【原创】大数据基础之Marathon(1)简介、安装、使用
marathon 1.6.322

官方:https://mesosphere.github.io/marathon/
一 简介
Marathon is a production-grade container orchestration platform for Mesosphere’s Datacenter Operating System (DC/OS) and Apache Mesos.\
marathon是一个DC/OS和mesos上的容器编排平台;
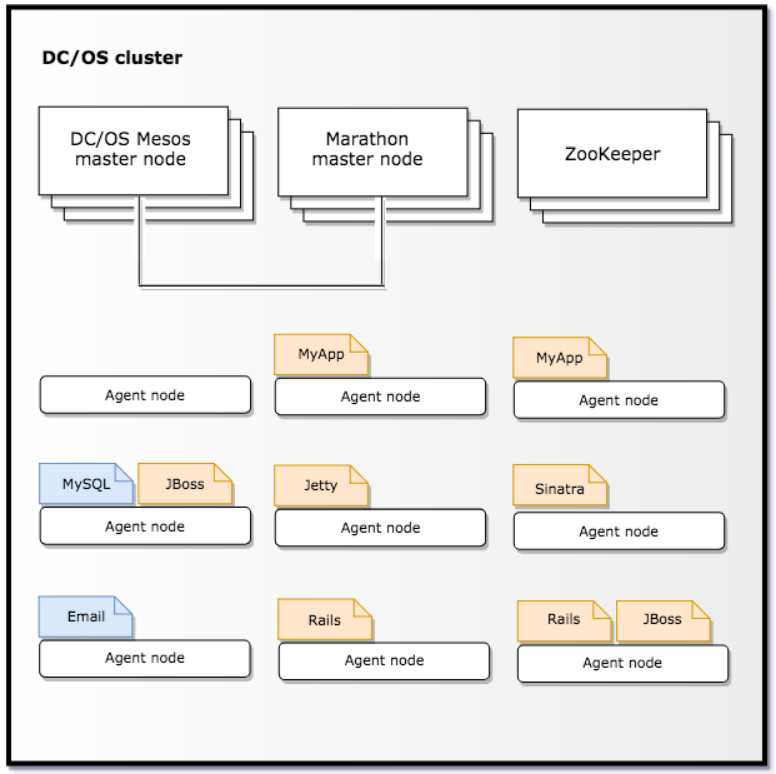
Features
- High Availability. Marathon runs as an active/passive cluster with leader election for 100% uptime.
- Multiple container runtimes. Marathon has first-class support for both Mesos containers (using cgroups) and Docker.
- Stateful apps. Marathon can bind persistent storage volumes to your application. You can run databases like MySQL and Postgres, and have storage accounted for by Mesos.
- Beautiful and powerful UI.
- Constraints. These allow to e.g. place only one instance of an application per rack, node, etc.
- Service Discovery & Load Balancing. Several methods available.
- Health Checks. Evaluate your application’s health using HTTP or TCP checks.
- Event Subscription. Supply an HTTP endpoint to receive notifications - for example to integrate with an external load balancer.
- Metrics. Query them at /metrics in JSON format or push them to systems like graphite, statsd and Datadog.
- Complete REST API for easy integration and scriptability.
特点:高可用、支持多种容器运行时环境、支持状态应用、UI、支持部署限制、服务发现&负载均衡、健康检查、事件订阅、日志收集、REST API;
DC/OS features
Running on DC/OS, Marathon gains the following additional features:
- Virtual IP routing. Allocate a dedicated, virtual address to your app. Your app is now reachable anywhere in the cluster, wherever it might be scheduled. Load balancing and rerouting around failures are done automatically.
- Authorization (DC/OS Enterprise Edition only). True multitenancy with each user or group having access to their own applications and groups.
