吴裕雄--天生自然python爬虫:使用requests模块的get和post方式抓取中国旅游网站和有道翻译网站翻译内容数据
import requests url = 'http://www.cntour.cn/'
strhtml = requests.get(url)
print(strhtml.text)

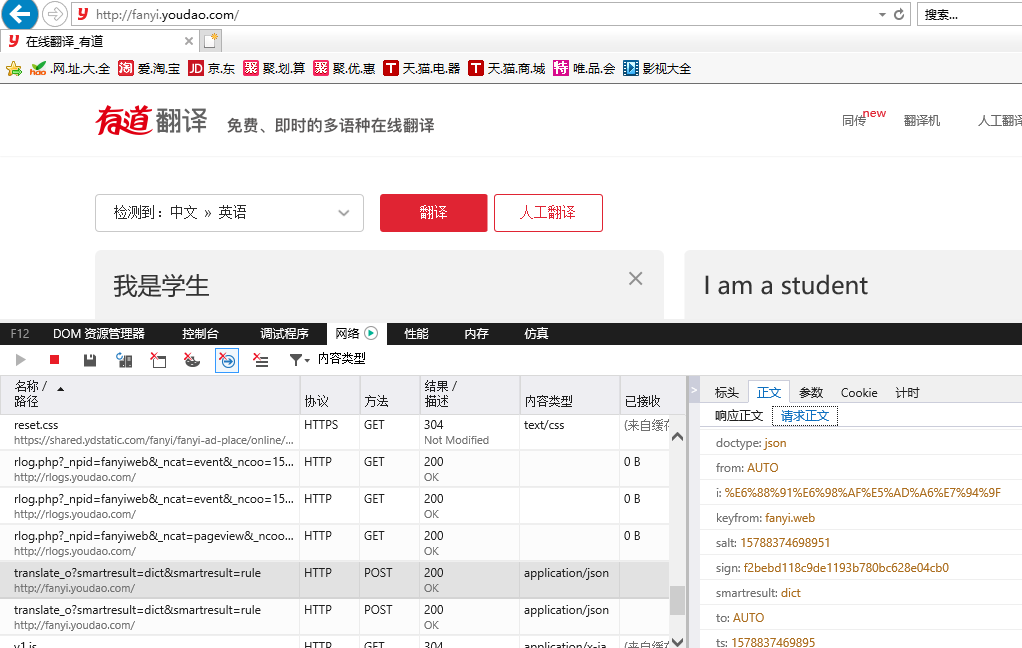

URL='http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule' #post请求需要写请求访问,请求内容可以在对应网页的开发者模式中获取,谷歌浏览器显示不出来,我使用的是IE浏览器
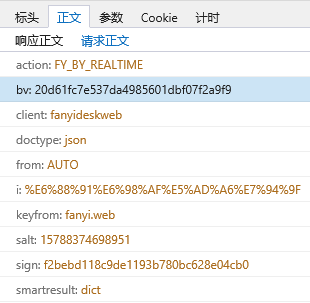
Form_data = {
'action': 'FY_BY_REALTlME',
'bv': '20d61fc7e537da4985601dbf07f2a9f9',
'client': 'fanyideskweb',
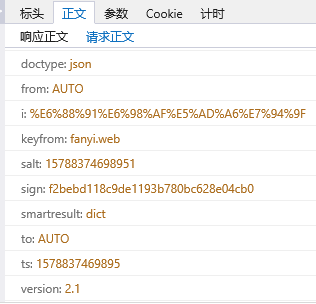
'doctype': 'json',
'from': 'AUTO',
'i': '我是学生',
'keyfrom': 'fanyi.web',
'salt': '',
'sign': 'f2bebd118c9de1193b780bc628e04cb0',
'smartresult': 'dict',
'to': 'AUTO',
'ts': '',
'version': '2.1'
} import requests response = requests.post(URL,data=Form_data)

import json
import requests def get_translate_date(word=None):
url='http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule'
Form_data = {'i':word, 'from':'AUTO','to': 'AUTO','smartresult': 'dict', 'client':'fanyideskweb',
'salt':'','sign':'78181ebbdcb38de9b4a3f4cd1d38816b','doctype':'json',
'version': '2.1','keyfrom':'fanyi.web','action':'FY_BY_CLICKBUTTION','typoResult':'false'}
response = requests.post(url, data=Form_data) # 请求表单数据
print(response.text)
content = json.loads(response.text) # 将JSON格式字符串转字典
print(content['translateResult'][0][0]['tgt']) # 打印翻译后的数据
if __name__ == '__main__':
get_translate_date('我爱数据')

