全文检索Solr集成HanLP中文分词
以前发布过HanLP的Lucene插件,后来很多人跟我说其实Solr更流行(反正我是觉得既然Solr是Lucene的子项目,那么稍微改改配置就能支持Solr),于是就抽空做了个Solr插件出来,开源在Github上,欢迎改进。
HanLP中文分词solr插件支持Solr5.x,兼容Lucene5.x。

图1
快速上手
1、将hanlp-portable.jar和hanlp-solr-plugin.jar共两个jar放入${webapp}/WEB-INF/lib下
2、修改solr core的配置文件${core}/conf/schema.xml:
<fieldType name="text_cn" class="solr.TextField">
<analyzer type="index">
<tokenizer class="com.hankcs.lucene.HanLPTokenizerFactory" enableIndexMode="true"/>
</analyzer>
<analyzer type="query">
<!-- 切记不要在query中开启index模式 -->
<tokenizer class="com.hankcs.lucene.HanLPTokenizerFactory" enableIndexMode="false"/>
</analyzer>
</fieldType>
<!-- 业务系统中需要分词的字段都需要指定type为text_cn -->
<field name="my_field1" type="text_cn" indexed="true" stored="true"/>
<field name="my_field2" type="text_cn" indexed="true" stored="true"/>
Solr5中文分词器详细配置
对于新手来说,上面的两步可能太简略了,不如看看下面的step by step。本教程使用Solr5.2.1,理论上兼容solr5.x。
放置jar
将上述两个jar放到solr-5.2.1/server/solr-webapp/webapp/WEB-INF/lib目录下。如果你想自定义词典等数据,将hanlp.properties放到solr-5.2.1/server/resources,该目录也是log4j.properties等配置文件的放置位置。HanLP文档一直在说“将配置文件放到resources目录下”,指的就是这个意思。作为Java程序员,这是基本常识。
启动solr
首先在solr-5.2.1\bin目录下启动solr:
1.solr start -f
用浏览器打开http://localhost:8983/solr/#/,看到如下页面说明一切正常:
图2
创建core
在solr-5.2.1\server\solr下新建一个目录,取个名字比如叫one,将示例配置文件solr-5.2.1\server\solr\configsets\sample_techproducts_configs\conf拷贝过来,接着修改schema.xml中的默认域type,搜索
1. <fieldType name="text_general" class="solr.TextField" positionIncrementGap="100">
2. ...
3. </fieldType>
替换为
- <!-- 默认文本类型: 指定使用HanLP分词器,同时开启索引模式。
- 通过solr自带的停用词过滤器,使用"stopwords.txt"(默认空白)过滤。
- 在搜索的时候,还支持solr自带的同义词词典。-->
