机器学习-Kmeans
一、什么是聚类算法?
1、用于发现共同的群体(cluster),比如:邮件聚类、用户聚类、图片边缘。
2、聚类唯一会使用到的信息是:样本与样本之间的相似度(跟距离负相关)
给定N个训练样本(未标记的){x 1 , . . . , x N },同时给定结果聚类的个数K 目标:把比较“接近”的样本放到一个cluster里,总共得到K个cluster

二、不同场景的判定内容
图片检索:图片内容相似度
图片分割:图片像素(颜色)相似度
网页聚类:文本内容相似度
社交网络聚类:(被)关注人群,喜好,喜好内容
电商用户聚类:点击/加车/购买商品,行为序列…
三、样本—向量—距离

四、Kmeans聚类和层次聚类
Kmeans聚类:
得到的聚类是一个独立于另外一个的


收敛:
聚类中心不再有变化 每个样本到对应聚类中心的距离之和不再有很大变化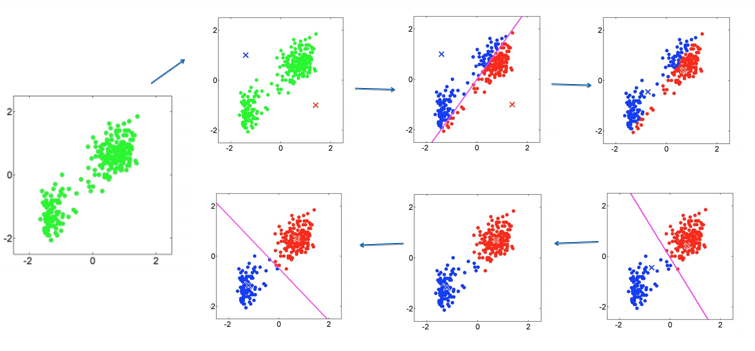
层次聚类:
可以看做树状层叠 无需初始输入聚类个数

k-means聚类与层次聚类区别:
kmeans每次聚类产生一个聚类结果,层次聚类可以通过聚类程度不同产生不同结果 kmeans需要指定聚类个数K,层次聚类不用 kmeans比层次聚类更快 kmeans用的多,且可以用k-median
五、损失函数

