Spark&Hive结合起来
1.spark与Hive结合起来
前提:当你spark的版本是1.6.1的时候,你的Hive版本要1.2.1,用别的版本会有问题
我们在做的时候,Hive的版本很简单,我们只需要解压缩,告诉他Hive的源数据在哪里即可
1.首先我们进入/conf/hive-site.xml文件,进行修改jdbc的配置
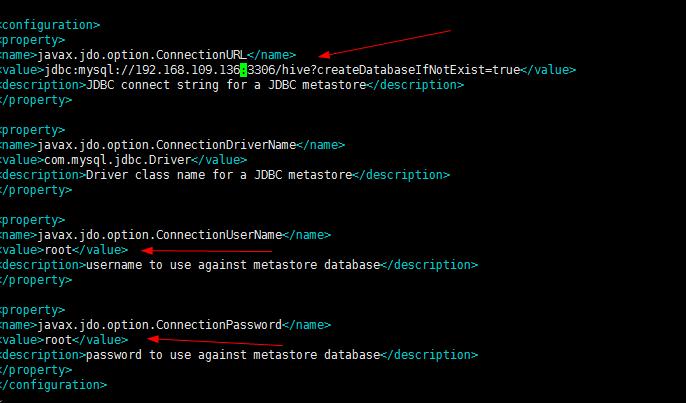
则此时这个IP要改为only的vm1下的那个IP,不能改为自己无线网络的IP
2.进入bin:./bin/hive
执行成功,会自动创建hive这个库
hive中创建person表
切记:在此之前,由于我们的mysql的字符集编码是utf-8,则我们要是用hive,则就要使用latin1
alter databases hive character set latin1
3.建表
create table person(id int,name string,age int) row format delimited fields terminated by ","
4.从hdfs导入数据
load data inpath "hdfs://192.168.109.136:9000/person/person.txt" into table person
此时上面的操作报
Please check that values for params "default.name" and "hive.metastore.warehouse.dir" do
not conf 是由于namenode的不一致
此时修改为weekday01正确
load data inpath "hdfs://weekday01:9000/person/person.txt" into table person
select * from person
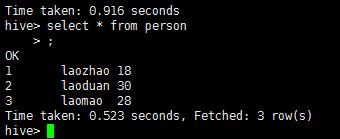
select * from person order by id desc此时这个就会调用集群上的mapReduce
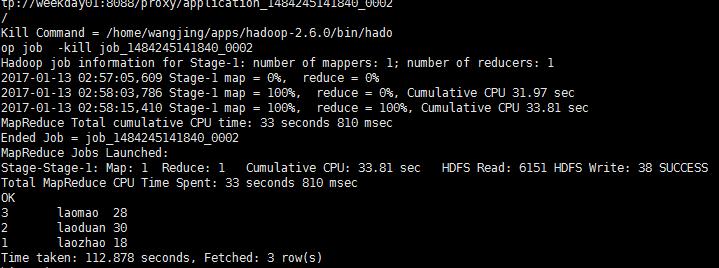
不过这个样子有点慢,我们可以使用spark来进行计算
Spark&Hive结合起来的更多相关文章
- Spark(Hive) SQL中UDF的使用(Python)
相对于使用MapReduce或者Spark Application的方式进行数据分析,使用Hive SQL或Spark SQL能为我们省去不少的代码工作量,而Hive SQL或Spark SQL本身内 ...
- Spark(Hive) SQL数据类型使用详解(Python)
Spark SQL使用时需要有若干“表”的存在,这些“表”可以来自于Hive,也可以来自“临时表”.如果“表”来自于Hive,它的模式(列名.列类型等)在创建时已经确定,一般情况下我们直接通过Spar ...
- [Spark][Hive][Python][SQL]Spark 读取Hive表的小例子
[Spark][Hive][Python][SQL]Spark 读取Hive表的小例子$ cat customers.txt 1 Ali us 2 Bsb ca 3 Carls mx $ hive h ...
