Python之爬虫(十九) Scrapy框架中Download Middleware用法
这篇文章中写了常用的下载中间件的用法和例子。
Downloader Middleware处理的过程主要在调度器发送requests请求的时候以及网页将response结果返回给spiders的时候,所以从这里我们可以知道下载中间件是介于Scrapy的request/response处理的钩子,用于修改Scrapy request和response。
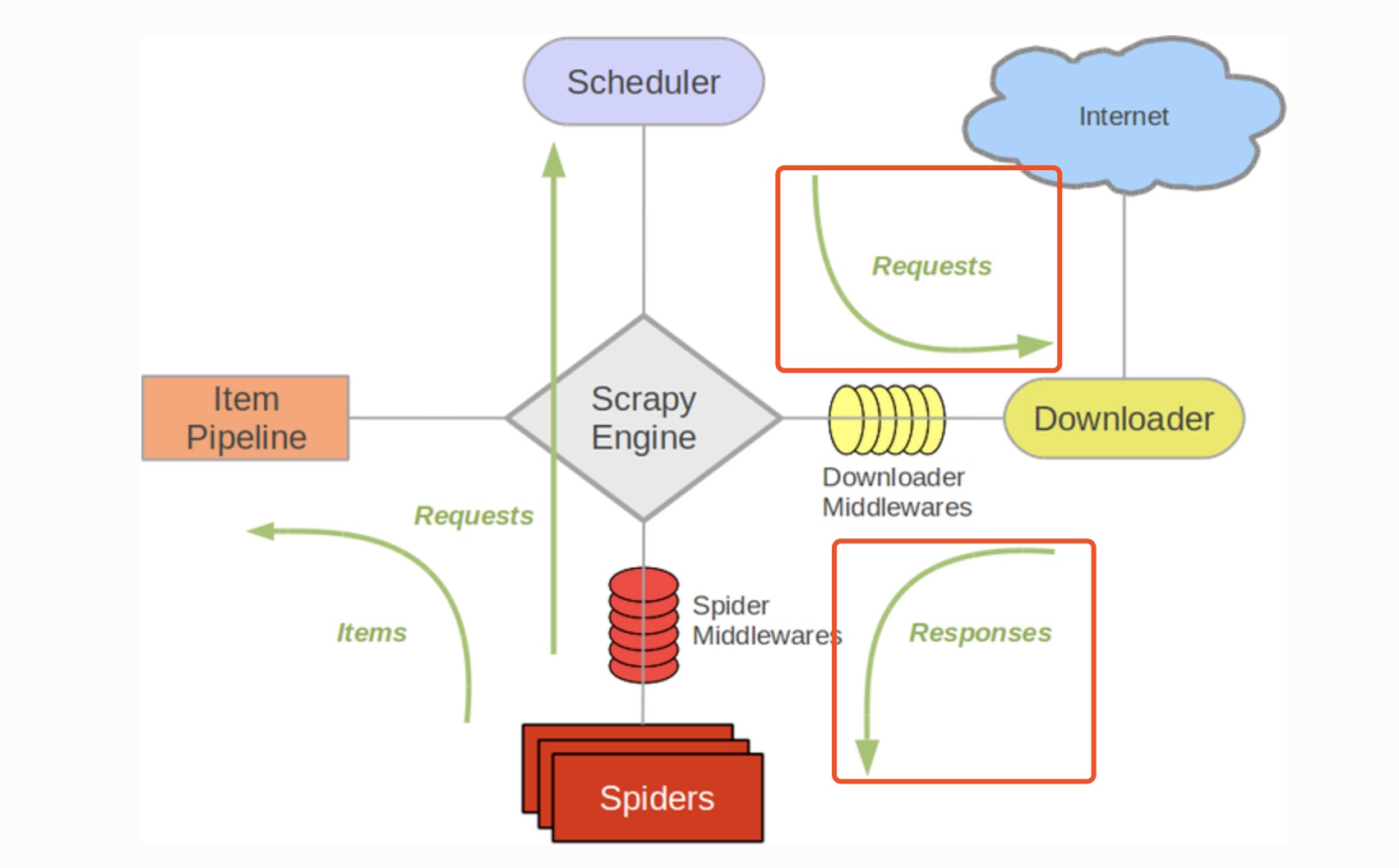
编写自己的下载器中间件
编写下载器中间件,需要定义以下一个或者多个方法的python类
为了演示这里的中间件的使用方法,这里创建一个项目作为学习,这里的项目是关于爬去httpbin.org这个网站
scrapy startproject httpbintest
cd httpbintest
scrapy genspider example example.com
创建好后的目录结构如下:
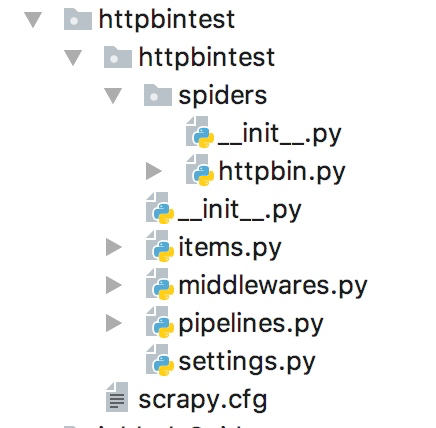
这里我们先写一个简单的代理中间件来实现ip的伪装
创建好爬虫之后我们讲httpbin.py中的parse方法改成:
def parse(self, response):
print(response.text)
然后通过命令行启动爬虫:scrapy crawl httpbin
