吴裕雄--天生自然python爬虫:使用requests模块的get和post方式抓取中国旅游网站和有道翻译网站翻译内容数据
import requests url = 'http://www.cntour.cn/'
strhtml = requests.get(url)
print(strhtml.text)

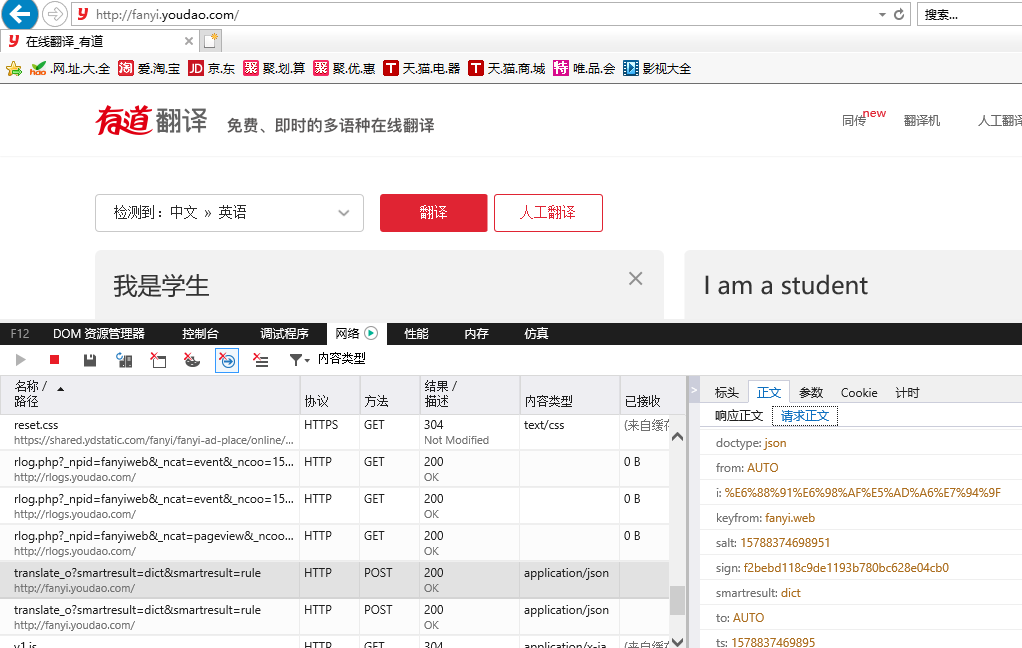

URL='http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule' #post请求需要写请求访问,请求内容可以在对应网页的开发者模式中获取,谷歌浏览器显示不出来,我使用的是IE浏览器
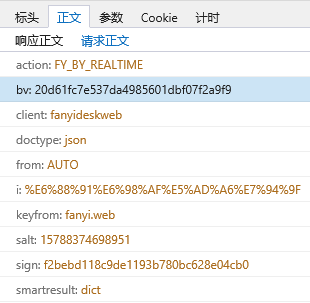
Form_data = {
'action': 'FY_BY_REALTlME',
'bv': '20d61fc7e537da4985601dbf07f2a9f9',
'client': 'fanyideskweb',
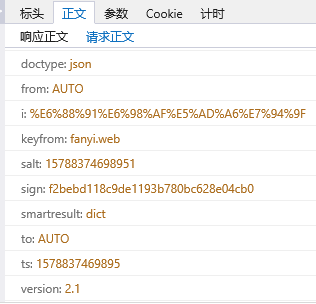
'doctype': 'json',
'from': 'AUTO',
'i': '我是学生',
'keyfrom': 'fanyi.web',
'salt': '',
'sign': 'f2bebd118c9de1193b780bc628e04cb0',
'smartresult': 'dict',
'to': 'AUTO',
'ts': '',
'version': '2.1'
} import requests response = requests.post(URL,data=Form_data)

import json
import requests def get_translate_date(word=None):
url='http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule'
Form_data = {'i':word, 'from':'AUTO','to': 'AUTO','smartresult': 'dict', 'client':'fanyideskweb',
'salt':'','sign':'78181ebbdcb38de9b4a3f4cd1d38816b','doctype':'json',
'version': '2.1','keyfrom':'fanyi.web','action':'FY_BY_CLICKBUTTION','typoResult':'false'}
response = requests.post(url, data=Form_data) # 请求表单数据
print(response.text)
content = json.loads(response.text) # 将JSON格式字符串转字典
print(content['translateResult'][0][0]['tgt']) # 打印翻译后的数据
if __name__ == '__main__':
get_translate_date('我爱数据')

