【爬虫实战】用Python采集任意小红书笔记下的评论,爬了10000多条,含二级评论!
一、爬取目标
您好!我是@马哥python说 ,一名10年程序猿。
我们继续分享Python爬虫的案例,今天爬取小红书上指定笔记("巴勒斯坦"相关笔记)下的评论数据。
老规矩,先展示结果:
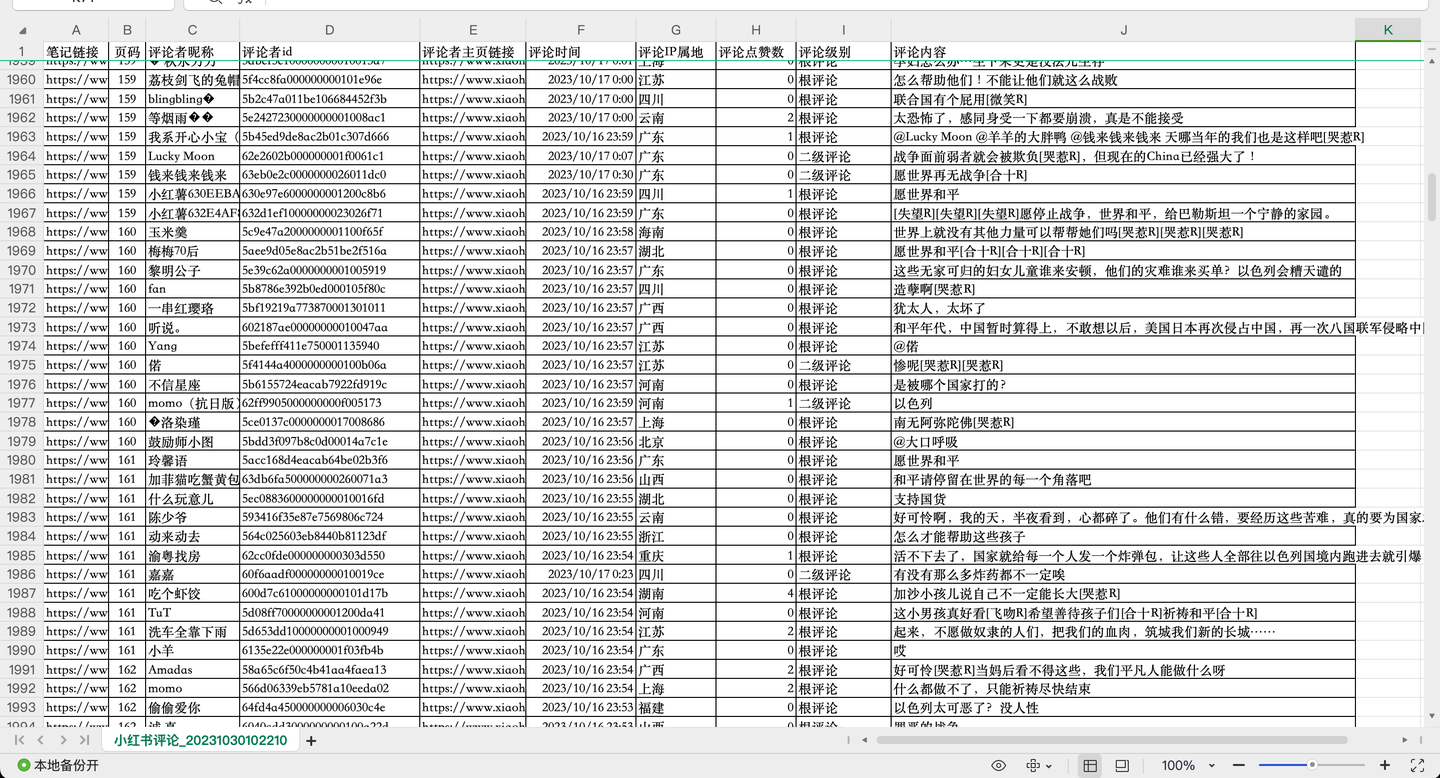
截图1:
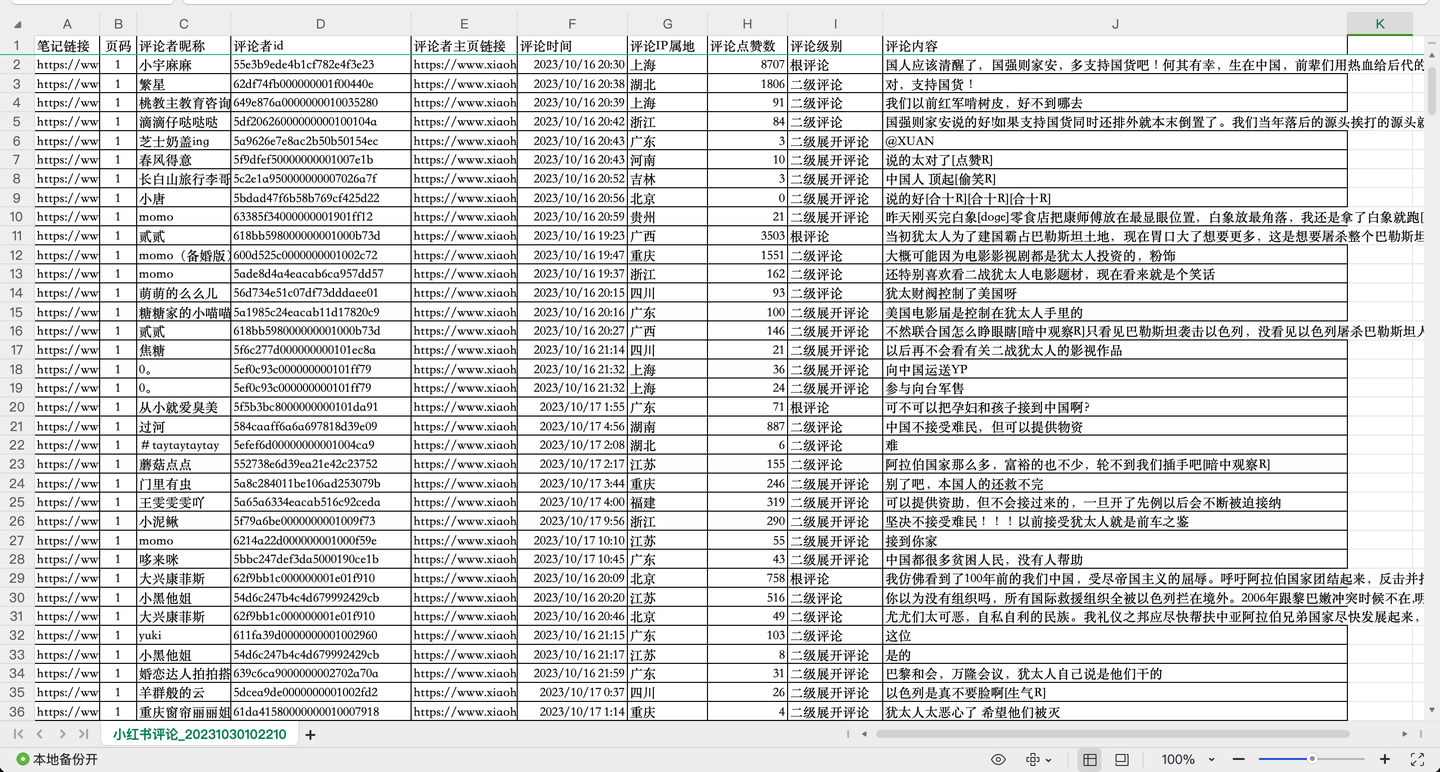
截图2:
截图3:
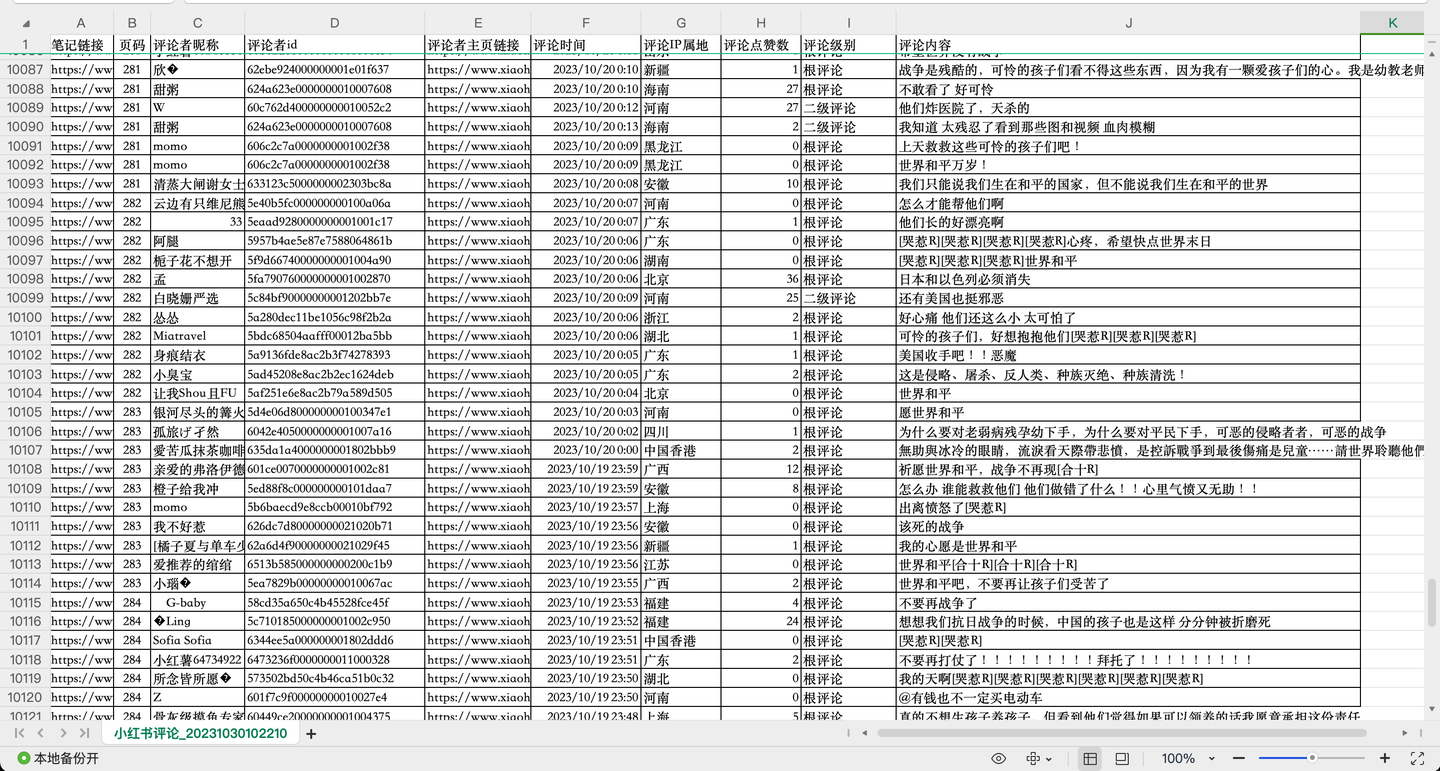