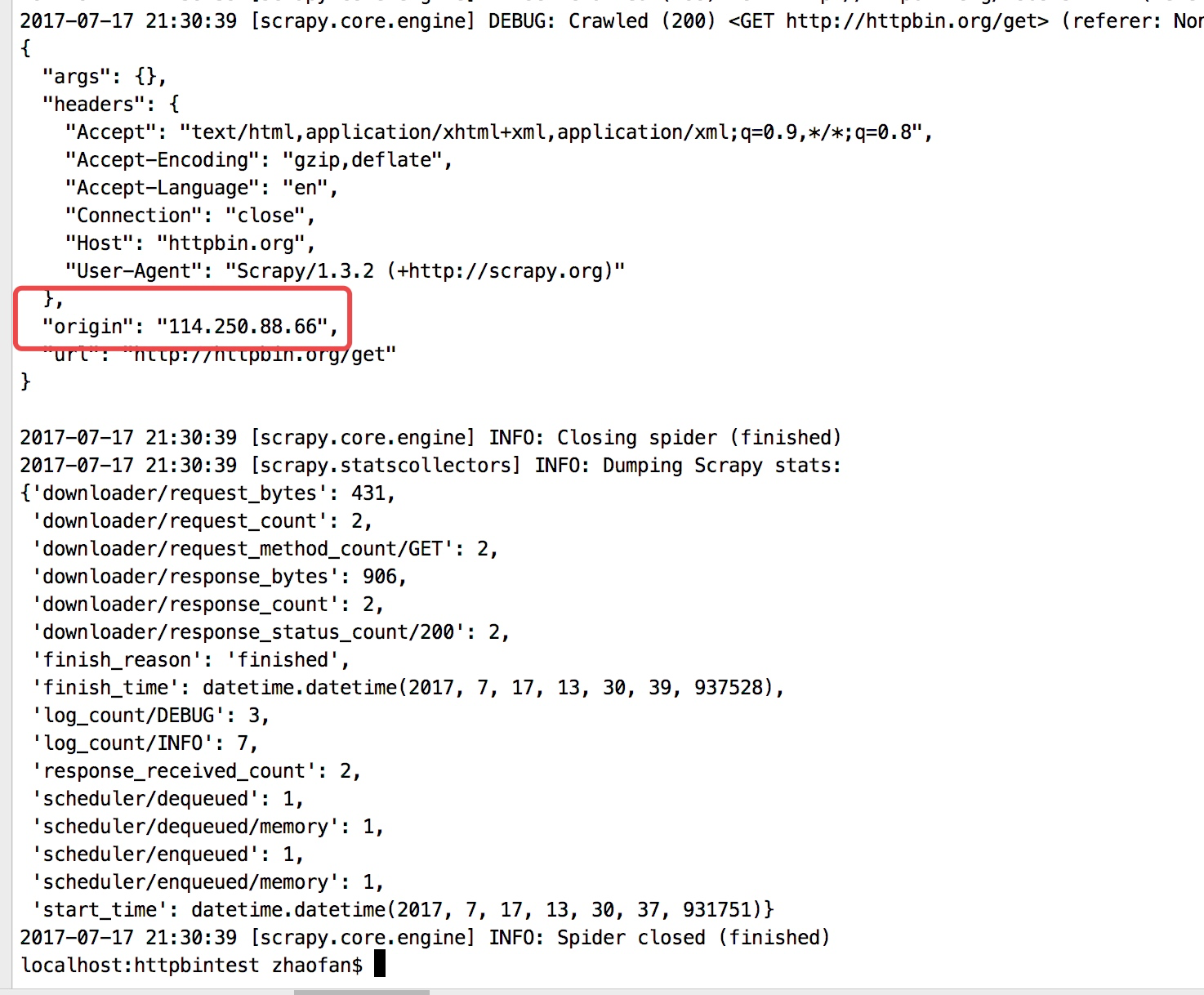
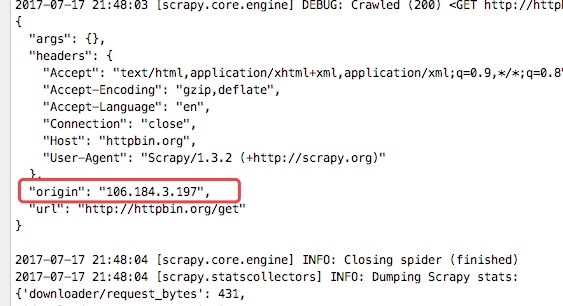
在最下面我们可以看到"origin": "114.250.88.66"
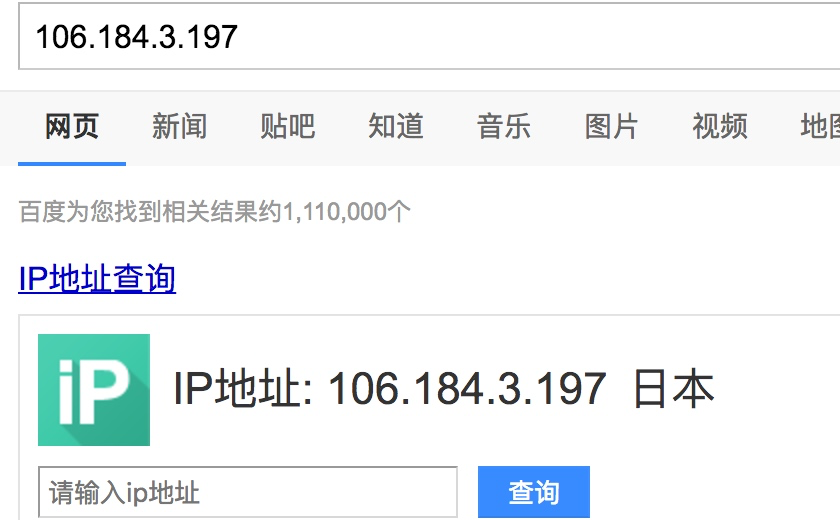
我们在查看自己的ip:
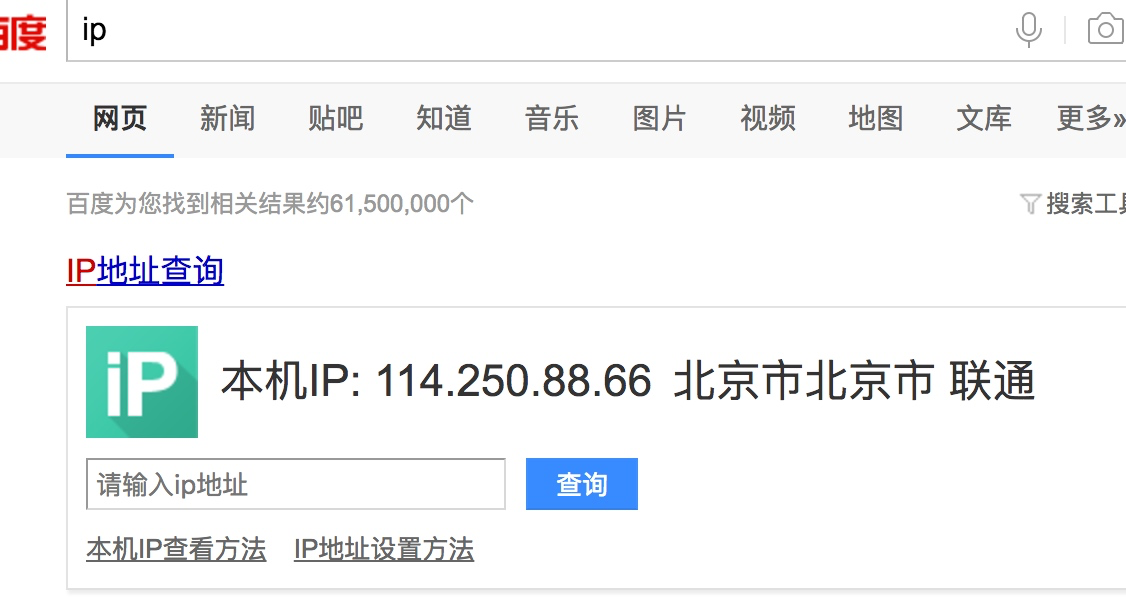
而我们要做就是通过代理中间件来实现ip的伪装,在middleares.py中写如下的中间件类:
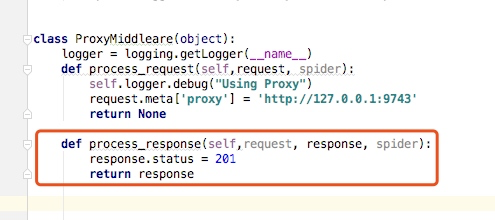
class ProxyMiddleare(object):
logger = logging.getLogger(__name__)
def process_request(self,request, spider):
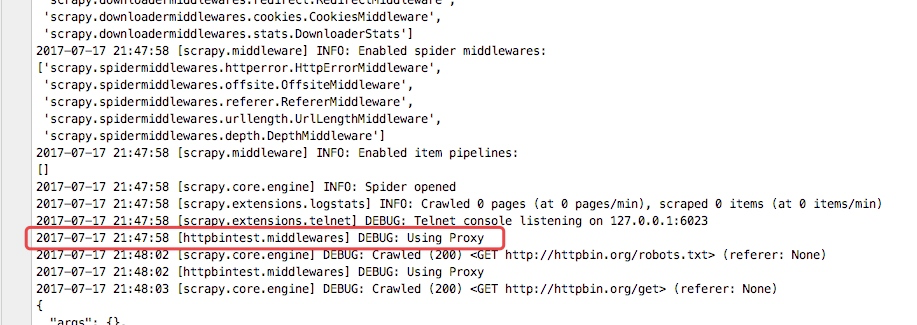
self.logger.debug("Using Proxy")
request.meta['proxy'] = 'http://127.0.0.1:9743'
return None
这里因为我本地有一个代理FQ地址为:http://127.0.0.1:9743
所以直接设置为代理用,代理的地址为日本的ip
然后在settings.py配置文件中开启下载中间件的功能,默认是关闭的