- <fieldType name="text_general" class="solr.TextField" positionIncrementGap="100">
- <analyzer type="index">
- <tokenizer class="com.hankcs.lucene.HanLPTokenizerFactory" enableIndexMode="true"/>
- <filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
- <!-- 取消注释可以启用索引期间的同义词词典
- <filter class="solr.SynonymFilterFactory" synonyms="index_synonyms.txt" ignoreCase="true" expand="false"/>
- -->
- <filter class="solr.LowerCaseFilterFactory"/>
- </analyzer>
- <analyzer type="query">
- <tokenizer class="com.hankcs.lucene.HanLPTokenizerFactory" enableIndexMode="true"/>
- <filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
- <filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
- <filter class="solr.LowerCaseFilterFactory"/>
- </analyzer>
- </fieldType>
意思是默认文本字段类型启用HanLP分词器,text_general还开启了solr默认的各种filter。
solr允许为不同的字段指定不同的分词器,由于绝大部分字段都是text_general类型的,可以说这种做法比较适合新手。如果你是solr老手的话,你可能会更喜欢单独为不同的字段指定不同的分词器及其他配置。如果你的业务系统中有其他字段,比如location,summary之类,也需要一一指定其type="text_general"。切记,否则这些字段仍旧是solr默认分词器,会造成这些字段“搜索不到”。
另外,切记不要在query中开启indexMode,否则会影响PhaseQuery。indexMode只需在index中开启一遍即可,要不然它怎么叫indexMode呢。
如果你不需要solr提供的停用词、同义词等filter,如下配置可能更适合你:
1. <fieldType name="text_cn" class="solr.TextField">
2. <analyzer type="index">
3. <tokenizer class="com.hankcs.lucene.HanLPTokenizerFactory" enableIndexMode="true"/>
4. </analyzer>
5. <analyzer type="query">
6. <!-- 切记不要在query中开启index模式 -->
7. <tokenizer class="com.hankcs.lucene.HanLPTokenizerFactory" enableIndexMode="false"/>
8. </analyzer>
9. </fieldType>
10. <!-- 业务系统中需要分词的字段都需要指定type为text_cn -->
11. <field name="my_field1" type="text_cn" indexed="true" stored="true"/>
