【论文笔记】Recommendations as Treatments: Debiasing Learning and Evaluation
Recommendations as Treatments: Debiasing Learning and Evaluation
Authors: Tobias Schnabel, Adith Swaminathan, Ashudeep Singh, Navin Chandak, Thorsten Joachims
ICML’16 Cornell University
0. 总结
本文提出了基于IPS的评测指标和模型训练方法,并提出了两种倾向性评分的估计方法。收集并公开了Coat数据集,在半合成数据集和无偏数据集上,验证了评测指标对Propensity score估计的鲁棒性和IPS-MF的性能优越性。
1.研究目标
去除选择偏差(selection-bias)对模型性能评测(evaluation)和模型训练(training)带来的不利影响。
2.问题背景
推荐系统中的选择偏差(selection bias)可能有两个来源:首先,用户更可能跟自己感兴趣的物品发生交互,不感兴趣的物品更可能没有交互记录;第二,推荐系统在给出推荐列表时也会倾向于给用户推荐符合用户兴趣的产品。
3. IPS评价指标
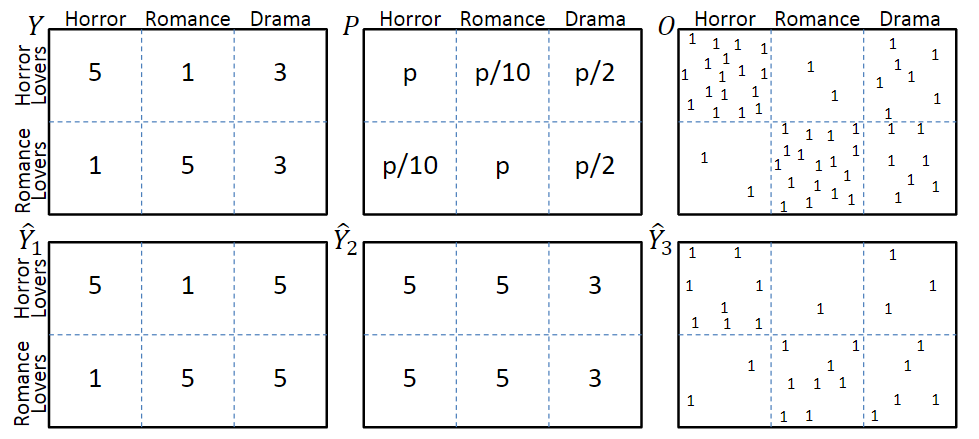
图一
考虑图一中的模型,图中第一行分别表示真实评分Y、曝光概率P和曝光分布O,其中评分越低的交互,观测到的概率也就越低。第二行\(\hat{Y}_1\)和\(\hat{Y}_2\)分别表示两种不同的预测结果,\(\hat{Y}_3\)表示是否发生了交互。
3.1 任务1:评分预测准确率评价
在理想情况下,即所有评分都被观测到时,评价指标为
\]
但在存在selection bias的场景下,评价指标会变为
\]
从喜恶判断的角度,\(\hat{Y}_1\)明显优于\(\hat{Y}_2\);但是从评价指标上看,由于\(\hat{Y}_2\)中预测错误的那些交互很少被观测到,因此,\(\hat{Y}_2\)会优于\(\hat{Y}_1\)。
3.2 推荐质量评价
评价推荐结果的质量,也就是在回答一个反事实问题:如果用户与推荐列表中的物品发生交互,而不是实际上的交互历史,用户的体验会得到多大程度的提升?