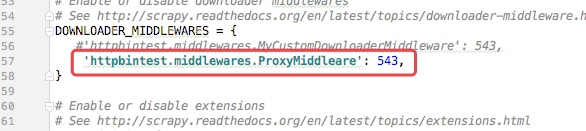
然后我们再次启动爬虫:scrapy crawl httpbin
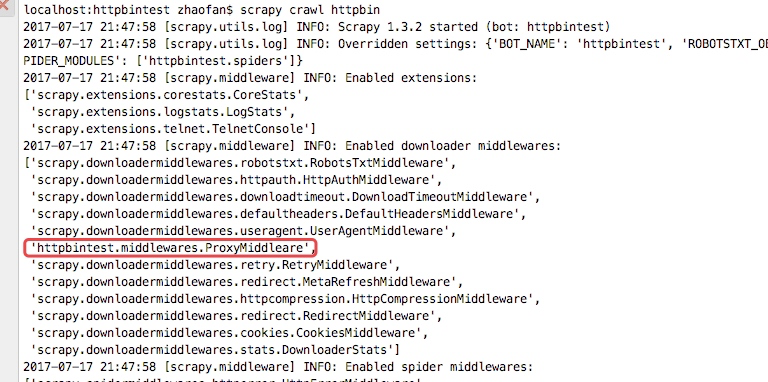
从下图的输入日志中我们可以看书我们定义的中间件已经启动,并且输入了我们打印的日志信息,并且我们查看origin的ip地址也已经成了日本的ip地址,这样我们的代理中间件成功了
详细说明
class Scrapy.downloadermiddleares.DownloaderMiddleware
process_request(request,spider)
当每个request通过下载中间件时,该方法被调用,这里有一个要求,该方法必须返回以下三种中的任意一种:None,返回一个Response对象,返回一个Request对象或raise IgnoreRequest。三种返回值的作用是不同的。
None:Scrapy将继续处理该request,执行其他的中间件的相应方法,直到合适的下载器处理函数(download handler)被调用,该request被执行(其response被下载)。
Response对象:Scrapy将不会调用任何其他的process_request()或process_exception() 方法,或相应地下载函数;其将返回该response。 已安装的中间件的 process_response() 方法则会在每个response返回时被调用。
