使用Spark进行搜狗日志分析实例——统计每个小时的搜索量
package sogolog import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext} /**
* 统计每小时搜索次数
*/
/*
搜狗日志示例
访问时间(时:分:秒) 用户ID [查询词] 该URL在返回结果中的排名 用户点击的顺序号 用户点击的URL
00:00:00 2982199073774412 [360安全卫士] 8 3 download.it.com.cn/softweb/software/firewall/antivirus/20067/17938.html
00:00:00 07594220010824798 [哄抢救灾物资] 1 1 news.21cn.com/social/daqian/2008/05/29/4777194_1.shtml
00:00:00 5228056822071097 [75810部队] 14 5 www.greatoo.com/greatoo_cn/list.asp?link_id=276&title=%BE%DE%C2%D6%D0%C2%CE%C5
00:00:00 6140463203615646 [绳艺] 62 36 www.jd-cd.com/jd_opus/xx/200607/706.html
*/
object CountByHours {
def main(args: Array[String]): Unit = { //1、启动spark上下文、读取文件
val conf = new SparkConf().setAppName("sougo count by hours").setMaster("local")
val sc = new SparkContext(conf)
var orgRdd = sc.textFile("C:\\Users\\KING\\Desktop\\SogouQ.reduced\\SogouQ.reduced")
println("总行数:"+orgRdd.count()) //2、map操作,遍历处理每一行数据
var map:RDD[(String,Integer)] = orgRdd.map(line=>{
//拿到小时
var h:String = line.substring(0,2)
(h,1)
}) //3、reduce操作,将上面的 map结果按KEY进行合并、叠加
var reduce:RDD[(String,Integer)] = map.reduceByKey((x,y)=>{
x+y
}) //打印出按小时排序后的统计结果
reduce.sortByKey().collect().map(println)
}
}
运行结果:
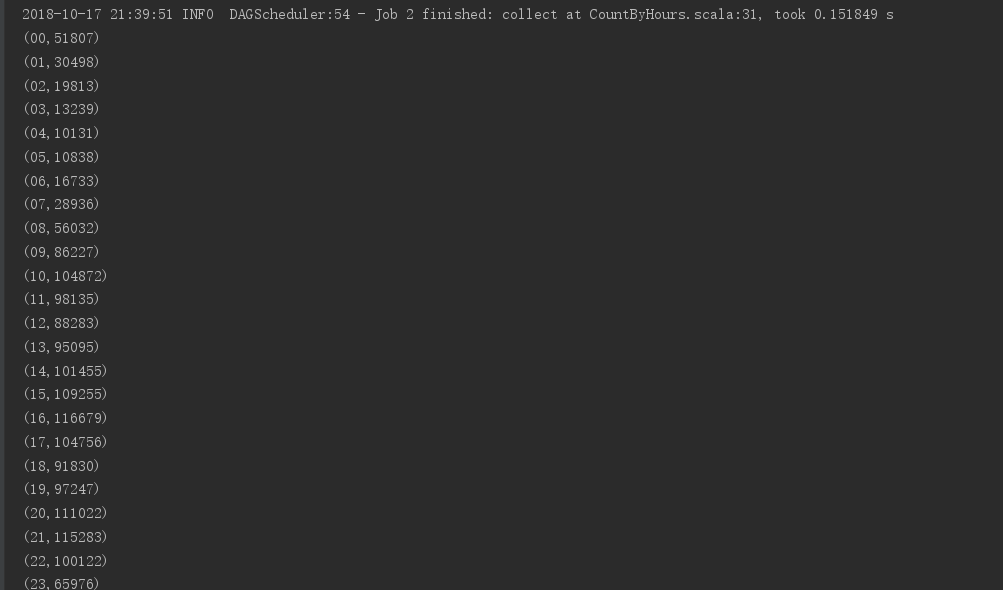
搜狗日志下载地址:http://www.sogou.com/labs/resource/q.php
使用Spark进行搜狗日志分析实例——统计每个小时的搜索量的更多相关文章
- 使用Spark进行搜狗日志分析实例——map join的使用
map join相对reduce join来说,可以减少在shuff阶段的网络传输,从而提高效率,所以大表与小表关联时,尽量将小表数据先用广播变量导入内存,后面各个executor都可以直接使用 pa ...
