使用Spark进行搜狗日志分析实例——列出搜索不同关键词超过10个的用户及其搜索的关键词
package sogolog
import org.apache.hadoop.io.{LongWritable, Text}
import org.apache.hadoop.mapred.TextInputFormat
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
class RddFile {
def readFileToRdd(path: String): RDD[String] = {
val conf = new SparkConf().setMaster("local").setAppName("sougoDemo")
val sc = new SparkContext(conf);
//使用这种方法能够避免中文乱码
sc.hadoopFile("J:\\scala\\workspace\\first-spark-demo\\sougofile\\SogouQ.reduced",classOf[TextInputFormat], classOf[LongWritable], classOf[Text]).map{
pair => new String(pair._2.getBytes, 0, pair._2.getLength, "GBK")}
}
}
package sogolog import org.apache.spark.rdd.RDD /**
* 列出搜索不同关键词超过3个的用户及其搜索的关键词
*/
object userSearchKeyWordLT3 {
def main(args: Array[String]): Unit = {
//1、读入文件
val textFile = new RddFile().readFileToRdd("J:\\scala\\workspace\\first-spark-demo\\sougofile\\SogouQ.reduced") //2、map操作,将每行的用户、关键词读入新的RDD中
val userKeyWordTuple:RDD[(String,String)] = textFile.map(line=>{
val arr = line.split("\t")
(arr(1),arr(2))
}) //3、reduce操作,将相同用户的关键词进行合并
val userKeyWordReduced = userKeyWordTuple.reduceByKey((x,y)=>{
//去重
if(x.contains(y)){
x
}else{
x+","+y
}
}) //4、使用filter进行最终过滤
val finalResult = userKeyWordReduced.filter(x=>{
//过滤小于10个关键词的用户
x._2.split(",").length>=10
}) //5、打印出结果
finalResult.collect().foreach(println)
}
}
运行结果:
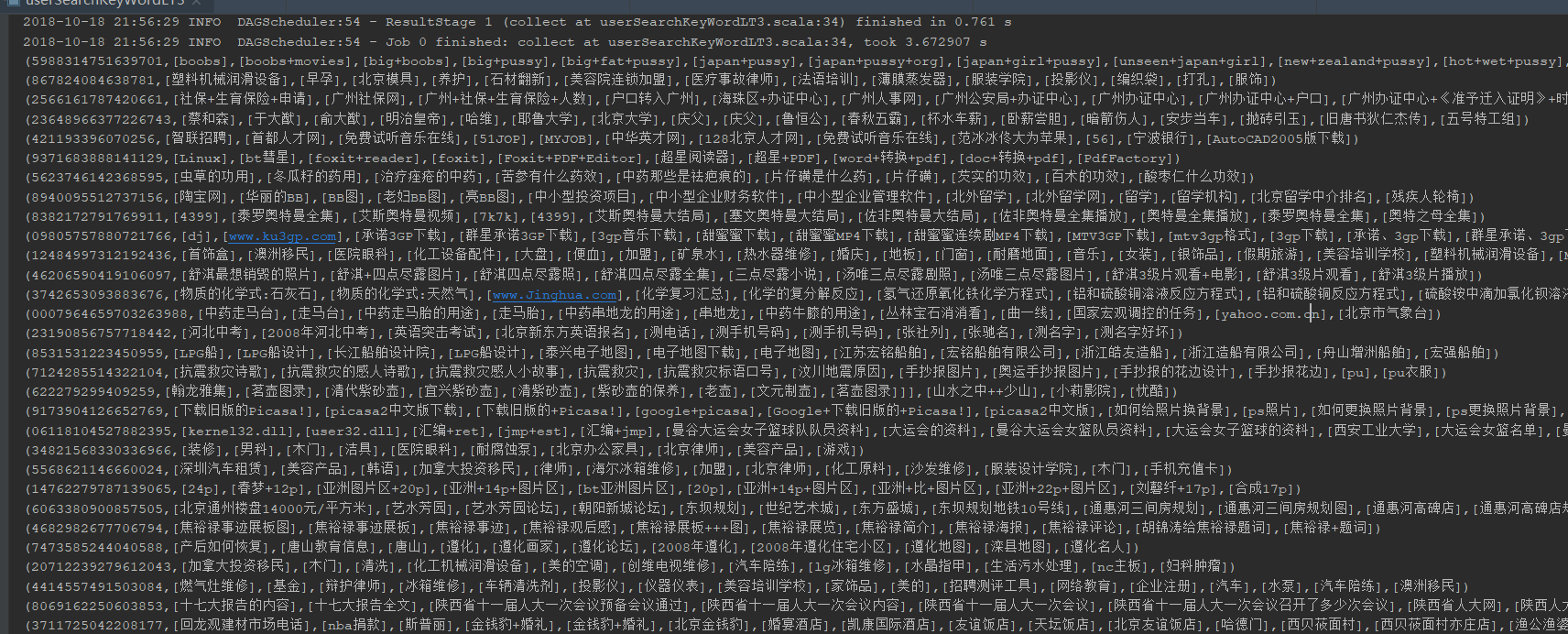
使用Spark进行搜狗日志分析实例——列出搜索不同关键词超过10个的用户及其搜索的关键词的更多相关文章
- 使用Spark进行搜狗日志分析实例——统计每个小时的搜索量
package sogolog import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} /* ...