Request对象:Scrapy则停止调用 process_request方法并重新调度返回的request。当新返回的request被执行后, 相应地中间件链将会根据下载的response被调用。
raise一个IgnoreRequest异常:则安装的下载中间件的 process_exception() 方法会被调用。如果没有任何一个方法处理该异常, 则request的errback(Request.errback)方法会被调用。如果没有代码处理抛出的异常, 则该异常被忽略且不记录。
process_response(request, response, spider)
process_response的返回值也是有三种:response对象,request对象,或者raise一个IgnoreRequest异常
如果其返回一个Response(可以与传入的response相同,也可以是全新的对象), 该response会被在链中的其他中间件的 process_response() 方法处理。
如果其返回一个 Request 对象,则中间件链停止, 返回的request会被重新调度下载。处理类似于 process_request() 返回request所做的那样。
如果其抛出一个 IgnoreRequest 异常,则调用request的errback(Request.errback)。 如果没有代码处理抛出的异常,则该异常被忽略且不记录(不同于其他异常那样)。
这里我们写一个简单的例子还是上面的项目,我们在中间件中继续添加如下代码:
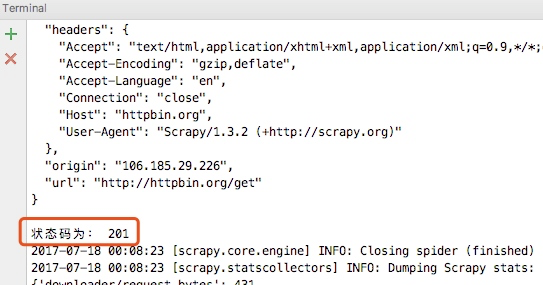
然后在spider中打印状态码:

这样当我们重新运行爬虫的时候就可以看到如下内容
process_exception(request, exception, spider)
当下载处理器(download handler)或 process_request() (下载中间件)抛出异常(包括 IgnoreRequest 异常)时,Scrapy调用 process_exception()。
process_exception() 也是返回三者中的一个: 返回 None 、 一个 Response 对象、或者一个 Request 对象。
如果其返回 None ,Scrapy将会继续处理该异常,接着调用已安装的其他中间件的 process_exception() 方法,直到所有中间件都被调用完毕,则调用默认的异常处理。
如果其返回一个 Response 对象,则已安装的中间件链的 process_response() 方法被调用。Scrapy将不会调用任何其他中间件的 process_exception() 方法。