12. <field name="my_field2" type="text_cn" indexed="true" stored="true"/>
完成了之后在solr的管理界面导入这个core one:

图3
接着就能在下拉列表中看到这个core了:

图4
上传测试文档
修改好了,就可以拿一些测试文档来试试效果了。hanlp-solr-plugin代码库中的src/test/resources下有个测试文档集合documents.csv,其内容如下:
- id,title
- 1,你好世界
- 2,商品和服务
- 3,和服的价格是每镑15便士
- 4,服务大众
- 5,hanlp工作正常
代表着id从1到5共五个文档,接下来复制solr-5.2.1\example\exampledocs下的上传工具post.jar到resources目录,利用如下命令行将数据导入:
- java -Dc=one -Dtype=application/csv -jar post.jar *.csv
Windows用户的话直接双击该目录下的upload.cmd即可,Linux用户运行upload.sh。
正常情况下输出如下结果:
- SimplePostTool version 5.0.0
- Posting files to [base] url http://localhost:8983/solr/one/update using content-
- type application/csv...
- POSTing file documents.csv to [base]
- 1 files indexed.
- COMMITting Solr index changes to http://localhost:8983/solr/one/update...
- Time spent: 0:00:00.059
- 请按任意键继续. . .
同时刷新一下core one的Overview,的确看到了5篇文档:
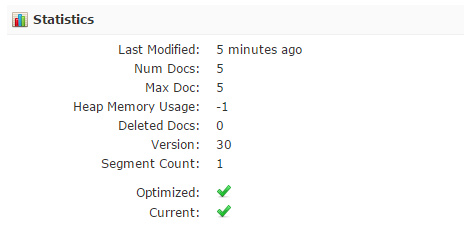
图5
搜索文档
是时候看看HanLP分词的效果了,点击左侧面板的Query,输入“和服”试试:
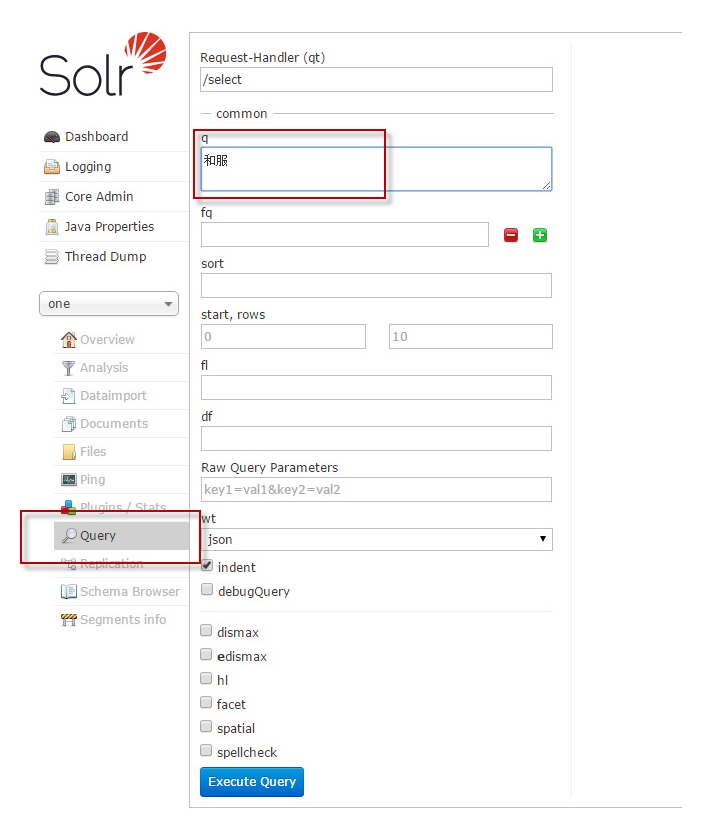
图6
发现精确地查到了“和服的价格是每镑15便士”,而不是“商品和服务”这种错误文档:
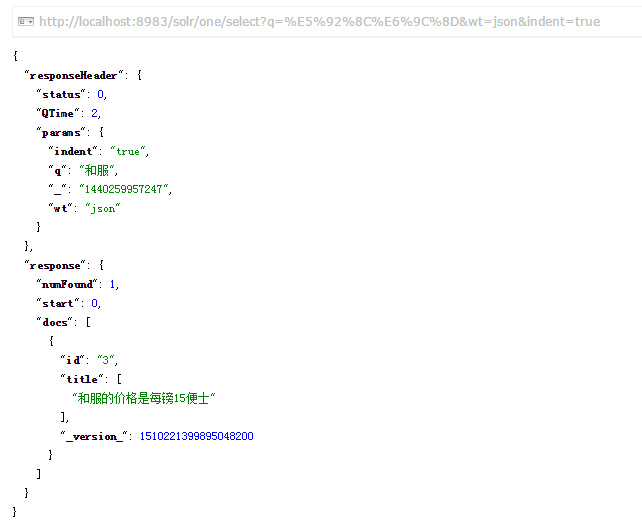
图7
这说明HanLP工作良好。
要知道,不少中文分词器眉毛胡子一把抓地命中“商品和服务”这种错误文档,降低了查准率,拉低了用户体验,跟原始的MySQL LIKE有何区别?
索引模式的功能
索引模式可以对长词进行全切分,得到其中蕴含的所有词汇。比如“中医药大学附属医院”在HanLP索引分词模式下的切分结果为:
- 中0 医1 药2 大3 学4 附5 属6 医7 院8
- [0:3 1] 中医药/n
- [0:2 1] 中医/n
- [1:3 1] 医药/n
- [3:5 1] 大学/n
- [5:9 1] 附属医院/nt
- [5:7 1] 附属/vn
- [7:9 1] 医院/n
开启indexMode后,无论用户搜索“中医”“中医药”还是“医药”,都会搜索到“中医药大学附属医院”:
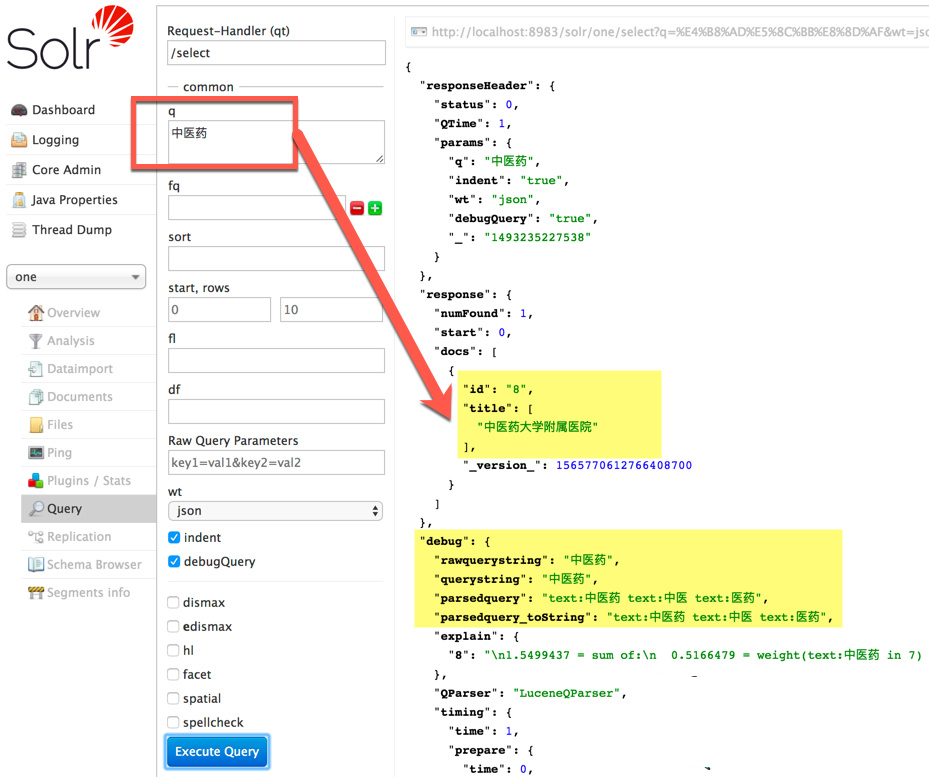
图8
高级配置
目前本插件支持如下基于schema.xml的配置:
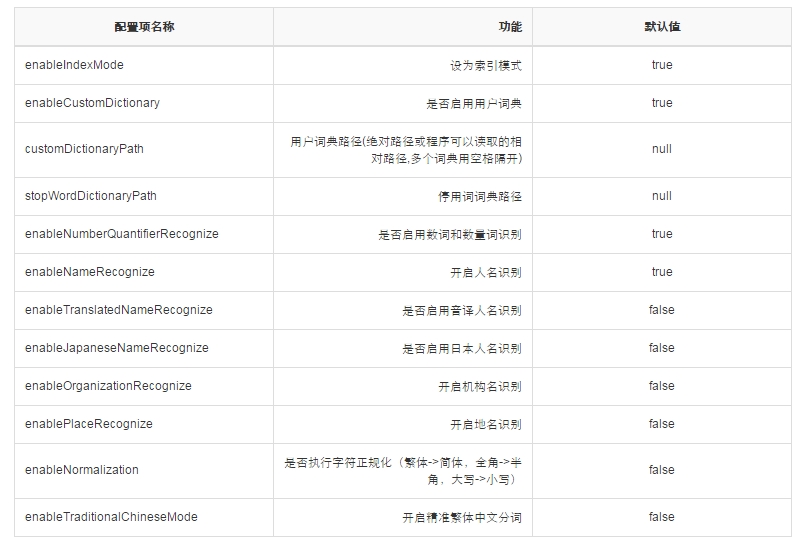
图9
对于更高级的配置,HanLP分词器主要通过class path下的hanlp.properties进行配置,请阅读HanLP自然语言处理包文档以了解更多相关配置,如:
1.停用词
2.用户词典
3.词性标注
4.……
代码调用
在Query改写的时候,可以利用HanLPAnalyzer分词结果中的词性等属性,如
- String text = "中华人民共和国很辽阔";
- for (int i = 0; i < text.length(); ++i)
- {
- System.out.print(text.charAt(i) + "" + i + " ");
- }
- System.out.println();
- Analyzer analyzer = new HanLPAnalyzer();
- TokenStream tokenStream = analyzer.tokenStream("field", text);
- tokenStream.reset();
- while (tokenStream.incrementToken())
- {
- CharTermAttribute attribute = tokenStream.getAttribute(CharTermAttribute.class);
- // 偏移量
- OffsetAttribute offsetAtt = tokenStream.getAttribute(OffsetAttribute.class);
- // 距离
- PositionIncrementAttribute positionAttr = kenStream.getAttribute(PositionIncrementAttribute.class);
- // 词性
- TypeAttribute typeAttr = tokenStream.getAttribute(TypeAttribute.class);
- System.out.printf("[%d:%d %d] %s/%s\n", offsetAtt.startOffset(), offsetAtt.endOffset(), positionAttr.getPositionIncrement(), attribute, typeAttr.type());
- }
在另一些场景,支持以自定义的分词器(比如开启了命名实体识别的分词器、繁体中文分词器、CRF分词器等)构造HanLPTokenizer,比如:
- tokenizer = new HanLPTokenizer(HanLP.newSegment()
- .enableJapaneseNameRecognize(true)
- .enableIndexMode(true), null, false);
- tokenizer.setReader(new StringReader("林志玲亮相网友:确定不是波多野结衣?"));
- ...
反馈
技术问题请在Github上发issue ,大家一起讨论,也方便集中管理。博客留言、微博私信、邮件不受理任何HanLP相关的问题,谢谢合作!
反馈问题的时候请一定附上版本号、触发代码、输入输出,否则无法处理。
版权
Apache License Version 2.0
转载子码农场
全文检索Solr集成HanLP中文分词的更多相关文章
- 全文检索Solr集成HanLP中文分词【转】
以前发布过HanLP的Lucene插件,后来很多人跟我说其实Solr更流行(反正我是觉得既然Solr是Lucene的子项目,那么稍微改改配置就能支持Solr),于是就抽空做了个Solr插件出来,开源在 ...
- Solr集成IK中文分词器
1.将IKAnalyzer-2012-4x.jar拷贝到example\solr-webapp\webapp\WEB-INF\lib下: 2.在schema.xml文件中添加fieldType: &l ...