共爬取了1w多条"巴勒斯坦"相关评论,每条评论含10个关键字段,包括:
笔记链接, 页码, 评论者昵称, 评论者id, 评论者主页链接, 评论时间, 评论IP属地, 评论点赞数, 评论级别, 评论内容。
其中,评论级别包括:根评论、二级评论及二级展开评论。
二、爬虫代码讲解
2.1 分析过程
任意打开一个小红书笔记的评论,打开浏览器的开发者模式,网络,XHR,找到目标链接的预览数据,如下:
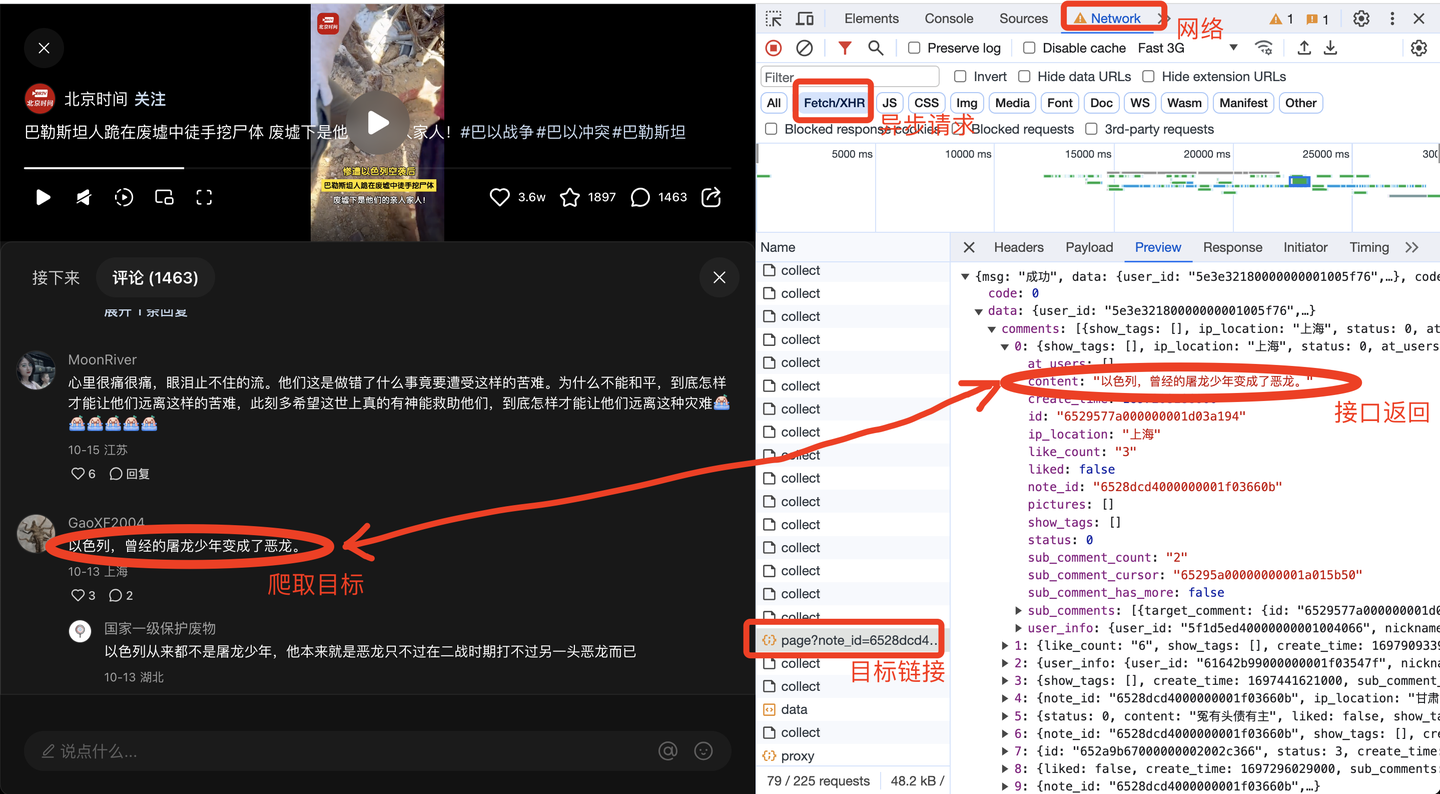
由此便得到了前端请求链接,下面开始开发爬虫代码。
2.2 爬虫代码
首先,导入需要用到的库:
import requests