评价指标可以是DCG等。由于观测数据是有偏的,与3.1中的描述相似,最终的评价指标也是有偏的。
3.3 基于倾向分数的性能评估
解决selection bias的关键在于理解观测数据的生成机制(Assignment Mechanism),包含系统生成(Experimental Setting)和用户选择(Observational Setting)两种因素。
为了解决评测指标的偏差问题,作者提出使用逆倾向分数对观察数据加权,构建一个对理想评测指标的无偏估计器——IPS Estimator:
\mathbb{E}_{O}\left[\hat{R}_{I P S}(\hat{Y} | P)\right] =\frac{1}{U \cdot I} \sum_{u} \sum_{i} \mathbb{E}_{O_{u, i}}\left[\frac{\delta_{u, i}(Y, \hat{Y})}{P_{u, i}} O_{u, i}\right] \\
=\frac{1}{U \cdot I} \sum_{u} \sum_{i} \delta_{u, i}(Y, \hat{Y})=R(\hat{Y})
\]
其中\(O_{u,i} ~ Bernoulli(P_{u,i})\),\(P_{u,i}\)为propensity score。
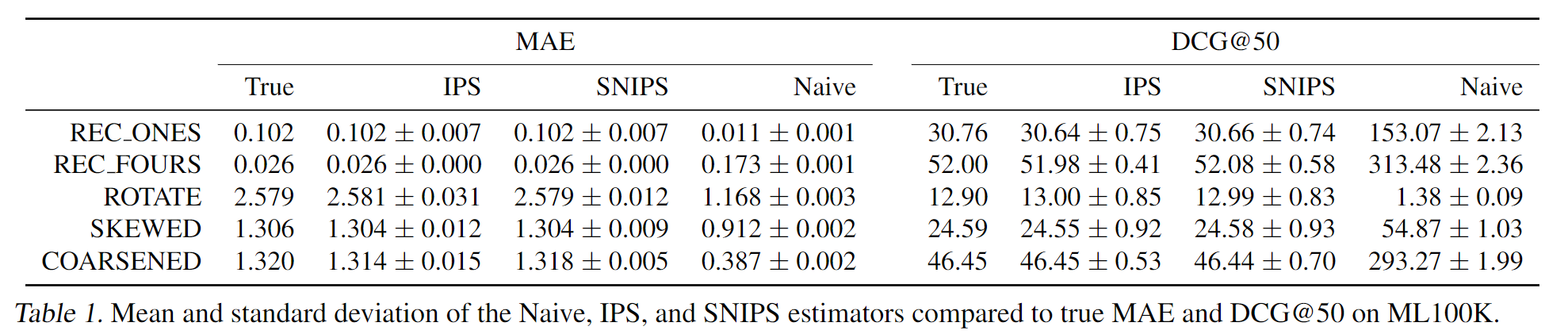
3.4 实验验证
利用MF生成的全曝光模拟数据集,作者设计了几种评分策略,每种策略都有不同的评分错误。基于真实数据集中的曝光情况,计算曝光交互的评价指标,证明了IPS评价指标能有效抵消selection bias带来的评价误差。
4. IPS推荐系统
基于IPS的推荐系统,训练目标为:
\]
其中\(P_{u,i}\)是倾向性评分,相当于在对应的loss项上加了权重。
5. 倾向性评分的估计
作者提出了两种估计方法
朴素贝叶斯估计
这个方法似乎是对评分相同的u-i交互给出了相同的评分?
\[P\left(O_{u, i}=1 \mid Y_{u, i}=r\right)=\frac{P(Y=r \mid O=1) P(O=1)}{P(Y=r)}
