使用scrapy爬虫,爬取今日头条搜索吉林疫苗新闻(scrapy+selenium+PhantomJS)
这一阵子吉林疫苗案,备受大家关注,索性使用爬虫来爬取今日头条搜索吉林疫苗的新闻
依然使用三件套(scrapy+selenium+PhantomJS)来爬取新闻
以下是搜索页面,得到吉林疫苗的搜索信息,里面包含了新闻信息和视频信息
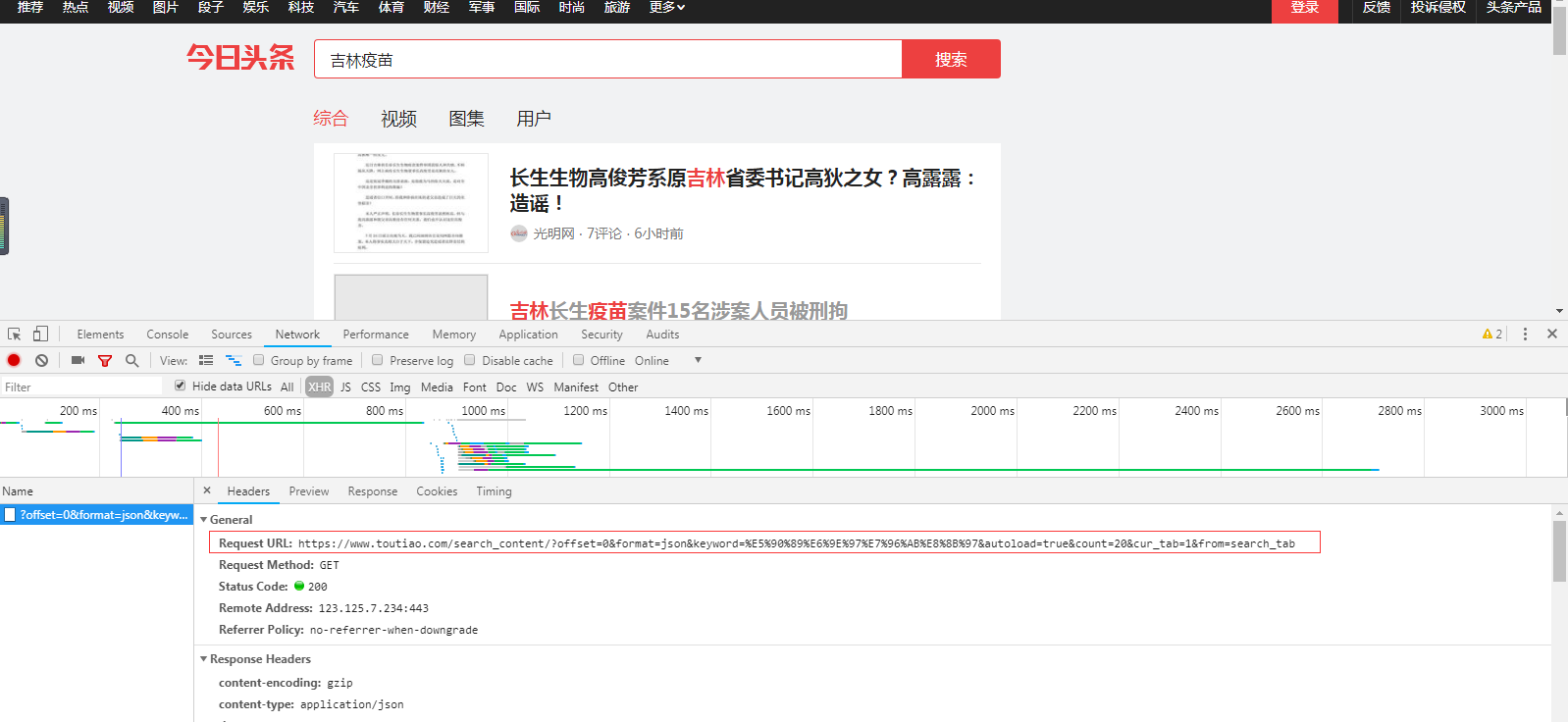
通过F12中network得到了接口url信息:https://www.toutiao.com/search_content/?offset=0&format=json&keyword=%E5%90%89%E6%9E%97%E7%96%AB%E8%8B%97&autoload=true&count=20&cur_tab=1&from=search_tab
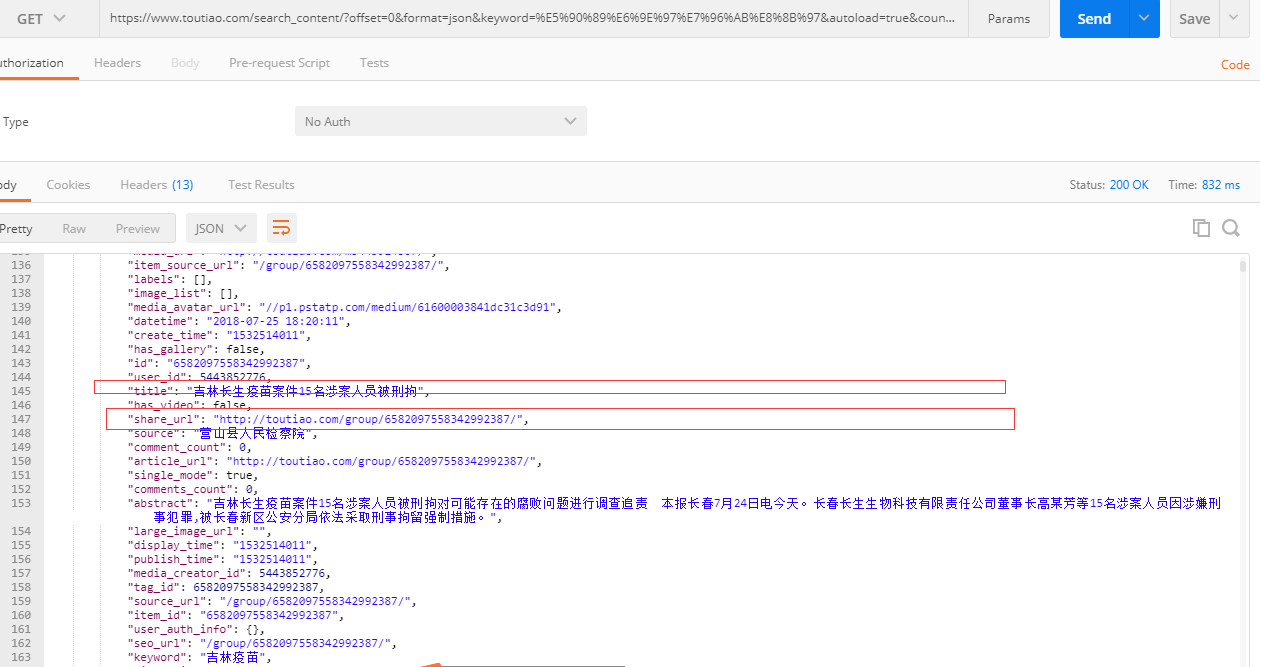
在Postman里面访问接口信息得到json信息(信息里面包含了文章的标题和链接)
基于这些信息来开发爬虫核心代码
# -*- coding: utf-8 -*-
import scrapy
from selenium import webdriver
import time
import json
from toutiao.items import ToutiaoItem class ToutiaoSerachSpider(scrapy.Spider):
name = 'toutiao_serach'
allowed_domains = ['toutiao.com']
###接口信息,这里为了方便把 &keyword= 挪到了最后边
start_urls = ['https://www.toutiao.com/search_content/?offset=0&format=json&autoload=true&count=20&cur_tab=1&from=search_tab&keyword='] def parse(self, response):
new_key_word=response.url+'吉林疫苗'
yield scrapy.Request(new_key_word,callback=self.main_parse) def main_parse(self,response):
search_content_data=json.loads(response.text)