- 使用Spark进行搜狗日志分析实例——列出搜索不同关键词超过10个的用户及其搜索的关键词
package sogolog import org.apache.hadoop.io.{LongWritable, Text} import org.apache.hadoop.mapred.Tex ...
- ELK 日志分析实例
ELK 日志分析实例一.ELK-web日志分析二.ELK-MySQL 慢查询日志分析三.ELK-SSH登陆日志分析四.ELK-vsftpd 日志分析 一.ELK-web日志分析 通过logstash ...
- 基于Spark的网站日志分析
本文只展示核心代码,完整代码见文末链接. Web Log Analysis 提取需要的log信息,包括time, traffic, ip, web address 进一步解析第一步获得的log信息,如 ...
- Spark之搜狗日志查询实战
1.下载搜狗日志文件: 地址:http://www.sogou.com/labs/resource/chkreg.php 2.利用WinSCP等工具将文件上传至集群. 3.创建文件夹,存放数据: mk ...
- 日志分析-mime统计
提取日志中未落入标准字段的mime,分adx,adtype 统计mime的数量和包含js的数量占比 require 'date' require 'net/http' require 'uri' re ...
- spark提交异常日志分析
java.lang.NoSuchMethodError: org.apache.spark.sql.SQLContext.sql(Ljava/lang/String;)Lorg/apache/spar ...
- nginx日志分析及其统计PV、UV、IP
一.nginx日志结构 nginx中access.log 的日志结构: $remote_addr 客户端地址 211.28.65.253 $remote_user 客户端用户名称 -- $time_l ...
- 日志分析_统计每日各时段的的PV,UV
第一步: 需求分析 需要哪些字段(时间:每一天,各个时段,id,url,guid,tracTime) 需要分区为天/时 PV(统计记录数) UV(guid去重) 第二步: 实施步骤 建Hive表,表列 ...
随机推荐
- No Directionality widget found.错误记录。
import 'package:flutter/material.dart'; void main() => runApp(new Center(child: new Text('Hello, ...
- [ZOJ 4014] Pretty Matrix
题目链接:http://acm.zju.edu.cn/onlinejudge/showProblem.do?problemId=5742 AC代码: /* * 反思: * 1.遇到简单题别激动,先把它 ...
- SQL Server監控与診斷
僅為記錄工作中遇到的問題. 1. 字符串截斷: SQL server里很多job用於運行DTS,經常會收到系統出錯警報,如: ...String ) The statement has been te ...
- Request method 'PUT'/ 'POST' not supported
起因 在项目中遇到需要进行crud操作的功能,用的是Springboot+MybatisPlus+MySQL+AVue,在通过postman测试接口正确性时遇到此错误. 排查过程 因为项目运行是没问题 ...
- java.util.concurrent.ExecutionException: com.android.builder.internal.aapt.v2.Aapt2Exception: AAPT2 error: check logs for details
Caused by: java.util.concurrent.ExecutionException: com.android.builder.internal.aapt.v2.Aapt2Except ...
- selenium 模拟拖动滚动条下拉
senium做自动化测试的过程中,有的页面需要下拉滚动条才能全部加载完成,否则加载不出来就定位不到想要的元素. 参考链接:http://www.cnblogs.com/landhu/p/5761794 ...
- Kotlin 随笔小计
最近准备学Kotlin 现在Kotlin也能支持IOS开发了,准备后面买个Mac也能进行IOS开发 当然目标还是看着能不能把一些小的Android项目重构下 也算是定个目标吧,由于沉迷吃鸡,日志都没怎 ...
- office-excel
Excel打印每张纸都带表头 页面布局--->打印标题--->顶端标题行
- springboot返回页面
1.使用@Controller注解: @Controller必须配合模板 先导入依赖: <dependency> <groupId>org.springframework.bo ...
- VNC (vnc viewer)错误修复方法
VNC错误描述 vnc viewer开启后弹窗提示 Could not connect to session bus: Failed to connect to socket /tmp/dbus-XX ...