潭州课堂25班:Ph201805201 爬虫高级 第六课 sclapy 框架 中间建 与selenium对接 (课堂笔记)
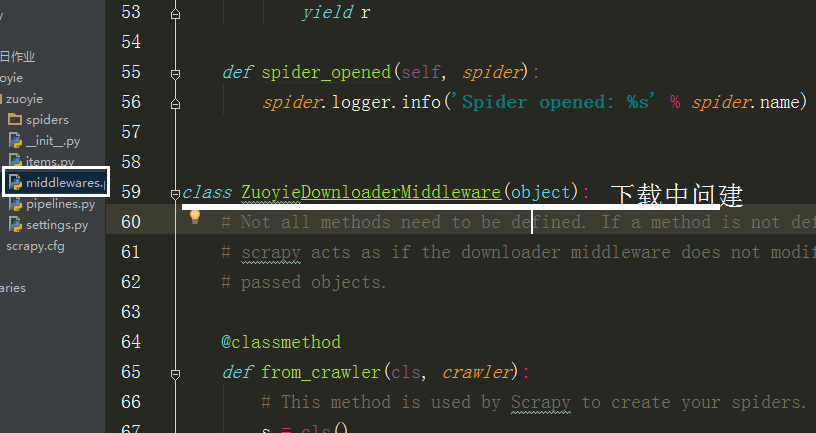


因为每次请求得到的响应不一定是正常的,

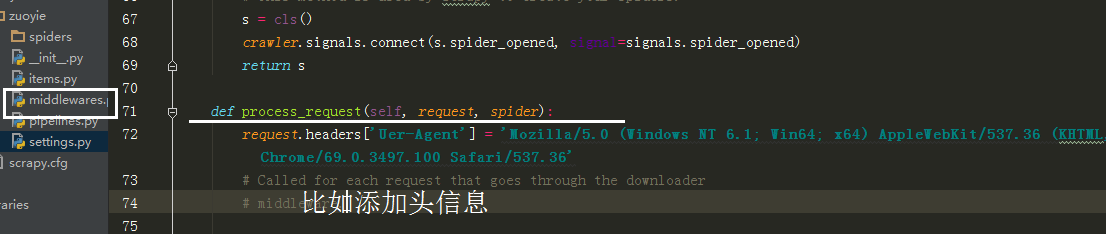
也可以在中间建中与个类的方法,自动更换头自信,代理Ip,
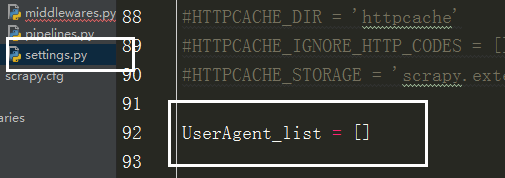
在设置文件中添加头信息列表,
在中间建中导入刚刚的列表,和随机函数
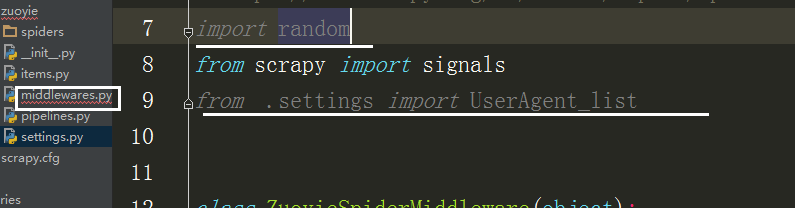
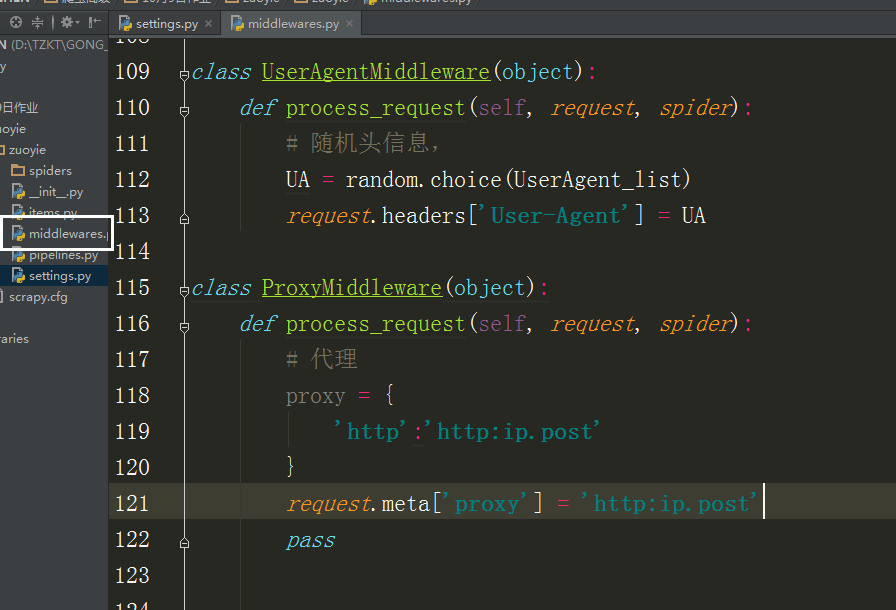
class UserAgentMiddleware(object):
def process_request(self, request, spider):
# 随机头信息,
UA = random.choice(UserAgent_list)
request.headers['User-Agent'] = UA class ProxyMiddleware(object):