如果其返回一个 Request 对象, 则返回的request将会被重新调用下载。这将停止中间件的 process_exception() 方法执行,就如返回一个response的那样。 这个是非常有用的,就相当于如果我们失败了可以在这里进行一次失败的重试,例如当我们访问一个网站出现因为频繁爬取被封ip就可以在这里设置增加代理继续访问,我们通过下面一个例子演示
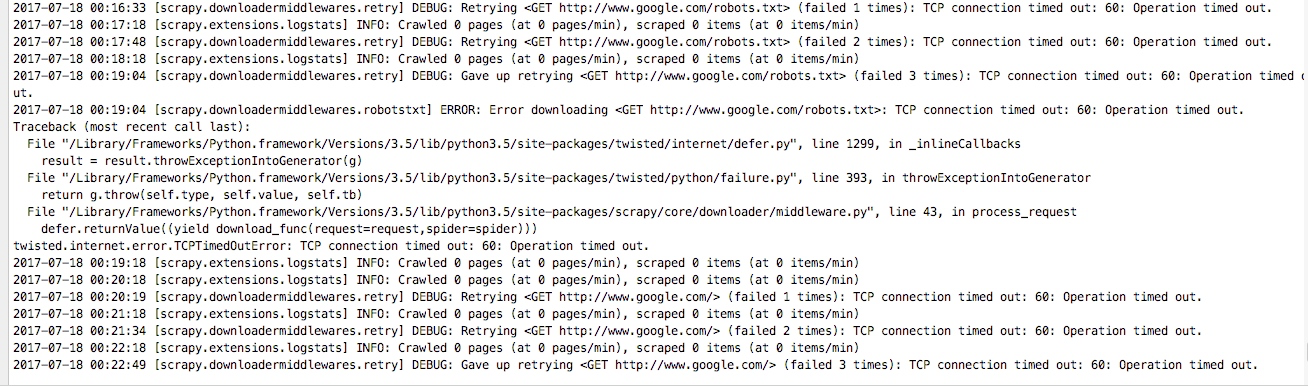
scrapy genspider google www.google.com 这里我们创建一个谷歌的爬虫,
然后启动scrapy crawl google,可以看到如下情况:
这里我们就写一个中间件,当访问失败的时候增加代理
首先我们把google.py代码进行更改,这样是白超时时间设置为10秒要不然等待太久,这个就是我们将spider里的时候的讲过的make_requests_from_url,这里我们把这个方法重写,并将等待超时时间设置为10s
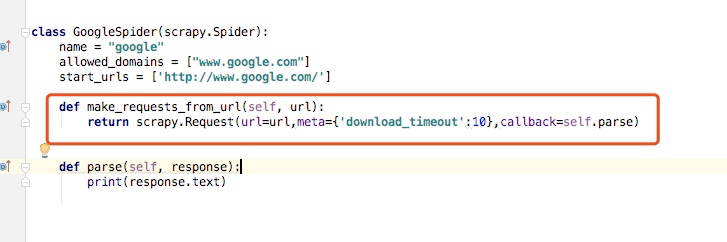
这样我重新启动爬虫:scrapy crawl google,可以看到如下:
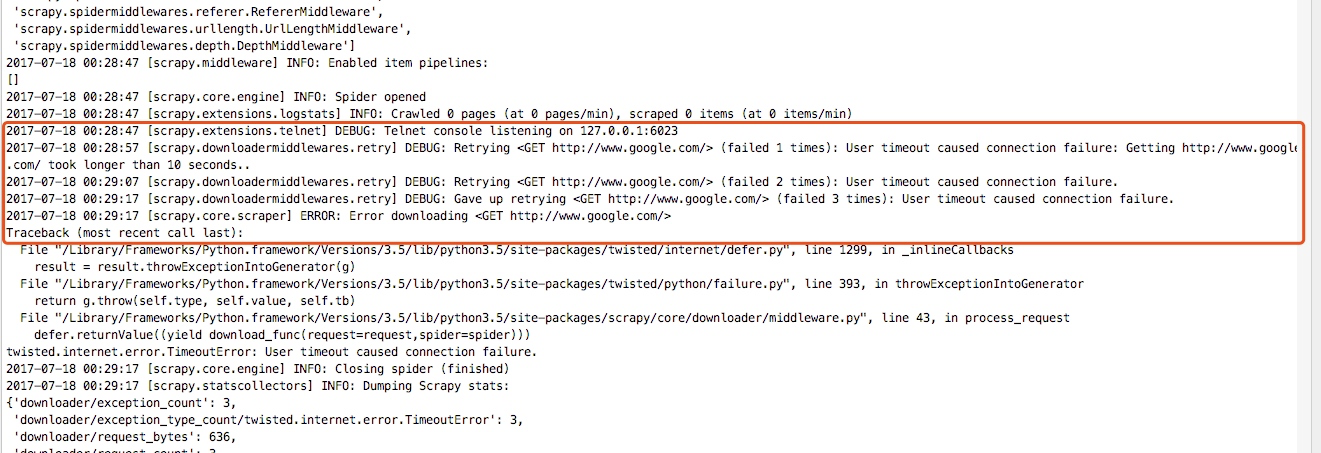
这里如果我们不想让重试,可以把重试中间件关掉:
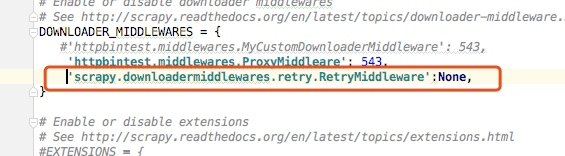
这样设置之后我们就把失败重试的中间件给关闭了,设置为None就表示关闭这个中间件,重新启动爬虫我们也可以看出没有进行重试直接报错了