\]逻辑斯特回归
将所有关于u-i对的信息都作为特征,来学习一个线性模型
\[P_{u, i}=\sigma\left(w^{T} X_{u, i}+\beta_{i}+\gamma_{u}\right)
\]
6. 实验
6.1 实验设置
训练集是有偏(MNAR)数据,使用k-折交叉验证来调参,使用无偏数据或者合成的全曝光数据作为测试集。
6.2 采样偏差对评测指标的影响
构建全曝光的合成数据集:在ML 100K数据集上,使用MF 填充所有空缺的评分,并对填充之后的评分分布进行调整,以降低高评分的比例。
实验结果见3.4
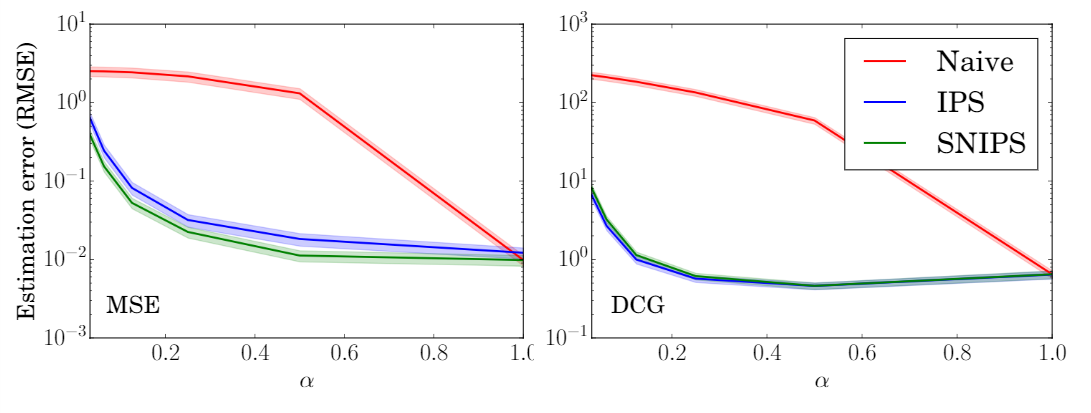
6.3 采样偏差对模型训练的影响
对于不同程度的选择偏差(\(\alpha\)越小,选择偏差越大),实验结果如下图。
可见,IPS-MF和SNIPS-MF的性能要明显优于naive-MF。
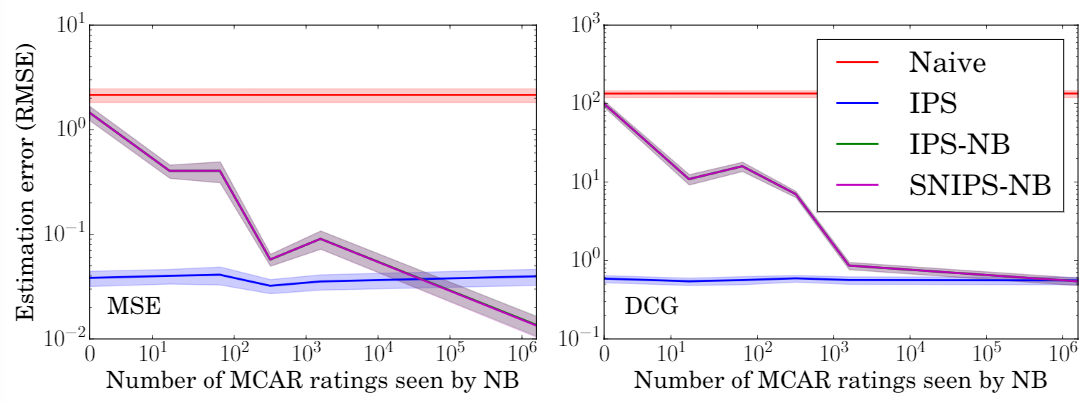
6.4 倾向性评分估计准确度的影响
使用不同比例的数据来估计倾向性评分,可以看出,在所有条件下,IPS和SNIPS都优于MF,验证了模型对倾向性评分的鲁棒性。
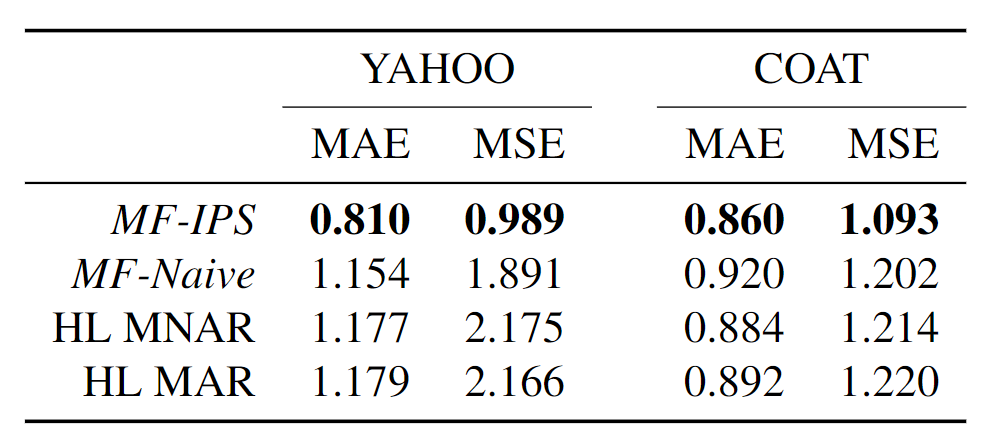
6.5 真实数据集上的性能
Yahoo! R3:使用5%的无偏数据来估计倾向性评分,95%的无偏数据作为测试集。
Coat:本文收集了一个新的无偏数据集Coat(很大的贡献),包含290个user和300个item,每个user自主选择24个商品给出评分,并对16个随机商品给出评分(1-5分)。
实验结果表明,在两个数据集上都优于最好的baseline。
【论文笔记】Recommendations as Treatments: Debiasing Learning and Evaluation的更多相关文章
- 论文笔记(2):A fast learning algorithm for deep belief nets.