from time import sleep
import pandas as pd
import os
import time
import datetime
import random
定义一个请求头:
# 请求头
h1 = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36',
# cookie需定期更换
'Cookie': '换成自己的cookie值',
}
经过我的实际测试,请求头包含User-Agent和Cookie这两项,即可实现爬取。
其中,Cookie很关键,需要定期更换。那么Cookie从哪里获得呢?方法如下:
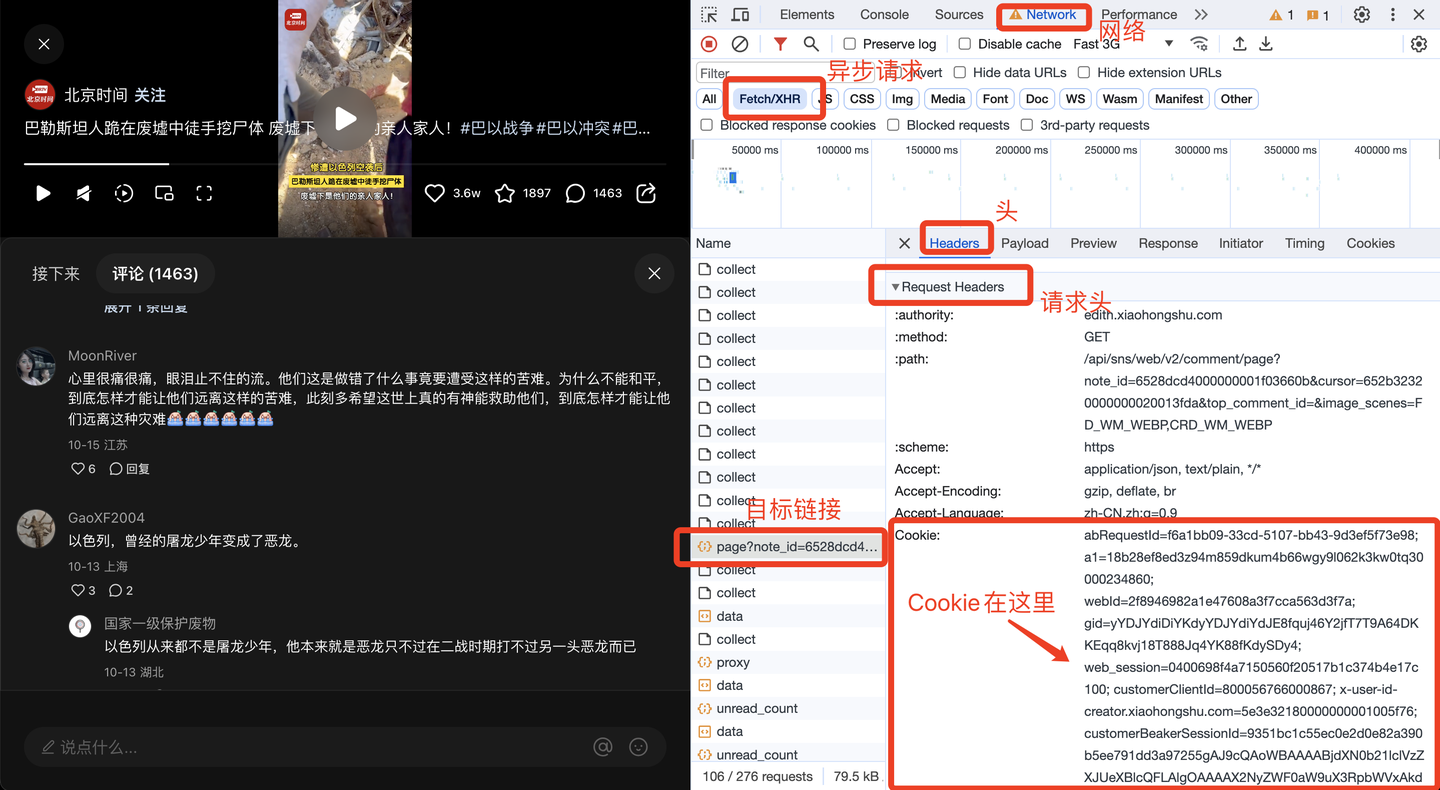
下面,开发翻页逻辑。
由于我并不知道一共有多少页,往下翻多少次,所以采用while循环,直到触发终止条件,循环才结束。
那么怎么定义终止条件呢?我注意到,在返回数据里有一个叫做"has_more"的参数,大胆猜测它的含义,是否有更多数据,正常情况它的值是true。如果它的值是false,代表没有更多数据了,即到达最后一页了,也就该终止循环了。
因此,核心代码结构应该是这样(以下是伪代码,主要是表达逻辑,请勿直接copy):
while True:
# 发送请求
r = requests.get(url, headers=h1)
# 解析数据
json_data = r.json()
# 逐条解析
for c in json_data['data']['comments']:
# 评论内容
content = c['content']
content_list.append(content)
# 保存数据到csv
。。。
# 判断终止条件
next_cursor = json_data['data']['cursor']
if not json_data['data']['has_more']:
print('没有下一页了,终止循环!')