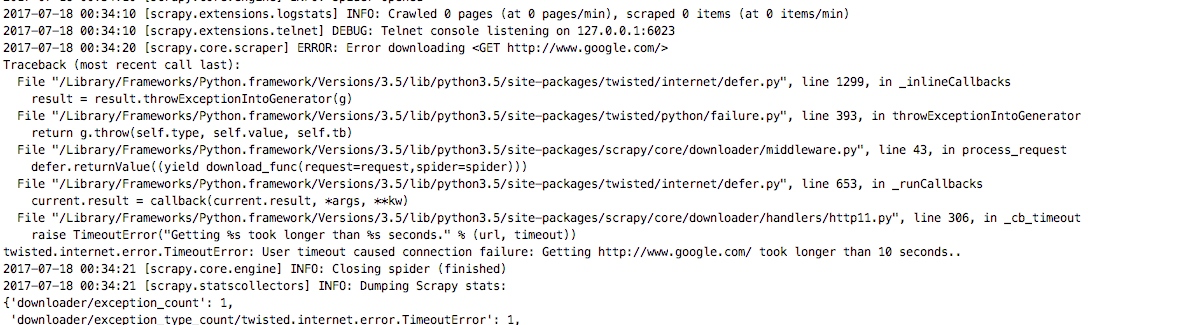
我们将代理中间件的代理改成如下,表示遇到异常的时候给请求加上代理,并返回request,这个样就会重新请求谷歌
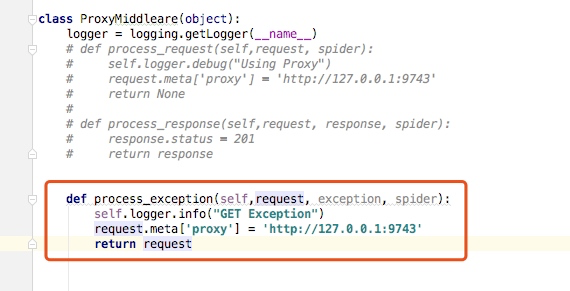
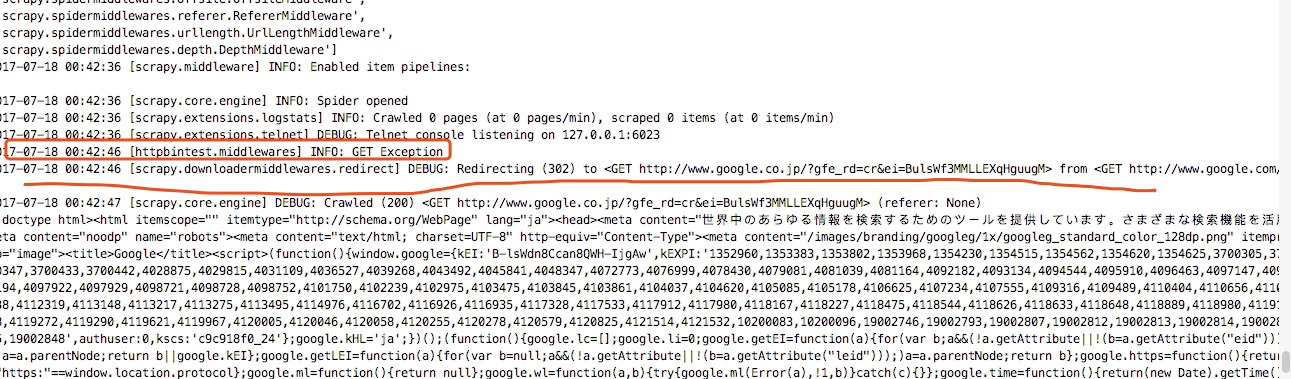
重新启动谷歌爬虫,我们可以看到,我们第一次返回我们打印的日志信息GET Exception,然后加上代理后成功访问了谷歌,这里我的代理是日本的代理节点,所以访问到的是日本的谷歌站
Python之爬虫(十九) Scrapy框架中Download Middleware用法的更多相关文章
- scrapy框架中Download Middleware用法
scrapy框架中Download Middleware用法 Downloader Middleware处理的过程主要在调度器发送requests请求的时候以及网页将response结果返回给sp ...
- Python爬虫从入门到放弃(十七)之 Scrapy框架中Download Middleware用法
这篇文章中写了常用的下载中间件的用法和例子.Downloader Middleware处理的过程主要在调度器发送requests请求的时候以及网页将response结果返回给spiders的时候,所以 ...