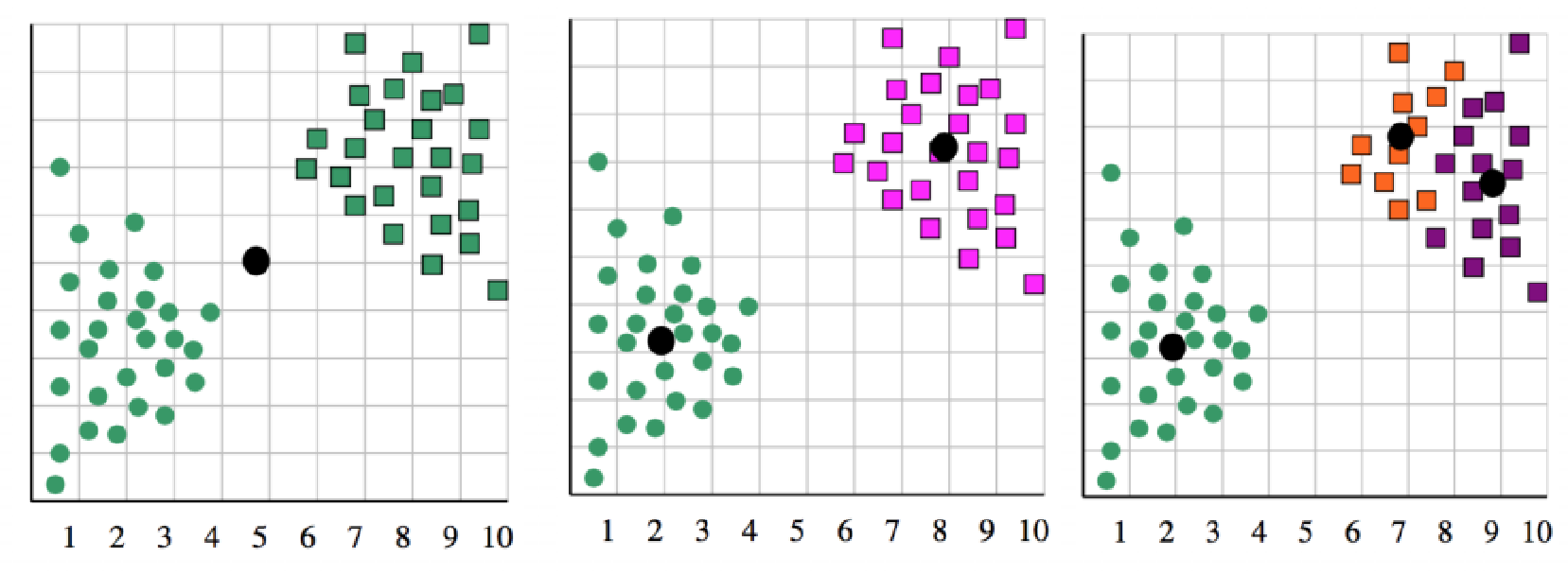
六、K的选定
k值得影响:
k过大过小对结果都不好
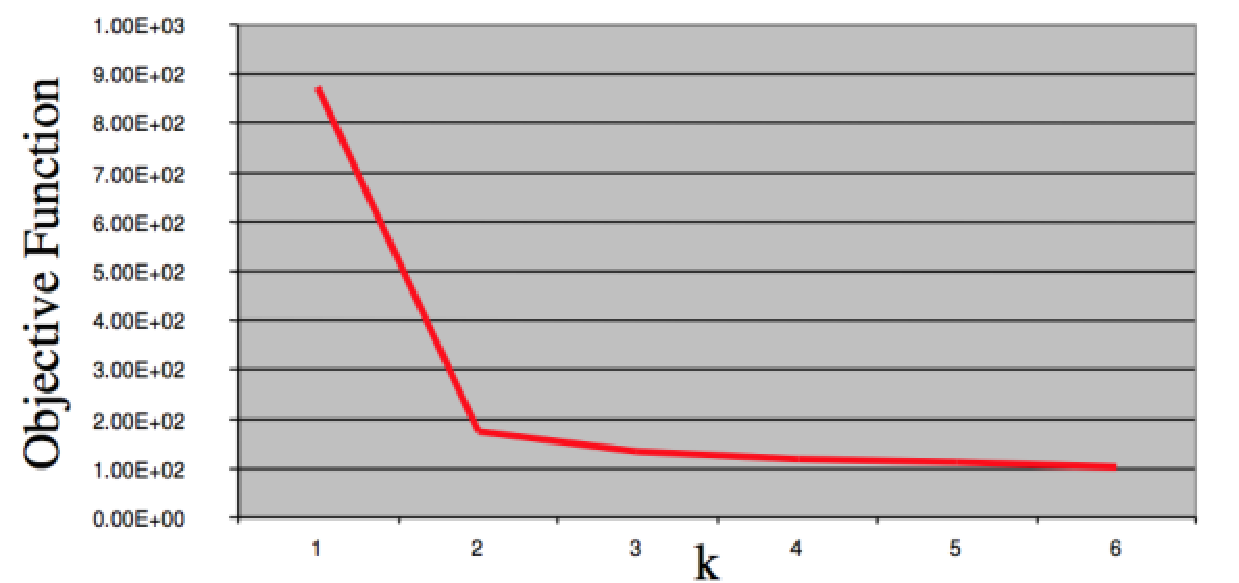
“肘点”法:
选取不同的K值,画出损失函数曲线,选取“肘点”值
七、优缺点
优点:
1. 易于理解,聚类效果不错;
2. 处理大数据集的时候,该算法可以保证较好的伸缩性和高效率;
3. 当簇近似高斯分布的时候,效果非常不错 。
缺点:
1. k值是用户给定的,进行数据处理前,k值是未知的,不同的k值得到的结果不一样;
2. 对初始簇中心点是敏感的;
3. 对于团状的数据点集区分度好,对于带状(环绕)等“非凸”形状不太好。(用谱聚类或者做特征映射)
4. 对异常点的“免疫力”很差,我们可以通过一些调整(比如中心不直接取均值,而是找均值最近的样本点代替)
八、代码示例
import random
import matplotlib.pyplot as plt class Kmeans():
def __init__(self,k):
'''
初始化
param k:代表聚类中心个数
'''
self.__k=k
self.__data = [] #存放原始数据
self.__pointCenter = [] #存放聚类中心点
self.__result = [] #存放最后的聚类结果
for i in range(k):
self.__result.append([]) def calDistance(self,points1,points2):
'''
欧氏距离:sprt(x1-x2)^2+(y1-y2)^2
param points1:一维列表
param points2:一维列表
return:两点之间直线距离
'''
distance = (sum([(x1-x2)**2 for x1,x2 in zip(points1, points2)]))**0.5 #开平方
return distance def randomCenter(self):
'''
生成self.__pointCenter:初次聚类中心点列表
return:
'''
while len(self.__pointCenter)<self.__k:
index = random.randint(0,len(self.__data)) #得到0到len(self.__data)-1之间的索引
if self.__data[index] not in self.__pointCenter: #用索引值得到列表的值
self.__pointCenter.append(self.__data[index]) def calPointToCenterDistance(self,data,center):
'''
计算每个店和聚类中心之间的距离
param data:原始数据
param center:中心聚类点
return:距离
'''
distance = []
for i in data:
distance.append([self.calDistance(i,centerpoint) for centerpoint in center])
return distance def sortPoint(self,distance):
'''
对原始数据进行分类,将每个点分到离它最近的聚类中心点
param distance:得到的距离
return:返回最终的分类结果
'''
for i in distance:
index = i.index(min(i)) #得到五个距离之中的最小值的索引
self.__result[index].append(self.__data[i]) #通过索引进行分类
return self.__result def calNewCenterPoint(self,result):
'''
计算新的中心点:通过生成新的聚类求取新的平均值
param result:分类结果
return:返回新的聚类中心点
'''
newCenterPoint1 = []
for temp in result:
#进行转置,将N*M转为M*N形式,将所有point.x值和point,y值撞到一个列表中,便于求取新的平均值