break
page += 1
另外,还有一个关键问题,如何进行翻页。
查看请求参数,如下:
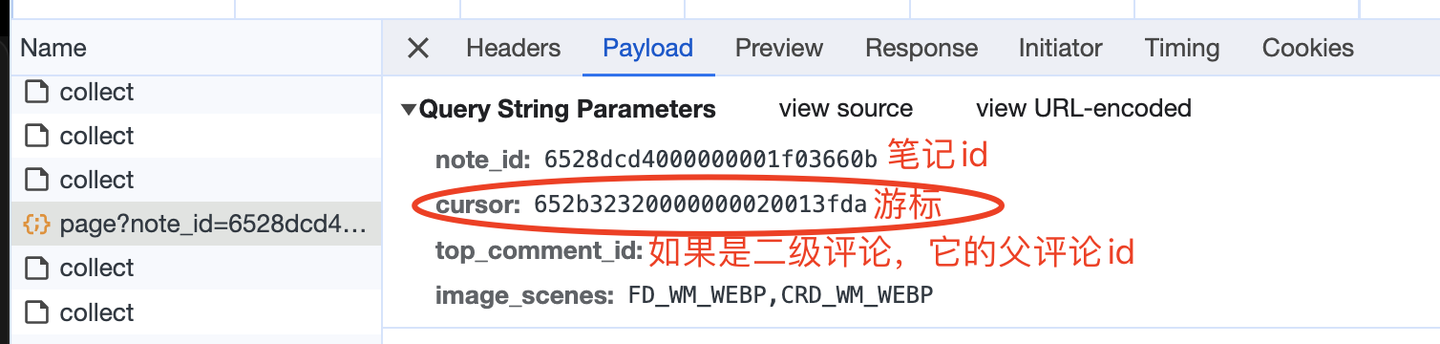
这里的游标,就是向下翻页的依据,因为每次请求的返回数据中,也有一个cursor:
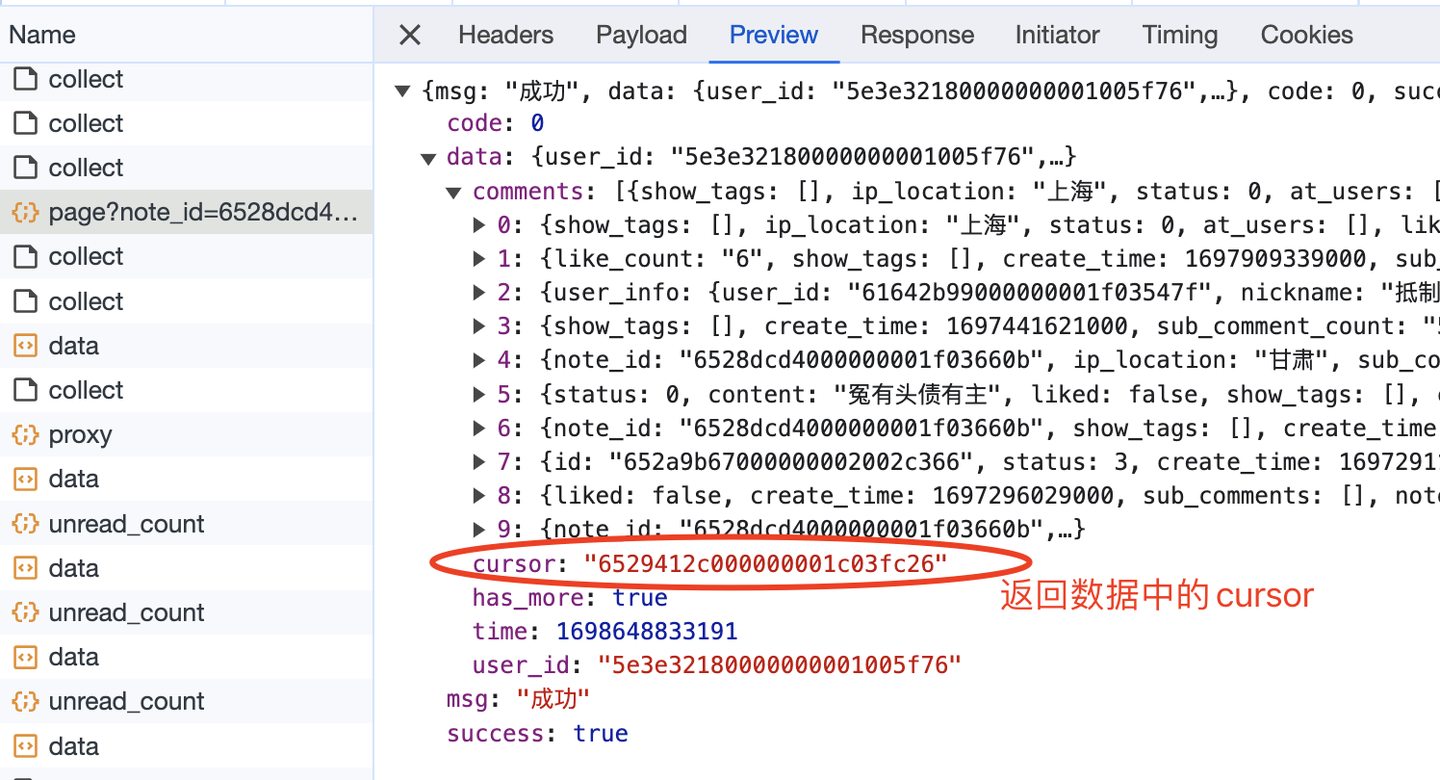
大胆猜测,返回数据中的cursor,就是给下一页请求用的cursor,所以,这部分的逻辑实现应该如下(以下是伪代码,主要是表达逻辑,请勿直接copy):
while True:
if page == 1:
url = 'https://edith.xiaohongshu.com/api/sns/web/v2/comment/page?note_id={}&top_comment_id=&image_scenes=FD_WM_WEBP,CRD_WM_WEBP'.format(
note_id)
else:
url = 'https://edith.xiaohongshu.com/api/sns/web/v2/comment/page?note_id={}&top_comment_id=&image_scenes=FD_WM_WEBP,CRD_WM_WEBP&cursor={}'.format(
note_id, next_cursor)
# 发送请求
r = requests.get(url, headers=h1)
# 解析数据
json_data = r.json()
# 得到下一页的游标
next_cursor = json_data['data']['cursor']
另外,我在第一章节提到,还爬到了二级评论及二级展开评论,怎么做到的呢?
经过分析,返回数据中有个节点sub_comment_count代表子评论数量,如果大于0代表该评论有子评论,进而可以从sub_comments节点中爬取二级评论。
其中,二级展开评论,请求参数中的root_comment_id代表父评论的id,其他逻辑同理,不再赘述。
最后,是顺理成章的保存csv数据:
# 保存数据到DF
df = pd.DataFrame(
{
'笔记链接': 'https://www.xiaohongshu.com/explore/' + note_id,
'页码': page,
'评论者昵称': nickname_list,
'评论者id': user_id_list,
'评论者主页链接': user_link_list,
'评论时间': create_time_list,
'评论IP属地': ip_list,