- 使用Spark进行搜狗日志分析实例——map join的使用
map join相对reduce join来说,可以减少在shuff阶段的网络传输,从而提高效率,所以大表与小表关联时,尽量将小表数据先用广播变量导入内存,后面各个executor都可以直接使用 pa ...
- ELK 日志分析实例
ELK 日志分析实例一.ELK-web日志分析二.ELK-MySQL 慢查询日志分析三.ELK-SSH登陆日志分析四.ELK-vsftpd 日志分析 一.ELK-web日志分析 通过logstash ...
- Spark之搜狗日志查询实战
1.下载搜狗日志文件: 地址:http://www.sogou.com/labs/resource/chkreg.php 2.利用WinSCP等工具将文件上传至集群. 3.创建文件夹,存放数据: mk ...
- 基于Spark的网站日志分析
本文只展示核心代码,完整代码见文末链接. Web Log Analysis 提取需要的log信息,包括time, traffic, ip, web address 进一步解析第一步获得的log信息,如 ...
- spark提交异常日志分析
java.lang.NoSuchMethodError: org.apache.spark.sql.SQLContext.sql(Ljava/lang/String;)Lorg/apache/spar ...
- (转载)shell日志分析常用命令
shell日志分析常用命令总结 时间:2016-03-09 15:55:29来源:网络 导读:shell日志分析的常用命令,用于日志分析的shell脚本,统计日志中百度蜘蛛的抓取量.抓取最多的页面.抓 ...
- Spark RDD/Core 编程 API入门系列之动手实战和调试Spark文件操作、动手实战操作搜狗日志文件、搜狗日志文件深入实战(二)
1.动手实战和调试Spark文件操作 这里,我以指定executor-memory参数的方式,启动spark-shell. 启动hadoop集群 spark@SparkSingleNode:/usr/ ...
- [spark案例学习] WEB日志分析
数据准备 数据下载:美国宇航局肯尼迪航天中心WEB日志 我们先来看看数据:首先将日志加载到RDD,并显示出前20行(默认). import sys import os log_file_path =' ...
随机推荐
- EvansClassification
EvansClassification In his excellent book Domain Driven Design, Eric Evans creates a classification ...
- 论文笔记:Deeper and Wider Siamese Networks for Real-Time Visual Tracking
Deeper and Wider Siamese Networks for Real-Time Visual TrackingUpdated on 2019-04-01 16:10:37 Paper ...
- 优雅的使用Linux
优雅的使用Linux 系统安装 启动盘制作 通过rufus烧制官网镜像,注意根据自己系统的引导模式选择相应模式,不确定的,可以在windows中通过Win + R 快捷键调出"运行" ...
- 基于卷积神经网络CNN的电影推荐系统
本项目使用文本卷积神经网络,并使用MovieLens数据集完成电影推荐的任务. 推荐系统在日常的网络应用中无处不在,比如网上购物.网上买书.新闻app.社交网络.音乐网站.电影网站等等等等,有人的地方 ...
- linux新手记录;可执行文件直接运行
下载meshlab $sudo apt-get install meshlab 查看meshlab位置 $ whereis meshlab\meshlab: /usr/bin/meshlab /usr ...
- 如何查找redis使用的是哪个配置文件
ps -ef|grep redis 得到了进程号 xxxx 然后 ls -l /proc/xxxx/cwd ps:可以推广到其他进程,只要有pid,就能找到配置文件
- Kafka知识总结
1.kafka是什么 类JMS消息队列,结合JMS中的两种模式,可以有多个消费者主动拉取数据,在JMS中只有点对点模式才有消费者主动拉取数据. kafka是一个生产-消费模型. Producer:生产 ...
- 雷林鹏分享:Composer 安装
下午在安装 Laravel 框架过程中,遇到了不少问题,因为 Laravel 的安装依赖于 composer,这里就先介绍一下 composer 的安装方法: 安装方法: #下载 sudo curl ...
- 小程序tab切换 点击左右滑动
wxml <scroll-view scroll-x="true" class="navbar-box"> <block wx:for=&qu ...
- 缓存之Memcache
Memcache Memcached 是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载.它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高动态.数据库驱动网站的速度. ...