吴裕雄--天生自然python爬虫:使用requests模块的get和post方式抓取中国旅游网站和有道翻译网站翻译内容数据的更多相关文章
- 吴裕雄--天生自然PYTHON爬虫:使用Selenium爬取大型电商网站数据
用python爬取动态网页时,普通的requests,urllib2无法实现.例如有些网站点击下一页时,会加载新的内容,但是网页的URL却没有改变(没有传入页码相关的参数),requests.urll ...
- 吴裕雄--天生自然PYTHON爬虫:使用Scrapy抓取股票行情
Scrapy框架它能够帮助提升爬虫的效率,从而更好地实现爬虫.Scrapy是一个为了抓取网页数据.提取结构性数据而编写的应用框架,该框架是封装的,包含request异步调度和处理.下载器(多线程的Do ...
- 吴裕雄--天生自然PYTHON爬虫:爬虫攻防战
我们在开发者模式下不仅可以找到URL.Form Data,还可以在Request headers 中构造浏览器的请求头,封装自己.服务器识别浏览器访问的方法就是判断keywor是否为Request h ...
- 吴裕雄--天生自然PYTHON爬虫:安装配置MongoDBy和爬取天气数据并清洗保存到MongoDB中
1.下载MongoDB 官网下载:https://www.mongodb.com/download-center#community 上面这张图选择第二个按钮 上面这张图直接Next 把bin路径添加 ...
- 吴裕雄--天生自然PYTHON爬虫:爬取某一大型电商网站的商品数据(效率优化以及代码容错处理)
这篇博文主要是对我的这篇https://www.cnblogs.com/tszr/p/12198054.html爬虫效率的优化,目的是为了提高爬虫效率. 可以根据出发地同时调用多个CPU,每个CPU运 ...
- 吴裕雄--天生自然PYTHON爬虫:用API爬出天气预报信息
天气预报网址:https://id.heweather.com/,这个网站是需要注册获取一个个人认证后台密钥key的,并且每个人都有访问次数的限制,这个key就是访问API的钥匙. 这个key现在是要 ...
- 吴裕雄--天生自然PYTHON爬虫:使用BeautifulSoup解析中国旅游网页数据
import requests from bs4 import BeautifulSoup url = "http://www.cntour.cn/" strhtml = requ ...
- 吴裕雄--天生自然python编程:turtle模块绘图(3)
turtle(海龟)是Python重要的标准库之一,它能够进行基本的图形绘制.turtle图形绘制的概念诞生于1969年,成功应用于LOGO编程语言. turtle库绘制图形有一个基本框架:一个小海龟 ...
- 吴裕雄--天生自然python编程:turtle模块绘图(1)
Turtle库是Python语言中一个很流行的绘制图像的函数库,想象一个小乌龟,在一个横轴为x.纵轴为y的坐标系原点,(0,0)位置开始,它根据一组函数指令的控制,在这个平面坐标系中移动,从而在它爬行 ...
随机推荐
- 疯狂python(分享本不错的书)
网盘链接:https://pan.baidu.com/s/1JDawVe8CT9BsHav5gBZS6Q 提取码vg8k
- python正则表达式中括号的作用,形如 "(\w+)\s+\w+"
先看一个例子: import re string="abcdefg acbdgef abcdgfe cadbgfe" #带括号与不带括号的区别 regex=re.compile(& ...
- 00-Docker基本安装
目录 00-Docker基本安装 参考 安装与配置 启动与测试 00-Docker基本安装 Docker Version: 19.03.5
- set的使用-Hdu 2094
产生冠军 Time Limit: 1000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total Submis ...
- JS中 逻辑或 || 逻辑与 && 的使用方法总结
JS中 逻辑或 || 逻辑与 && 的使用方法总结 //1.在if判断中 //if(1==1 || 2==3){}//->两个条件中只要有一个条件为真,整体就为真 "或 ...
- /usr/lib64/libstdc++.so.6: version `GLIBCXX_3.4.15' not found的解决办法
#############################BEGIN############################# strings /usr/lib64/libstdc++.so.6.0. ...
- Ubuntu各个版本的镜像下载地址
http://mirrors.melbourne.co.uk/ubuntu-releases/
- java模板字符串功能的简单实现
package com.Interface.util; import lombok.extern.slf4j.Slf4j; /** * 测试类 * * @author 华文 * @date 2019年 ...
- 基于Modelsim的视频捕获模拟仿真
一.前言 针对牟新刚编著的<基于FPGA的数字图像处理原理及应用>中第五章系统仿真中关于视频捕获模拟的例子进行补充和仿真验证,简言之,吊书袋子. 2020-02-27 21:09:05 二 ...
- case语句!
1.case 语句概述(1)case 语句的作用使用 case 语句改写 if 多分支可以使脚本结构更加清晰.层次分明.针对变量的不同取值,执行不同的命令序列.2.case 语句的结构:case 变量 ...