for aa in search_content_data['data']:
if 'open_url' in aa.keys() and 'play_effective_count'not in aa.keys(): ### 去除搜索后得到的综合里面 保留文章信息类型,去除视频信息类型
yield scrapy.Request(aa['article_url'],callback=self.content_parse) def content_parse(self,response): driver = webdriver.PhantomJS()
driver.get(response.url)
time.sleep(3)
title = driver.find_element_by_class_name('article-title').text
content=driver.find_element_by_class_name('article-content').text item=ToutiaoItem()
item['title'] =title
item['content']=content yield item
最后得到新闻信息

使用scrapy爬虫,爬取今日头条搜索吉林疫苗新闻(scrapy+selenium+PhantomJS)的更多相关文章
- 使用scrapy爬虫,爬取今日头条首页推荐新闻(scrapy+selenium+PhantomJS)
爬取今日头条https://www.toutiao.com/首页推荐的新闻,打开网址得到如下界面 查看源代码你会发现 全是js代码,说明今日头条的内容是通过js动态生成的. 用火狐浏览器F12查看得知 ...
- Python 爬虫爬取今日头条街拍上的图片
# 今日头条--街拍 import requests from urllib.parse import urlencode import os from hashlib import md5 from ...
- PYTHON 爬虫笔记九:利用Ajax+正则表达式+BeautifulSoup爬取今日头条街拍图集(实战项目二)
利用Ajax+正则表达式+BeautifulSoup爬取今日头条街拍图集 目标站点分析 今日头条这类的网站制作,从数据形式,CSS样式都是通过数据接口的样式来决定的,所以它的抓取方法和其他网页的抓取方 ...
