mysql-5.7.22.tar.gz 开始安装MySQL 2.1 检查cmake [ ...
随机推荐
- 7. Go语言—时间模块
一.时间模块 1. 统计程序执行时间 package main import ( "time" "fmt" ) func test() { time.Sleep ...
- day80_10_29git冲突解决与短信服务redis
一.开发中的操作. 在项目开发中,在工作区进行开发,开发结束后提交到本地版本库. 再拉取远程仓库,具体如下: """ 1.开发前,拉一次远程仓库 2.工作区进行开发 3. ...
- Springboot项目启动不了。也不打印任何日志信息。
Springboot项目启动不了.也不打印任何日志信息. <!-- 在创建Spring Boot工程时,我们引入了spring-boot-starter,其中包含了spring-boot-sta ...
- CentOS7 通过 devstack 安装 OpenStack
安装前的准备 修改源 (可跳过) 将下载源变更到国内可以时下载速度大大提升 打开下面的文件 vim /etc/yum.repos.d/CentOS-Base.repo 将原来的注释掉改成: [base ...
- AtCoder Grand Contest 036
Preface 这篇已经鸽了好久的说,AGC037都打完了才回来补所以题目可能都记不大清楚了,如有错误请指正 这场感觉难度远高于上一场,从D开始就不会了,E没写(看了题解都不会写),F就是抄曲明姐姐的 ...
- docker 部署 HFish(集群部署)
主节点部署: docker run -d --name hfish-master -p : -p : -p : -p : -p : -p : -p : -p : -p : -p : -p : -p : ...
- 使用mybatis动态where字句方法
上篇文章介绍了如何使用mybatis-generator生成实体类.Mapper接口代码,其中生成的Mapper接口代码是不带ByExample方法的.本篇文章将介绍如何使用mybatis-gener ...
- 连接树莓派中的MySQL服务器
今天用笔记本连接树莓派的 MySQL ,结果连接不上.就直接连接到树莓派上进行操作.其实以前也知道远程访问 MySQL 需要进行配置,可以直接 mysql.user 表,也可以直接使用授权的 SQL ...
- 一位IT民工的十年风雨历程
距离2020年只有30天了,转眼毕业快10年. 回首自己,已三十有三,中年危机. 古人云三十而立,我却还在测试途中摸爬滚打. 创业,自由职业永远是一个梦,白日梦. 焦虑.迷茫.看不到希望. 这两天一场 ...
- CSS改变浏览器默认滚动条样式
前言 最近总是看到某网站滚动条不是浏览器默认样式,而是自定义样式 比如我博客的滚动条,自定义滚动条样式和hover前后的效果 顿时来了兴致和有一个疑问,这是怎么实现的呢? 解决 注:经测试,目 ...