- 全文检索引擎Solr系列——整合中文分词组件mmseg4j
默认Solr提供的分词组件对中文的支持是不友好的,比如:“VIM比作是编辑器之神”这个句子在索引的的时候,选择FieldType为”text_general”作为分词依据时,分词效果是: 它把每一个词 ...
- solr服务中集成IKAnalyzer中文分词器、集成dataimportHandler插件
昨天已经在Tomcat容器中成功的部署了solr全文检索引擎系统的服务:今天来分享一下solr服务在海量数据的网站中是如何实现数据的检索. 在solr服务中集成IKAnalyzer中文分词器的步骤: ...
- Solr学习笔记之2、集成IK中文分词器
Solr学习笔记之2.集成IK中文分词器 一.下载IK中文分词器 IK中文分词器 此文IK版本:IK Analyer 2012-FF hotfix 1 完整分发包 二.在Solr中集成IK中文分词器 ...
- 在Solr中配置中文分词IKAnalyzer
李克华 云计算高级群: 292870151 交流:Hadoop.NoSQL.分布式.lucene.solr.nutch 在Solr中配置中文分词IKAnalyzer 1.在配置文件schema.xml ...
- Elasticsearch:hanlp 中文分词器
HanLP 中文分词器是一个开源的分词器,是专为Elasticsearch而设计的.它是基于HanLP,并提供了HanLP中大部分的分词方式.它的源码位于: https://github.com/Ke ...
- 全文检索引擎Solr系列——整合中文分词组件IKAnalyzer
IK Analyzer是一款结合了词典和文法分析算法的中文分词组件,基于字符串匹配,支持用户词典扩展定义,支持细粒度和智能切分,比如: 张三说的确实在理 智能分词的结果是: 张三 | 说的 | 确实 ...
- HanLP中文分词Lucene插件
基于HanLP,支持包括Solr(7.x)在内的任何基于Lucene(7.x)的系统. Maven <dependency> <groupId>com.hankcs.nlp&l ...
随机推荐
- count函数详细介绍
select count(字段) from 表名; #得到字段中is not null的行数 select count(*)from 表名; #任何列,只要有一个非null就会被统计上.全为null( ...
- ES6 class的继承-学习笔记
1.简介 Class 可以通过extends关键字实现继承,这比 ES5 的通过修改原型链实现继承,要清晰和方便很多. 子类必须在constructor方法中调用super方法,否则新建实例时会报错. ...
- RIP路由协议(一)
实验要求:使用RIPv2配置路由器,使路由器能接收到所有的路由条目 拓扑如下: 配置如下: R1enable 进入特权模式configure terminal 进入全局模式interface s0/0 ...
- Ubuntu创建新用户并设置权限
打开终端开启root账户 sudo passwd -u root 设置root密码,输入两次 sudo passwd root 切换root账号 su - 或 su root 退出root账户使用ex ...
- 2.23 js处理日历控件(修改readonly属性)
2.23 js处理日历控件(修改readonly属性) 前言 日历控件是web网站上经常会遇到的一个场景,有些输入框是可以直接输入日期的,有些不能,以我们经常抢票的12306网站为例,详细讲解如 ...
- Android全局可调试(ro.debuggable = 1)的一种另类改法
网上流传比较多的,是重打包boot.img.读aosp的init进程源码,发现通过patch init进程也可以实现相同目的. 首先看一下init进程对ro只读属性的检查: /* property_s ...
- Unity射线检测的用法总结
RayCast 射线检测 本文提供全流程,中文翻译. Chinar 坚持将简单的生活方式,带给世人!(拥有更好的阅读体验 -- 高分辨率用户请根据需求调整网页缩放比例) Chinar -- 心分享.心 ...
- 20155208 2006-2007-2 《Java程序设计》第1周学习总结
20155208徐子涵 2016-2017-2 <Java程序设计>第1周学习总结 教材学习内容总结 浏览教材 每章提出自己存在的问题 chapter1:JDK和JRE的区别体现在什么地方 ...
- acm 2044
////////////////////////////////////////////////////////////////////////////////#include<iostream ...
- (15)模型层-什么是ORM
ORM是什么 1.MVC或者MTV框架中包括一个重要的部分,就是ORM,它实现了数据模型与数据库的解耦,即数据模型的设计不需要依赖于特定的数据库,通过简单的配置就可以轻松更换数据库,这极大的减轻了开发 ...