使用Spark进行搜狗日志分析实例——map join的使用
map join相对reduce join来说,可以减少在shuff阶段的网络传输,从而提高效率,所以大表与小表关联时,尽量将小表数据先用广播变量导入内存,后面各个executor都可以直接使用
package sogolog
import org.apache.hadoop.io.{LongWritable, Text}
import org.apache.hadoop.mapred.TextInputFormat
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
class RddFile {
def readFileToRdd(path: String): RDD[String] = {
val conf = new SparkConf().setMaster("local").setAppName("sougoDemo")
val sc = new SparkContext(conf);
//使用这种方法能够避免中文乱码
readFileToRdd(path,sc)
}
def readFileToRdd(path: String,sc :SparkContext): RDD[String] = {
//使用这种方法能够避免中文乱码
sc.hadoopFile(path,classOf[TextInputFormat], classOf[LongWritable], classOf[Text]).map{
pair => new String(pair._2.getBytes, 0, pair._2.getLength, "GBK")}
}
}
package sogolog
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
import scala.collection.mutable.ArrayBuffer
object MapSideJoin {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("sougoDemo")
val sc = new SparkContext(conf);
val userRdd = new RddFile().readFileToRdd("J:\\scala\\workspace\\first-spark-demo\\sougofile\\user",sc)
//解析用户信息
val userMapRDD:RDD[(String,String)] = userRdd.map(line=>(line.split("\t")(0),line.split("\t")(1)))
//将用户信息设置为广播变量,方便各个任务引用
val userMapBroadCast =sc.broadcast(userMapRDD.collectAsMap())
val searchLogRdd = new RddFile().readFileToRdd("J:\\scala\\workspace\\first-spark-demo\\sougofile\\SogouQ.reduced",sc)
val joinResult = searchLogRdd.mapPartitionsWithIndex((index,f)=>{
val userMap = userMapBroadCast.value
var result = ArrayBuffer[String]()
var count = 0
//搜索日志表join用户表
//原来日志列为:时间 用户ID 关键词 排名 URL
//新的日志列为:时间 用户ID 用户名 关键词 排名 URL
f.foreach( log=>{
count=count+1;
val lineArrs = log.split("\t")
val uid = lineArrs(1)
val newLine:StringBuilder = new StringBuilder()
if(userMap.contains(uid)){
newLine.append(lineArrs(0)).append("\t")
newLine.append(lineArrs(1)).append("\t")
newLine.append(userMap.get(uid).get).append("\t") //从广播变量中根据用户ID获取用户名
for (i<- 2 to lineArrs.length-1){
newLine.append(lineArrs(i)).append("\t")
}
result .+= (newLine.toString())
}
})
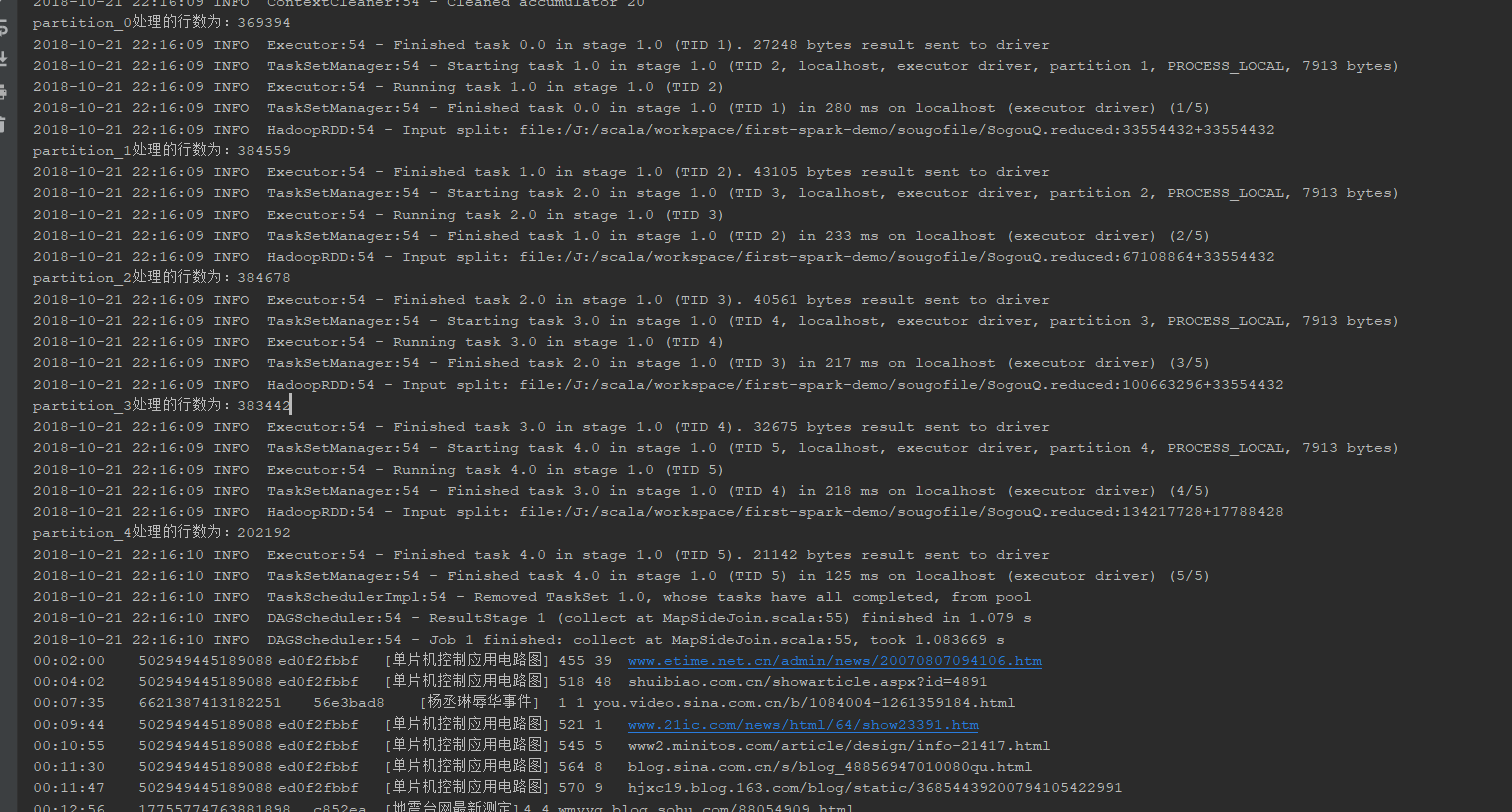
println("partition_"+index+"处理的行数为:"+count)
result.iterator
})
//打印结果
joinResult.collect().foreach(println)
}
}
结果展示:
使用Spark进行搜狗日志分析实例——map join的使用的更多相关文章
- 使用Spark进行搜狗日志分析实例——统计每个小时的搜索量
package sogolog import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} /* ...