吴裕雄--天生自然python爬虫:使用requests模块的get和post方式抓取中国旅游网站和有道翻译网站翻译内容数据的更多相关文章
- 吴裕雄--天生自然PYTHON爬虫:使用Selenium爬取大型电商网站数据
用python爬取动态网页时,普通的requests,urllib2无法实现.例如有些网站点击下一页时,会加载新的内容,但是网页的URL却没有改变(没有传入页码相关的参数),requests.urll ...
- 吴裕雄--天生自然PYTHON爬虫:使用Scrapy抓取股票行情
Scrapy框架它能够帮助提升爬虫的效率,从而更好地实现爬虫.Scrapy是一个为了抓取网页数据.提取结构性数据而编写的应用框架,该框架是封装的,包含request异步调度和处理.下载器(多线程的Do ...
- 吴裕雄--天生自然PYTHON爬虫:爬虫攻防战
我们在开发者模式下不仅可以找到URL.Form Data,还可以在Request headers 中构造浏览器的请求头,封装自己.服务器识别浏览器访问的方法就是判断keywor是否为Request h ...
- 吴裕雄--天生自然PYTHON爬虫:安装配置MongoDBy和爬取天气数据并清洗保存到MongoDB中
1.下载MongoDB 官网下载:https://www.mongodb.com/download-center#community 上面这张图选择第二个按钮 上面这张图直接Next 把bin路径添加 ...
- 吴裕雄--天生自然PYTHON爬虫:爬取某一大型电商网站的商品数据(效率优化以及代码容错处理)
这篇博文主要是对我的这篇https://www.cnblogs.com/tszr/p/12198054.html爬虫效率的优化,目的是为了提高爬虫效率. 可以根据出发地同时调用多个CPU,每个CPU运 ...
- 吴裕雄--天生自然PYTHON爬虫:用API爬出天气预报信息
天气预报网址:https://id.heweather.com/,这个网站是需要注册获取一个个人认证后台密钥key的,并且每个人都有访问次数的限制,这个key就是访问API的钥匙. 这个key现在是要 ...
- 吴裕雄--天生自然PYTHON爬虫:使用BeautifulSoup解析中国旅游网页数据
import requests from bs4 import BeautifulSoup url = "http://www.cntour.cn/" strhtml = requ ...
- 吴裕雄--天生自然python编程:turtle模块绘图(3)
turtle(海龟)是Python重要的标准库之一,它能够进行基本的图形绘制.turtle图形绘制的概念诞生于1969年,成功应用于LOGO编程语言. turtle库绘制图形有一个基本框架:一个小海龟 ...
- 吴裕雄--天生自然python编程:turtle模块绘图(1)
Turtle库是Python语言中一个很流行的绘制图像的函数库,想象一个小乌龟,在一个横轴为x.纵轴为y的坐标系原点,(0,0)位置开始,它根据一组函数指令的控制,在这个平面坐标系中移动,从而在它爬行 ...
随机推荐
- POJ 1061 青蛙的约会(exgcd)
嗯... 题目链接:http://poj.org/problem?id=1061 两只青蛙相遇时肯定满足:x+k*m≡y+k*n(mod L) x+k*m-(y+k*n)=L*s k*(n-m)-s* ...
- mcast_set_loop函数
#include <errno.h> #include <sys/socket.h> #include <net/if.h> #include <netine ...
- IE浏览器清浮动
.cfx:after,.cfx:before{content:" ";display:table;}.cfx:after{clear:both;}.cfx{*zoom:1;} 今天 ...
- C++中使用sstream进行类型转换(数字字符串转数字、数字转数字字符串)
1.sstream知识 sstream即字符串流.在使用字符串流sstream时,需要先引入相应的头文件 "#include <sstream>" 基本操作 // 引入 ...
- SpringBoot基于数据库的定时任务实现
在我们平时开发的项目中,定时任务基本属于必不可少的功能,那大家都是怎么做的呢?但我知道的大多都是静态定时任务实现. 基于注解来创建定时任务非常简单,只需几行代码便可完成.实现如下: @Configur ...
- 喵星之旅-狂奔的兔子-redis使用
一.命令行使用 redis大概有200多命令,这里只是入门级别,列举了一些非常常见的内容,如果这些会了就可以开启redis进一步学习了. 1.登录数据库 我们需要知道ip地址.端口号.密码(如果有). ...
- 最全的Java操作Redis的工具类,使用StringRedisTemplate实现,封装了对Redis五种基本类型的各种操作!
转载自:https://github.com/whvcse/RedisUtil 代码 ProtoStuffSerializerUtil.java import java.io.ByteArrayInp ...
- Spring Boot 中使用 HttpClient 进行 POST GET PUT DELETE
有的时候,我们的 Spring Boot 应用需要调用第三方接口,这个接口可能是 Http协议.可能是 WebService.可能是 FTP或其他格式,本章讨论 Http 接口的调用. 通常基于 Ht ...
- [原]用SQL比较两张结构完全相同的表数据
前几天面试遇到一个比较有意思的问题,就是有两张结构完全相同的表A和B,但是这两张表属于不同的业务流程,经过一段时间后发现两张表的数据不能完全匹配,有可能A比B多,也可能B比A多,或者两种可能同时存在, ...
- windows与linux的文件路径
在windows操作系统中,文件路径的分隔符是反斜杠(“\\”),例如: E:\\hsta\\pdf(这里为防止转义,所以要写成两个反斜杠) 但是在linux操作系统中,文件的分隔符是斜杠(“/”), ...