在DC/OS上还提供虚ip和认证;
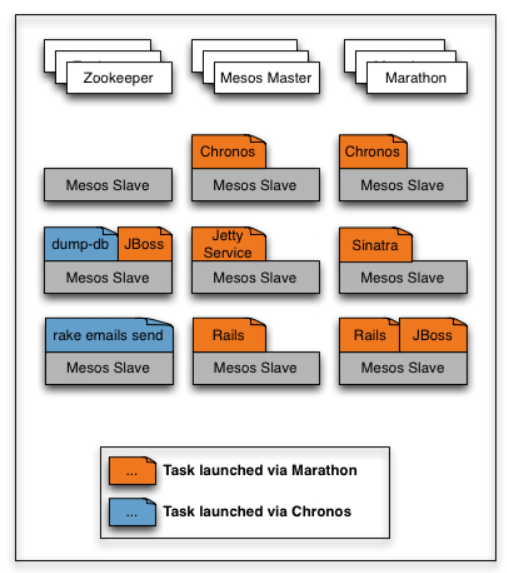
二 安装
1 官方tar包安装
$ curl -O https://downloads.mesosphere.com/marathon/releases/1.6.322/marathon-1.6.322-2bf46b341.tgz
$ tar xzf marathon-1.6.322-2bf46b341.tgz
$ cd marathon-1.6.322-2bf46b341
$ ls bin
backup backup.bat marathon marathon.bat restore restore.bat
启动
$ ./bin/mathon --master zk://$zk1:2181,$zk2:2181/mesos --zk zk://$zk1:2181,$zk2:2181/marathon --http_port 8090
默认的8080很容易冲突
2 官方yum安装
# rpm -ivh http://repos.mesosphere.com/el/7/noarch/RPMS/mesosphere-el-repo-7-1.noarch.rpm
# yum install marathon
3 离线安装
# rpm -ivh http://repos.mesosphere.com/el/7/noarch/RPMS/mesosphere-el-repo-7-1.noarch.rpm
# yum install --downloadonly --downloaddir=/path/to/rpm/marathon marathon
# ls -l /path/to/rpm/marathon
total 75276
-rw-r--r-- 1 root root 77071702 Jan 29 07:41 marathon-1.7.189-0.1.20190125223314.el7.noarch.rpm# rpm -ivh marathon-1.7.189-0.1.20190125223314.el7.noarch.rpm
安装目录
# ls /usr/share/marathon/bin
backup backup.bat marathon marathon.bat restore restore.bat
修改配置
# vi /etc/default/marathon
MARATHON_MASTER=zk://$zk1:2181,$zk2:2181/mesos
MARATHON_ZK=zk://$zk1:2181,$zk2:2181/marathon
MARATHON_HTTP_PORT=8090
启动
# service marathon start
or
# systemctl start marathon
开机启动
# systemctl enable marathon
查看状态
# service marathon status
or
# systemctl status marathon
如果有报错查看日志
# journalctl -u marathon -r
三 使用
http接口
访问 http://$marathon_server:8090
api接口
$ curl http://$marathon_server:8090/v2/apps
添加app
# curl -X POST http://$marathon_ip:8080/v2/apps -d@/path/to/app.json -H 'Content-type:application/json'
查看app
# curl http://$marathon_ip:8080/v2/apps/$app_id
删除app
# curl -X DELETE http://$marathon_ip:8080/v2/apps/$app_id
重启app
# curl -XPOST http://$marathon_ip:8080/v2/apps/$app_id/restart
具体参考:http://mesosphere.github.io/marathon/api-console/index.html
参考:https://mesosphere.github.io/marathon/docs/
【原创】大数据基础之Marathon(1)简介、安装、使用的更多相关文章
- 【原创】大数据基础之Marathon(2)marathon-lb
marathon-lb 官方:https://github.com/mesosphere/marathon-lb 一 简介 Marathon load balancer (Marathon-LB) i ...
- 大数据基础环境--jdk1.8环境安装部署
1.环境说明 1.1.机器配置说明 本次集群环境为三台linux系统机器,具体信息如下: 主机名称 IP地址 操作系统 hadoop1 10.0.0.20 CentOS Linux release 7 ...