- 使用Spark进行搜狗日志分析实例——列出搜索不同关键词超过10个的用户及其搜索的关键词
package sogolog import org.apache.hadoop.io.{LongWritable, Text} import org.apache.hadoop.mapred.Tex ...
- ELK 日志分析实例
ELK 日志分析实例一.ELK-web日志分析二.ELK-MySQL 慢查询日志分析三.ELK-SSH登陆日志分析四.ELK-vsftpd 日志分析 一.ELK-web日志分析 通过logstash ...
- Spark之搜狗日志查询实战
1.下载搜狗日志文件: 地址:http://www.sogou.com/labs/resource/chkreg.php 2.利用WinSCP等工具将文件上传至集群. 3.创建文件夹,存放数据: mk ...
- 基于Spark的网站日志分析
本文只展示核心代码,完整代码见文末链接. Web Log Analysis 提取需要的log信息,包括time, traffic, ip, web address 进一步解析第一步获得的log信息,如 ...
- spark提交异常日志分析
java.lang.NoSuchMethodError: org.apache.spark.sql.SQLContext.sql(Ljava/lang/String;)Lorg/apache/spar ...
- Spark RDD/Core 编程 API入门系列之动手实战和调试Spark文件操作、动手实战操作搜狗日志文件、搜狗日志文件深入实战(二)
1.动手实战和调试Spark文件操作 这里,我以指定executor-memory参数的方式,启动spark-shell. 启动hadoop集群 spark@SparkSingleNode:/usr/ ...
- 024 关于spark中日志分析案例
1.四个需求 需求一:求contentsize的平均值.最小值.最大值 需求二:请各个不同返回值的出现的数据 ===> wordCount程序 需求三:获取访问次数超过N次的IP地址 需求四:获 ...
- Spark SQL慕课网日志分析(1)--系列软件(单机)安装配置使用
来源: 慕课网 Spark SQL慕课网日志分析_大数据实战 目标: spark系列软件的伪分布式的安装.配置.编译 spark的使用 系统: mac 10.13.3 /ubuntu 16.06,两个 ...
随机推荐
- Lintcode93-Balanced Binary Tree-Easy
93. Balanced Binary Tree Given a binary tree, determine if it is height-balanced. For this problem, ...
- 举例理解JDK动态代理
JDK动态代理 说到java自带的动态代理api,肯定离不开反射.JDK的Proxy类实现动态代理最核心的方法: public static Object newProxyInstance(Class ...
- 4.3 thymeleaf模板引擎的使用
参考说明:以下笔记参考来自尚硅谷springboot教学中的笔记! thymeleaf官网docs: https://www.thymeleaf.org/documentation.html 模板引擎 ...
- 技巧 筛1~n的所有因子
从 i : 1~n, 是i的倍数, 则计入该数 复杂度 n*(1/1+1/2+1/3+...1/n)=nlogn ll d[N]; // 计每个数的因子数 set<ll> s[N]; // ...
- HDU 5115 (杀狼,区间DP)
题意:你是一个战士现在面对,一群狼,每只狼都有一定的主动攻击力和附带攻击力.你杀死一只狼.你会受到这只狼的(主动攻击力+旁边两只狼的附带攻击力)这么多伤害~现在问你如何选择杀狼的顺序使的杀完所有狼时, ...
- 【转】LVDS基础、原理、图文讲解
转自:https://blog.csdn.net/wangdapao12138/article/details/79935821 LVDS是一种低摆幅的差分信号技术,它使得信号能在差分PCB 线对或平 ...
- docker使用笔记
项目部署时用到了docker,以下分享了我在实践中使用的指令,和对docker一些个人的理解(※和字体加重部分) 本文选择使用网易的镜像源:https://c.163.com/hub#/m/home/ ...
- Myeclipse6.5每次打开properties中文注释都会变成乱码
发现无论怎么写properties注释,只要重新打开me就会出现乱码.默认properties是不支持中文的.所以最好用英文写properties文档.也可以写好直接翻译.已经写好的乱码直接拖到Chr ...
- Python 考试练习
1.算法复杂度分为:时间复杂度和空间复杂度 一个算法的优劣主要从算法的执行时间和所需要占用的存储空间两个方面衡量. 时间复杂度:是指执行算法所需要的计算工作量,也即算法的执行时间 (注意:是算法的执 ...
- python 读取文件read.csv报错 OSError: Initializing from file failed
小编在用python 读取文件read.csv的时候 报了一个错误 OSError: Initializing from file failed 初始化 文件失败 检查了文件路径,没问题 那应该是我文 ...