def process_request(self, request, spider):
# 代理
proxy = {
'http':'http:ip.post'
}
request.meta['proxy'] = 'http:ip.post'
pass
scrapy与 selenium
以 历史空气质量数据 网站为列:
https://www.aqistudy.cn
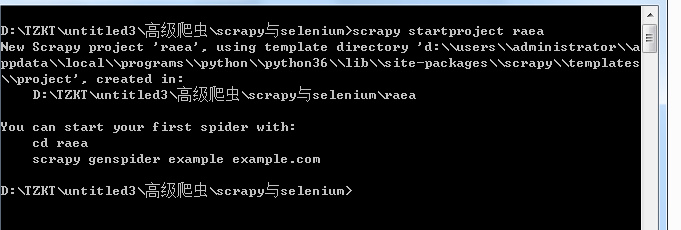
建一项目 scrapy startproject raea
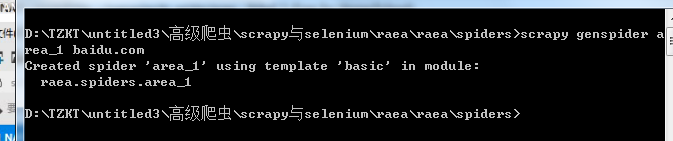
创建运行文件 scrapy genspider area_1 baidu.com

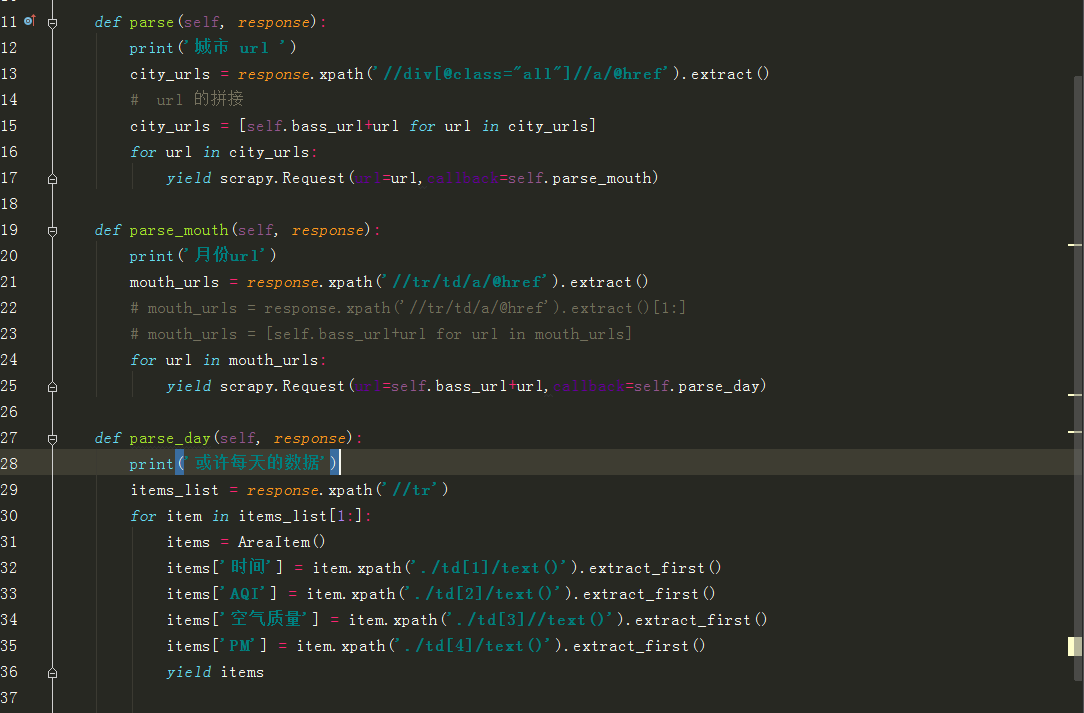
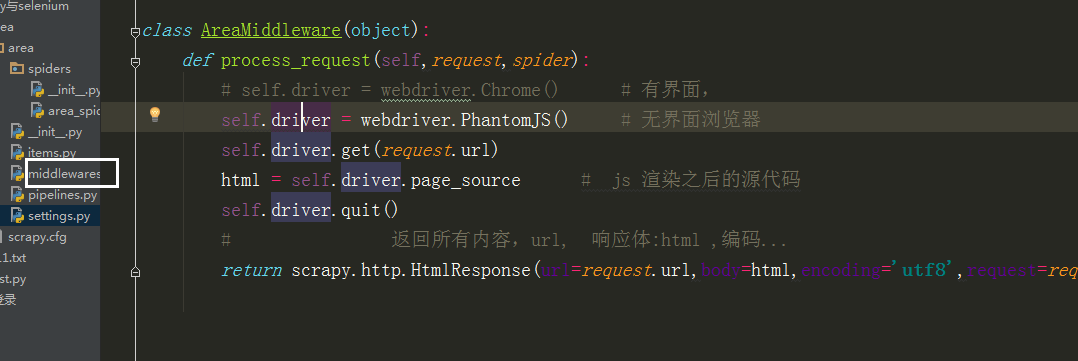
写好后无法获取数据,是因为 scrapy 无法执行 js 获取数据 ,
所以要在中间建 中自己写个类,
在 middlewares 中导入selenium

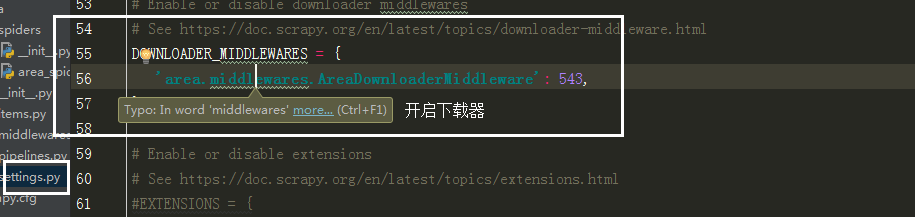
里边的类名改成自己写的那个类方法

潭州课堂25班:Ph201805201 爬虫高级 第六课 sclapy 框架 中间建 与selenium对接 (课堂笔记)的更多相关文章
- 潭州课堂25班:Ph201805201 爬虫高级 第七课 sclapy 框架 爬前程网 (课堂笔)
定时对该网页数据采集,所以每次只爬第一个页面就可以, 创建工程 scrapy startproject qianchen 创建运行文件 cd qianchenscrapy genspider qian ...
- 潭州课堂25班:Ph201805201 爬虫高级 第五课 sclapy 框架 日志和 settings 配置 模拟登录(课堂笔记)
当要对一个页面进行多次请求时, 设 dont_filter = True 忽略去重 在 scrapy 框架中模拟登录 创建项目 创建运行文件 设请求头 # -*- coding: utf-8 ...
- 潭州课堂25班:Ph201805201 爬虫高级 第四课 sclapy 框架 crawispider类 (课堂笔记)
以上内容以 spider 类 获取 start_urls 里面的网页 在这里平时只写一个,是个入口,之后 通过 xpath 生成 url,继续请求, crawispider 中 多了个 rules ...