- 【原创】大数据基础之Zookeeper(2)源代码解析
核心枚举 public enum ServerState { LOOKING, FOLLOWING, LEADING, OBSERVING; } zookeeper服务器状态:刚启动LOOKING,f ...
- CentOS6安装各种大数据软件 第八章:Hive安装和配置
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- 大数据应用日志采集之Scribe 安装配置指南
大数据应用日志采集之Scribe 安装配置指南 大数据应用日志采集之Scribe 安装配置指南 1.概述 Scribe是Facebook开源的日志收集系统,在Facebook内部已经得到大量的应用.它 ...
- 【原创】大数据基础之Impala(1)简介、安装、使用
impala2.12 官方:http://impala.apache.org/ 一 简介 Apache Impala is the open source, native analytic datab ...
- 【原创】大数据基础之Benchmark(2)TPC-DS
tpc 官方:http://www.tpc.org/ 一 简介 The TPC is a non-profit corporation founded to define transaction pr ...
- 【原创】大数据基础之词频统计Word Count
对文件进行词频统计,是一个大数据领域的hello word级别的应用,来看下实现有多简单: 1 Linux单机处理 egrep -o "\b[[:alpha:]]+\b" test ...
- 大数据基础知识:分布式计算、服务器集群[zz]
大数据中的数据量非常巨大,达到了PB级别.而且这庞大的数据之中,不仅仅包括结构化数据(如数字.符号等数据),还包括非结构化数据(如文本.图像.声音.视频等数据).这使得大数据的存储,管理和处理很难利用 ...
随机推荐
- 最速下降方法和Newton方法
目录 最速下降方法 Euclid范数和二次范数 采用\(\ell_1\)-范数的最速下降方向 Newton 方法 Newton 步径 二阶近似的最优解 线性化最优性条件的解 Newton 步径的仿射不 ...
- PS调出清新风格社区街拍照片
原图: 首先呢,我们还是先看一下在直方图,但是呢,你会发现,这张照片的直方图毫无特色. 简直是标准得不能再标准的直方图了.所以各位那我们就跳过这步吧.你要真跳过这步你就完了.直方图还有三个儿子啊,通道 ...
- Windows 虚拟机 忘记密码的处理
说明 经过验证 没法用这种方式处理 之前的系统够可以 2016的方法 稍后在写一个. 1. 修改虚拟机的配置界面: 2. 增加windows的安装盘 作为启动盘 3 bios 里面设置CD启动 比较简 ...
- Gradle打jar包命令
- Callable,Future和FutureTask详解
1.Callable和Runnable 看Callable接口: public interface Callable<V> { /** * Computes a result, or th ...
- nginx之安装、多虚拟主机、反向代理和负载均衡
一.web服务器与web框架 1.web服务器简介 Web 网络服务是一种被动访问的服务程序,即只有接收到互联网中其他主机发出的请求后才会响应,最终用于提供服务程序的Web服务器会通过 HTTP(超文 ...
- 【Spring】Spring bean的实例化
Spring实现HelloWord 前提: 1.已经在工程中定义了Spring配置文件beans.xml 2.写好了一个测试类HelloWorld,里面有方法getMessage()用于输出" ...
- RazorEngine
目标 使用razorengine编译cshtml页面生静态html 制作一个vs2017的插件,实现右击cshtml文件时,编译该文件. 环境 razorengine4.5 / netframewor ...
- JDK动态代理(Proxy)的两种实现方式
JDK自带的Proxy动态代理两种实现方式 前提条件:JDK Proxy必须实现对象接口 so,创建一个接口文件,一个实现接口对象,一个动态代理文件 接口文件:TargetInterface.java ...
- 使用item来封装数据:
一.item和field类: 1.使用Item类: 创建了类Bookitem,然后就可以使用: 2.item_pipeline: 我们可以使用item_pipeline对爬取的数据进行处理. 步骤: ...