论文笔记(2):A fast learning algorithm for deep belief nets. 这几天继续学习一篇论文,Hinton的A Fast Learning Algorithm ...
- 【论文笔记】DeepOrigin: End-to-End Deep Learning for Detection of New Malware Families
DeepOrigin: End-to-End Deep Learning for Detection of New Malware Families 标签(空格分隔): 论文 论文基本信息 会议: I ...
- 论文笔记 - An Explanation of In-context Learning as Implicit Bayesian Inference
这位更是重量级.这篇论文对于概率论学的一塌糊涂的我简直是灾难. 由于 prompt 的分布与预训练的分布不匹配(预训练的语料是自然语言,而 prompt 是由人为挑选的几个样本拼接而成,是不自然的自然 ...
- 论文笔记之: Deep Metric Learning via Lifted Structured Feature Embedding
Deep Metric Learning via Lifted Structured Feature Embedding CVPR 2016 摘要:本文提出一种距离度量的方法,充分的发挥 traini ...
- 论文笔记之:Deep Reinforcement Learning with Double Q-learning
Deep Reinforcement Learning with Double Q-learning Google DeepMind Abstract 主流的 Q-learning 算法过高的估计在特 ...
- 论文笔记之:UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS
UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS ICLR 2 ...
- Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现(转)
Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文, ...
- Deep Learning论文笔记之(八)Deep Learning最新综述
Deep Learning论文笔记之(八)Deep Learning最新综述 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但老感觉看完 ...
- Deep Learning论文笔记之(六)Multi-Stage多级架构分析
Deep Learning论文笔记之(六)Multi-Stage多级架构分析 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些 ...
随机推荐
- 重写(Override)与重载(Overload)区别
重写是子类对父类的允许访问的方法的实现过程进行重新编写. 方法重写三要素: (1)方法名形参列表相同: (2)返回值类型和声明异常类型子类小于父类: (3)访问权限,子类大于等于父类. 重写的好处在于 ...
- 解决异常:“The last packet sent successfully to the server was 0 milliseconds ago. ”的办法
出现异常"The last packet sent successfully to the server was 0 milliseconds ago."的大部分原因是由于数据库回 ...
- 手把手教你汇编 Debug
关于汇编的第一篇文章: 爱了爱了,这篇寄存器讲的有点意思 Hello大家好,我是程序员cxuan!我们上篇文章了解了一下基本的寄存器,这篇文章我们来进行实际操作一下. 原文链接:手把手教你汇编 Deb ...
- [atARC119D]Grid Repainting 3
将每一行和每一列分别作为一个点,当第$i$行第$j$列的格子为红色时,将第$i$行与第$j$列连边 此时,考虑选择第$i$行的红色格子并将第$i$行的格子全部改成白色: 关于这一操作的条件,即需要第$ ...
- CF713C Sonya and Problem Wihtout a Legend
考虑我们直接选择一个暴力\(dp\). \(f_{i,j} = min_{k<=j}\ (f_{i - 1,k}) + |a_i - j|\) 我们考虑到我们直接维护在整个数域上\(min(f_ ...
- RepeatModeler安装及使用
如果进行重复序列的预测,则使用RepeatModeler,可自身比对进行查找 安装 (1)下载地址:http://www.repeatmasker.org/RepeatModeler/ (2)Repe ...
- EXCEL-批量下拉填充
3.批量下拉填充 => 全选->Ctrl+G定位空值->随意找一个空白单元格输入=还有此单元格想要填充的内容->按Ctrl+Enter,等待几秒,即可,批量下拉填充:
- spl_autoload_register的作用
spl_autoload_register的作用 当php实例化一个类的时候,这个类如果在另外的文件,那么不用include或require的时候就会报错,为了解决这个问题,可以用spl_autolo ...
- C 语言中求中间数时候防止溢出方法
当使用二分法时候,注意 mid = left + (right - left) / 2; 这句代码,可以防止溢出!!,千万不能写成 mid = (left + right) / 2 这样写的话,当数字 ...
- 零基础学习java------day7------面向对象
1. 面向对象 1.1 概述 面向过程:c语言 面向对象:java :python:C++等等 面向对象的概念: (万物皆对象)------think in java everything in ...