- 潭州课堂25班:Ph201805201 爬虫高级 第三课 sclapy 框架 腾讯 招聘案例 (课堂笔记)
到指定目录下,创建个项目 进到 spiders 目录 创建执行文件,并命名 运行调试 执行代码,: # -*- coding: utf-8 -*- import scrapy from ..items ...
- 潭州课堂25班:Ph201805201 爬虫高级 第八课 AP抓包 SCRAPY 的图片处理 (课堂笔记)
装好模拟器设置代理到 Fiddler 中, 代理 IP 是本机 IP, 端口是 8888, 抓包 APP斗鱼 用 format 设置翻页
- 潭州课堂25班:Ph201805201 爬虫高级 第十三 课 代理池爬虫检测部分 (课堂笔记)
1,通过爬虫获取代理 ip ,要从多个网站获取,每个网站的前几页2,获取到代理后,开进程,一个继续解析,一个检测代理是否有用 ,引入队列数据共享3,Queue 中存放的是所有的代理,我们要分离出可用的 ...
- 潭州课堂25班:Ph201805201 爬虫高级 第十一课 Scrapy-redis分布 项目实战 (课堂笔
- 潭州课堂25班:Ph201805201 爬虫高级 第十课 Scrapy-redis分布 (课堂笔记)
利用 redis 数据库,做 request 队列,去重,多台数据共享, scrapy 调度 基于文件每户,默认只能在单机运行, scrapy-redis 默认把数据放到 redis 中,实现数据共享 ...
- 潭州课堂25班:Ph201805201 爬虫基础 第六课 选择器 (课堂笔记)
HTML解析库BeautifulSoup4 BeautifulSoup 是一个可以从HTML或XML文件中提取数据的Python库,它的使用方式相对于正则来说更加的简单方便,常常能够节省我们大量的时间 ...
随机推荐
- C++:explicit关键字
在C++中,如果一个类的构造函数只有一个形参,在这种情况下,可以直接将一个对应于构造函数参数类型的数据直接赋值给类变量,编译器在编译时会自动进行类型转换,将对应于构造函数参数类型的数据转换为类的对象, ...
- 关于报错stale element reference: element is not attached to the page document处理
1.现象 在执行脚本时,有时候引用一些元素对象会抛出如下异常 org.openqa.selenium.StaleElementReferenceException: stale element ref ...
- JAVA中各种日期表示字母
字母 日期或时间元素 表示 示例 G Era 标志符 Text AD y 年 Year 1996; 96 M 年中的月份 Month July; Jul; 07 w 年中的周数 Number 27 W ...
- LINUX-CUDA版本所对应的NVIDIA驱动版本号,cuda版本报错的朋友参考一下
CUDA 10.0: 410.48 CUDA .xx CUDA .xx (update) CUDA .xx CUDA .xx (GA2) CUDA .4x CUDA .xx CUDA .xx CUDA ...
- Android 截屏与 WebView 长图分享经验总结
最近在做新业务需求的同时,我们在 Android 上遇到了一些之前没有碰到过的问题,截屏分享. WebView 生成长图以及长图在各个分享渠道分享时图片模糊甚至分享失败等问题,在这过程中踩了很多坑,到 ...
- process.cwd()与__dirname的区别
process.cwd() 是当前执行node命令时候的文件夹地址 ——工作目录,保证了文件在不同的目录下执行时,路径始终不变__dirname 是被执行的js 文件的地址 ——文件所在目录 Node ...
- PHP 抽象类
* 抽象类 * 1.使用关键字: abstract * 2.类中只要有一个方法声明为abstract抽象方法,那么这个类就必须声明为抽象类 * 3.抽象方法只允许有方法声明与参数列表,不允许有方法体; ...
- poj3585 树形dp 二次扫描,换根法模板题
#include<iostream> #include<cstring> #include<cstdio> #include<vector> using ...
- python + selenium 模块封装及参数化
模块封装 示例代码: baidu.py from time import sleep from selenium import webdriver driver = webdriver.Chrome( ...
- python 全栈开发,Day137(爬虫系列之第4章-scrapy框架)
一.scrapy框架简介 1. 介绍 Scrapy一个开源和协作的框架,其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的,使用它可以以快速.简单.可扩展的方式从网站中提取所需的数据.但目前S ...