- [Spark][Hive]Hive的命令行客户端启动:
[Spark][Hive]Hive的命令行客户端启动: [training@localhost Desktop]$ chkconfig | grep hive hive-metastore 0:off ...
- Spark记录-源码编译spark2.2.0(结合Hive on Spark/Hive on MR2/Spark on Yarn)
#spark2.2.0源码编译 #组件:mvn-3.3.9 jdk-1.8 #wget http://mirror.bit.edu.cn/apache/spark/spark-2.2.0/spark- ...
- Spark(Hive) SQL中UDF的使用(Python)【转】
相对于使用MapReduce或者Spark Application的方式进行数据分析,使用Hive SQL或Spark SQL能为我们省去不少的代码工作量,而Hive SQL或Spark SQL本身内 ...
- spark hive结合杂记(hive-site.xml)
1.下载spark源码,在spark源码目录下面有个make-distribution.sh文件,修改里面的参数,使编译后能支持hive,修改后执行该文件.(要预先安装好maven才能编译). 2.将 ...
- Spark&Hive:如何使用scala开发spark访问hive作业,如何使用yarn resourcemanager。
背景: 接到任务,需要在一个一天数据量在460亿条记录的hive表中,筛选出某些host为特定的值时才解析该条记录的http_content中的经纬度: 解析规则譬如: 需要解析host: api.m ...
- spark hive 结合处理 把多行变成多列
原数据格式 : gid id score a1 1 90 a1 2 80 a1 3 79 a1 ...
- Hadoop+HBase+Spark+Hive环境搭建
杨赟快跑 简书作者 2018-09-24 10:24 打开App 摘要:大数据门槛较高,仅仅环境的搭建可能就要耗费我们大量的精力,本文总结了作者是如何搭建大数据环境的(单机版和集群版),希望能帮助学弟 ...
随机推荐
- BIN文件对象数据库,直接存储对象做数据库,小型项目用它准没错
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.I ...
- 关于ubuntu安装软件的问题:apt-get和dpkg区别?
两者的区别是dpkg绕过apt包管理数据库对软件包进行操作,所以你用dpkg安装过的软件包用apt可以再安装一遍,系统不知道之前安装过了,将会覆盖之前dpkg的安装.1.dpkg是用来安装.deb文件 ...
- 源码安装zabbix3.2.7时PHP ldap Warning
问题如下: 解决方法: 1.首先查看源码安装的php模块中是否有ldap.so [root@nms ldap]# ll /usr/local/php/lib/php/extensions/no-de ...
- 如何让Oracle数据库保持优良性能的方法
OracleDatabase,又名OracleRDBMS,或简称Oracle.是甲骨文公司的一款关系数据库管理系统.它是在数据库领域一直处于领先地位的产品.可以说Oracle数据库系统是目前世界上流行 ...
- [转载]Memcached缓存服务的简单安装
1.Linux下的安装方法 下载:wget http://memcached.org/latest tar -zxvf memcached-1.x.x.tar.gz cd memcached-1.x. ...
- 目的檔格式 (ELF)
http://ccckmit.wikidot.com/lk:elf 目的檔ELF 格式(Executable and Linking Format) 是 UNIX/Linux 系統中較先進的目的檔格式 ...
- 【[TJOI2017]DNA】
[题目][https://www.lydsy.com/JudgeOnline/problem.php?id=4892] 好像用\(SAM\)做的都是\(dfs\)啊 其实这里也是搜索 如果用\(SAM ...
- python剑指offer数组中出现次数超过一半的数字
题目描述 数组中有一个数字出现的次数超过数组长度的一半,请找出这个数字.例如输入一个长度为9的数组{1,2,3,2,2,2,5,4,2}.由于数字2在数组中出现了5次,超过数组长度的一半,因此输出2. ...
- SecureCRT 设置
- mysql数值函数
abs(x) -- 绝对值 abs(-10.9) = 10 format(x, d) -- 格式化千分位数值 format(1234567.456, 2) = 1,234,567.46 ceil(x) ...