- Python爬虫从入门到放弃 之 Scrapy框架中Download Middleware用法
这篇文章中写了常用的下载中间件的用法和例子.Downloader Middleware处理的过程主要在调度器发送requests请求的时候以及网页将response结果返回给spiders的时候,所以 ...
- 7-----Scrapy框架中Download Middleware用法
这篇文章中写了常用的下载中间件的用法和例子.Downloader Middleware处理的过程主要在调度器发送 requests请求的时候以及网页将 response结果返回给 spiders的时候 ...
- Scrapy框架中选择器的用法【转】
Python爬虫从入门到放弃(十四)之 Scrapy框架中选择器的用法 请给作者点赞 --> 原文链接 Scrapy提取数据有自己的一套机制,被称作选择器(selectors),通过特定的Xpa ...
- scrapy框架中Item Pipeline用法
scrapy框架中item pipeline用法 当Item 在Spider中被收集之后,就会被传递到Item Pipeline中进行处理 每个item pipeline组件是实现了简单的方法的pyt ...
- scrapy框架中选择器的用法
scrapy框架中选择器的用法 Scrapy提取数据有自己的一套机制,被称作选择器(selectors),通过特定的Xpath或者CSS表达式来选择HTML文件的某个部分Xpath是专门在XML文件中 ...
- PYTHON网络爬虫与信息提取[scrapy框架应用](单元十、十一)
scrapy 常用命令 startproject 创建一个新的工程 scrapy startproject <name>[dir] genspider 创建一个爬虫 ...
- Python爬虫从入门到放弃(十六)之 Scrapy框架中Item Pipeline用法
当Item 在Spider中被收集之后,就会被传递到Item Pipeline中进行处理 每个item pipeline组件是实现了简单的方法的python类,负责接收到item并通过它执行一些行为, ...
随机推荐
- 线上排查Class、Jar加载问题的一般方法
问题背景 本问题源于<ojdbc6中OraclePreparedStatement的ArrayIndexOutOfBoundsException异常BUG-6396242>这篇博文中最后思 ...
- Java中的map集合顺序如何与添加顺序一样
一般使用map用的最多的就是hashmap,但是hashmap里面的元素是不按添加顺序的,那么除了使用hashmap外,还有什么map接口的实现类可以用呢? 这里有2个,treeMap和linkedH ...
- Arduino控制超声波检测与0.96OLED及串口显示
Arduino控制超声波检测与0.96OLED及串口显示代码使用库共享(包括超声波检测与U8glib): 使用元件: 0.96寸 12864 I2C OLED 128x64规格 超声波检测模块 湿度模 ...
- Android学习笔记.9.png格式图片
.9.png可以保证图片在合适的位置进行局部拉伸,避免了图片全局缩放造成的图片变形问题.AS提供了制作点9图片的便捷入口,并且会检查你的.9图是否有不合理的拉伸区域. 选中图片点击create 9-p ...
- [实战] Flutter 上的内存泄漏监控
一.前言 Flutter 所使用的 Dart 语言具有垃圾回收机制,有垃圾回收就避免不了会内存泄漏. 在 Android 平台上有个内存泄漏检测工具 LeakCanary, 它可以方便地在 debug ...
- 【JMeter_15】JMeter逻辑控制器__仅一次控制器<Once Only Controller>
仅一次控制器<Once Only Controller> 业务逻辑: 在每个线程内,该控制器下的内容只会被执行一遍,无论循环多少次,都只执行一遍.<嵌套在循环控制器之内时是个例外,每 ...
- linux环境下搭建Jenkins持续集成(Jenkins+git+shell+maven+tomact)
准备环境 jenkins.war包 ,jdk1.8 ,tomact , maven,git 1.Jenkins war包,下载地址https://jenkins.io/zh/download/ ...
- zip矩阵转至
list01=[1,2,3,4] list02=["a","b","c","d"] for itme in zip(li ...
- 基于领域驱动设计(DDD)超轻量级快速开发架构(二)动态linq查询的实现方式
-之动态查询,查询逻辑封装复用 基于领域驱动设计(DDD)超轻量级快速开发架构详细介绍请看 https://www.cnblogs.com/neozhu/p/13174234.html 需求 配合Ea ...
- 【论文笔记】Pyramidal Convolution: Rethinking Convolutional Neural Networks for Visual Recognition
地址:https://arxiv.org/pdf/2006.11538.pdf github:https://github.com/iduta/pyconv 目前的卷积神经网络普遍使用3×3的卷积神经 ...