聚类--K均值算法:自主实现与sklearn.cluster.KMeans调用
1.用python实现K均值算法
import numpy as np
x = np.random.randint(1,100,20)#产生的20个一到一百的随机整数
y = np.zeros(20)
k = 3
print(x)
print(y) def initcenter(x,k):#初始化聚类中心数组
return x[0:k].reshape(k)
kc = initcenter(x,k)
print(kc) def nearest(kc, i):#定义函数求出kc与i之差最小的数的坐标
d = (abs(kc - i))
w = np.where(d == np.min(d))
return w[0][0] # print(nearest(kc,66)) # for i in range(x.shape[0]):
# y[i] = nearest(kc,x[i])
# print(y) def xclassify(x, y, kc):#按距离最近的准则将它们分到距离它们最近的聚类中心(最相似)所对应的类
for i in range(x.shape[0]):
y[i] = nearest(kc,x[i])
return y y = xclassify(x,y,kc)
print(x)
print(y)
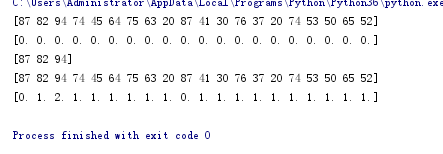
#.用sklearn.cluster.KMeans,鸢尾花完整数据做聚类并用散点图显示.
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import load_iris
iris=load_iris()
print(iris)
X=iris.data
print(X)
from sklearn.cluster import KMeans
est = KMeans(n_clusters=3)
est.fit(X)
kc = est.cluster_centers_
y_kmeans = est.predict(X) #预测每个样本的聚类索引
print(y_kmeans,kc)
print(kc.shape,y_kmeans.shape)
plt.scatter(X[:,0],X[:,1],c=y_kmeans,s=50,cmap='rainbow')
plt.show()
# 鸢尾花完整数据做聚类并用散点图显示.
from sklearn.cluster import KMeans
import numpy as np
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
data = load_iris()
iris = data.data
petal_len = iris
print(petal_len)
k_means = KMeans(n_clusters=3) #三个聚类中心
result = k_means.fit(petal_len) #Kmeans自动分类
kc = result.cluster_centers_ #自动分类后的聚类中心
y_means = k_means.predict(petal_len) #预测Y值
plt.scatter(petal_len[:,0],petal_len[:,2],c=y_means, marker='p',cmap='rainbow')
plt.show()
聚类--K均值算法:自主实现与sklearn.cluster.KMeans调用的更多相关文章
- 第八次作业:聚类--K均值算法:自主实现与sklearn.cluster.KMeans调用
import numpy as np x = np.random.randint(1,100,[20,1]) y = np.zeros(20) k = 3 def initcenter(x,k): r ...
- 聚类--K均值算法
import numpy as np from sklearn.datasets import load_iris iris = load_iris() x = iris.data[:,1] y = ...
- K 均值算法-如何让数据自动分组
公号:码农充电站pro 主页:https://codeshellme.github.io 之前介绍到的一些机器学习算法都是监督学习算法.所谓监督学习,就是既有特征数据,又有目标数据. 而本篇文章要介绍 ...
- 机器学习之K均值算法(K-means)聚类
K均值算法(K-means)聚类 [关键词]K个种子,均值 一.K-means算法原理 聚类的概念:一种无监督的学习,事先不知道类别,自动将相似的对象归到同一个簇中. K-Means算法是一种聚类分析 ...
- 聚类算法:K-means 算法(k均值算法)
k-means算法: 第一步:选$K$个初始聚类中心,$z_1(1),z_2(1),\cdots,z_k(1)$,其中括号内的序号为寻找聚类中心的迭代运算的次序号. 聚类中心的向量值可任意设 ...
- 3.K均值算法
一.概念 K-means中心思想:事先确定常数K,常数K意味着最终的聚类类别数,首先随机选定初始点为质心,并通过计算每一个样本与质心之间的相似度(这里为欧式距离),将样本点归到最相似的类中,接着,重新 ...
- 一句话总结K均值算法
一句话总结K均值算法 核心:把样本分配到离它最近的类中心所属的类,类中心由属于这个类的所有样本确定. k均值算法是一种无监督的聚类算法.算法将每个样本分配到离它最近的那个类中心所代表的类,而类中心的确 ...
- 【机器学习】K均值算法(I)
K均值算法是一类非监督学习类,其可以通过观察样本的离散性来对样本进行分类. 例如,在对如下图所示的样本中进行聚类,则执行如下步骤 1:随机选取3个点作为聚类中心. 2:簇分配:遍历所有样本然后依据每个 ...
- Bisecting KMeans (二分K均值)算法讲解及实现
算法原理 由于传统的KMeans算法的聚类结果易受到初始聚类中心点选择的影响,因此在传统的KMeans算法的基础上进行算法改进,对初始中心点选取比较严格,各中心点的距离较远,这就避免了初始聚类中心会选 ...
随机推荐
- Servlet(2)
HttpServlet 简介: Servlet 就是一个普通的java类,是运行在web容器上(tomcat)上的一个java类 用来通过Servlet中的代码,接受Http中浏览器的请求信息,以及对 ...
- C++11-->单生产者,单消费者问题
参考上一篇C++11并发编程 #include <iostream> #include <queue> #include <assert.h> #include & ...
- xslt 2.0 分组
把数据拆成200个一组 <?xml version="1.0" encoding="UTF-8"?> <xsl:stylesheet vers ...
- LoadLibrary 失败的解决
工作中遇到调用Loadlibrary 偶发失败的问题,不是必现,而且这种错误只是在程序初始化的时候出现,初始化成功后当然不会调用,而初始化也不是经常做的动作,所以查找原因起来比较麻烦,调试过程中发现有 ...
- centos下使用yum 安装pip
本文为转载:原文出处:https://www.cnblogs.com/saolv/p/6963314.html centos下安装pip时失败: [root@wfm ~]# yum -y instal ...
- 构建--> 部署-->
这一篇中我们会写一些关于自动化部署的代码.我们会使用 Powershell 书写这类代码. 你将发现这篇文章中涉及的东西非常具体,有的要求甚至相当苛刻且可能不具有通用性.这是因为部署从来都是跟环境打交 ...
- SpringMVC云题库错题及答案汇总-2
此题目考察的是SpringMVC-注解驱动控制器,注释类型的范围: A.处理requet uri 部分的注解: @PathVariable; B.处理request header部分的注解: @Req ...
- php 跨域请求
执行要在跨域请求的服务器端对应的代码上增加下面的代码 <?php namespace Admin\Controller; // 指定允许跨域访问 header('Access-Control-A ...
- SharePoint Framework 基于团队的开发(四)
博客地址:http://blog.csdn.net/FoxDave 确保代码一致性和质量 软件开发团队常常同项目的一致性和高质量做斗争.不同的开发者有不同的编码风格和偏好.在每个团队都有技术优秀的独立 ...
- GitHub入门与实践 读书笔记三:(1)GitHub账户注册教程
第一步:进入GitHub官网,官网地址:https://github.com/ 第二步:点击Sign up for GitHub 1.昵称一栏:每次在你输入昵称之后,都会检查是否已经被注册.如果被注册 ...