- 爬虫七之分析Ajax请求并爬取今日头条
爬取今日头条图片 这里只讨论出现的一些问题,代码在最下面github链接里. 首先,今日头条取消了"图集"这一选项,因此对于爬虫来说效率降低了很多: 在所有代码都完成后,也许是爬取 ...
- Python3从零开始爬取今日头条的新闻【一、开发环境搭建】
Python3从零开始爬取今日头条的新闻[一.开发环境搭建] Python3从零开始爬取今日头条的新闻[二.首页热点新闻抓取] Python3从零开始爬取今日头条的新闻[三.滚动到底自动加载] Pyt ...
- Python3从零开始爬取今日头条的新闻【四、模拟点击切换tab标签获取内容】
Python3从零开始爬取今日头条的新闻[一.开发环境搭建] Python3从零开始爬取今日头条的新闻[二.首页热点新闻抓取] Python3从零开始爬取今日头条的新闻[三.滚动到底自动加载] Pyt ...
- Python3从零开始爬取今日头条的新闻【三、滚动到底自动加载】
Python3从零开始爬取今日头条的新闻[一.开发环境搭建] Python3从零开始爬取今日头条的新闻[二.首页热点新闻抓取] Python3从零开始爬取今日头条的新闻[三.滚动到底自动加载] Pyt ...
- Python3从零开始爬取今日头条的新闻【二、首页热点新闻抓取】
Python3从零开始爬取今日头条的新闻[一.开发环境搭建] Python3从零开始爬取今日头条的新闻[二.首页热点新闻抓取] Python3从零开始爬取今日头条的新闻[三.滚动到底自动加载] Pyt ...
- 用Ajax爬取今日头条图片集
Ajax原理 在用requests抓取页面时,得到的结果可能和浏览器中看到的不一样:在浏览器中可以正常显示的页面数据,但用requests得到的结果并没有.这是因为requests获取的都是原始 ...
随机推荐
- USB虚拟串口通信
https://blog.csdn.net/errorhai/article/details/85333914
- STL用法整理
百度百科 STL是Standard Template Library的简称,中文名标准模板库,惠普实验室开发的一系列软件的统称.从根本上说,STL是一些“容器”的集合,这些“容器”有list,vect ...
- 一、Subversion服务
Subversion是优秀的版本控制工具简称SVN,搭建SVN服务器,通过TortoiseSVN进行版本管理. 一.管理SVN服务的VisualSVN和TSVN两种Visual Studio扩展工具 ...
- Ubuntu16设置Redis开机自启动
Ubuntu16设置Redis开机自启动 Ubuntu16设置Redis开机自启动 设置条件: -Ubuntu16.04 -Redis-4.0.11 在redis目录下找到 utils/redi ...
- (简单)华为Nova青春 WAS-AL00的USB调试模式在哪里开启的流程
就在我们使用Pc接通安卓手机的时候,如果手机没有开启usb开发者调试模式,Pc则无办法成功检测到我们的手机,在一些情况下,我们使用的一些功能较强的app好比之前我们使用的一个app引号精灵,老版本就需 ...
- 【THUSC2017】【LOJ2979】换桌 线段树 网络流
题目大意 有 \(n\) 个圆形的桌子排成一排,每个桌子有 \(m\) 个座位. 最开始每个位置上都有一个人.现在每个人都要重新选择一个座位,第 \(i\) 桌的第 \(j\) 个人的新座位只能在第 ...
- Codeforces 1093D Beautiful Graph(二分图染色+计数)
题目链接:Beautiful Graph 题意:给定一张无向无权图,每个顶点可以赋值1,2,3,现要求相邻节点一奇一偶,求符合要求的图的个数. 题解:由于一奇一偶,需二分图判定,染色.判定失败,直接输 ...
- cenos7上部署python3环境以及mysqlconnector2.1.5
本机的python2不要管他,因为可能有程序依赖目前的python2环境,比如yum!!!!! 一.安装python3依赖环境: yum -y install zlib-devel bzip2-dev ...
- 常用Hadoop命令(bin)
**** bin 是二进制文件的意思,sbin....据说是superbin(管理员的bin) HDFS命令 某个文件的blocks信息 hadoop fsck /user/xx -files -bl ...
- Java使用POI解析Excel表格
概述 Excel表格是常用的数据存储工具,项目中经常会遇到导入Excel和导出Excel的功能. 常见的Excel格式有xls和xlsx.07版本以后主要以基于XML的压缩格式作为默认文件格式xlsx ...