'评论点赞数': like_count_list,
'评论级别': comment_level_list,
'评论内容': content_list,
}
)
# 设置csv文件表头
if os.path.exists(result_file):
header = False
else:
header = True
# 保存到csv
df.to_csv(result_file, mode='a+', header=header, index=False, encoding='utf_8_sig')
至此,爬虫代码开发完毕。
完整代码中,还包含转换时间戳、随机等待时长、解析其他字段、保存Dataframe数据、多个笔记同时循环爬取等关键逻辑,详见演示视频。
三、演示视频
代码演示:【Python爬虫】用python爬了10000条小红书评论,以#巴勒斯坦#为例
我是@马哥python说,一名10年程序猿,持续分享python干货中!
【爬虫实战】用Python采集任意小红书笔记下的评论,爬了10000多条,含二级评论!的更多相关文章
- 【2022知乎爬虫】我用Python爬虫爬了2300多条知乎评论!
您好,我是 @马哥python说,一枚10年程序猿. 一.爬取目标 前些天我分享过一篇微博的爬虫: https://www.cnblogs.com/mashukui/p/16414027.html 但 ...
- Python简单网络爬虫实战—下载论文名称,作者信息(下)
在Python简单网络爬虫实战—下载论文名称,作者信息(上)中,学会了get到网页内容以及在谷歌浏览器找到了需要提取的内容的数据结构,接下来记录我是如何找到所有author和title的 1.从sou ...
- python核心编程一书笔记之第一篇
#!/usr/bin/env python# -*- coding:utf-8 -*- #env 是一个命令用来寻找系统中的python解释器.第二条解释使用utf-8编码 在类unix系统中允许py ...
- 简单python爬虫编写,Python采集妹子图!
疫情期间在家闲来无事,每天打游戏荒废了一段时间.我觉得自己不能在这么颓废下去,就立马起身写了一点python代码(本人只是python新手). 很多人学习python,不知道从何学起.很多人学习pyt ...
- python参考手册一书笔记之第一篇上
在python2和python3的版本差异很大输出hello world的方法在2里支持在3里就不支持了. print 'hello world' #在2中支持 print ('hello world ...
- python网络爬虫实战PDF高清完整版免费下载|百度云盘|Python基础教程免费电子书
点击获取提取码:vg1y python网络爬虫实战帮助读者学习Python并开发出符合自己要求的网络爬虫.网络爬虫,又被称为网页蜘蛛,网络机器人,是一种按照一定的规则,自动地抓取互联网信息的程序或者脚 ...
- selenium2自动化测试实战--基于Python语言
自动化测试基础 一. 软件测试分类 1.1 根据项目流程阶段划分软件测试 1.1.1 单元测试 单元测试(或模块测试)是对程序中的单个子程序或具有独立功能的代码段进行测试的过程. 1.1.2 集成测试 ...
- Python爬虫实战(4):豆瓣小组话题数据采集—动态网页
1, 引言 注释:上一篇<Python爬虫实战(3):安居客房产经纪人信息采集>,访问的网页是静态网页,有朋友模仿那个实战来采集动态加载豆瓣小组的网页,结果不成功.本篇是针对动态网页的数据 ...
- Python爬虫实战---抓取图书馆借阅信息
Python爬虫实战---抓取图书馆借阅信息 原创作品,引用请表明出处:Python爬虫实战---抓取图书馆借阅信息 前段时间在图书馆借了很多书,借得多了就容易忘记每本书的应还日期,老是担心自己会违约 ...
- Python爬虫实战八之利用Selenium抓取淘宝匿名旺旺
更新 其实本文的初衷是为了获取淘宝的非匿名旺旺,在淘宝详情页的最下方有相关评论,含有非匿名旺旺号,快一年了淘宝都没有修复这个. 可就在今天,淘宝把所有的账号设置成了匿名显示,SO,获取非匿名旺旺号已经 ...
随机推荐
- 处理.git文件夹过大出现臃肿问题-filter-branch和BFG工具
Git开发手册 git一些不常用的命令记不住,可以查看git开发手册(https://m.php.cn/manual/view/34957.html) 1..git/objects/pack 文件过大 ...
- docker安装8版本elasticsearch遇到的问题FileSystemException
docker安装8版本elasticsearch遇到的问题 Exception in thread "main" java.nio.file.FileSystemException ...
- 安装centos系统,硬盘检测报错:修改BIOS为 Legacy
进bios,将模式修改为legacy. 硬盘使用 MBR 分区,需要用 Legacy BIOS 启动,而不是 UEFI BIOS . 至于为什么安装的时候会报错? 可能是系统有这方面限制.也可能是别的 ...
- MySQL配置简单优化与读写测试
测试方法 先使用sysbench对默认配置的MySQL单节点进行压测,单表数据量为100万,数据库总数据量为2000万,每次压测300秒. sysbench --db-driver=mysql --t ...
- 重学HTTP:理解同源策略和CORS
每次遇到跨域.代理.CORS这几个词都懵懵的,我决定一次把他们都搞明白,以后遇到他们再也不用害怕了. 一.什么是同源策略? 同源策略是在1995年由 Netscape公司引入到浏览器的,目前所有浏览 ...
- 性能监控平台搭建(grafana+telegraf+influxdb) 及 配置 jmeter后端监听
搞性能测试,可以搭建Grafana+Telegraf+InfluxDB 监控平台,监控服务器资源使用率.jmeter性能测试结果等. telegraf: 是一个用 Go 编写的代理程序,可收集系统和服 ...
- Java并发编程 优化多任务查询接口
代码展示 @RestController @RequestMapping("/api") public class TestController { @Resource priva ...
- 《Kali渗透基础》10. 提权、后渗透
@ 目录 1:提权 2:Admin 提权为 System 2.1:at 2.2:sc 2.3:SysInternal Suite 2.4:进程注入提权 3:抓包嗅探 4:键盘记录 5:本地缓存密码 5 ...
- Gopher进阶神器:拥抱刻意练习,从新手到大师。
发现一个非常友好的工具,帮助我们回顾练习过程,设定目标,并提供丰富多样的Gopher主题练习题. 刻意练习:从新手到大师. Carol 心理学家 Carol Dweck 做过一个实验,她找了一些十岁的 ...
- 对比 MyBatis 和 MyBatis-Plus 批量插入、批量更新的性能和区别
1 环境准备 demo 地址:learn-mybatis · Sean/spring-cloud-alibaba - 码云(gitee.com) 1.1 搭建 MyBatis-Plus 环境 创建 m ...