temps = [[temp[x][i] for x in range(len(temp))] for i in range(len(temp[0]))]
point = []
for i in temps:
point.append(sum(i)/len(i)) #求和再除以数组长度,求取平均值
newCenterPoint1.append(point)
return newCenterPoint1 def calCenterToCenterDistance(self,old,new):
'''
迭代结束条件
计算新旧中心点之间的距离
param old:
param new:
return:
'''
total = 0
for point1,point2 in zip(old,new):
total += self.calDistance(point1,point2)
return total/len(old) def fit(self,data,threshold,time=50000):
self.__data = data
self.randomCenter()
print(self.__pointCenter)
centerDistance = self.calPointToCenterDistance(self.__data,self.__pointCenter) #对原始数据进行分类,将每个点分到离它最近的中心点
i = 0
for temp in centerDistance:
index = temp.index(min(temp))
self.__result[index].append(self.__data[i])
i +=1
#打印分类结果
print(self.__result)
oldCenterPoint = self.__pointCenter
newCenterPoint = self.calNewCenterPoint(self.__result)
while self.calCenterToCenterDistance(oldCenterPoint,newCenterPoint) > threshold:
time -= 1
result = []
for i in range(self.__k):
result.append([])
#保存上次的中心点
oldCenterPoint = newCenterPoint
centerDistance = self.calPointToCenterDistance(self.__data,newCenterPoint)
#对原始数据进行分类,将每个点分到离它最近的中心点
i = 0
for temp in centerDistance:
index = temp.index(min(temp))
result[index].append(self.__data[i])
i += 1
newCenterPoint = self.calNewCenterPoint(result)
print(self.calCenterToCenterDistance(oldCenterPoint,newCenterPoint))
self.__result = result
self.__pointCenter = newCenterPoint
return newCenterPoint,self.__result if __name__ == "__main__":
data = []
k = 6 #分类数量
for i in range(len(data)):
kmeans = Kmeans(k=k)
centerPoint,result = kmeans.fit(data,0.0001)
print(centerPoint)
plt.plot()
plt.title('Kmeans')
i = 0
tempx = []
tempy = []
color = []
for temp in result:
temps = [[temp[x][i] for x in range(len(temp))] for i in range(len(temp[0]))]
color += [i]*len(temps[0])
tempx += temps[0]
tempy += temps[1]
i+=2
plt.scatter(tempx,tempy,c=color,s=30)
plt.show()
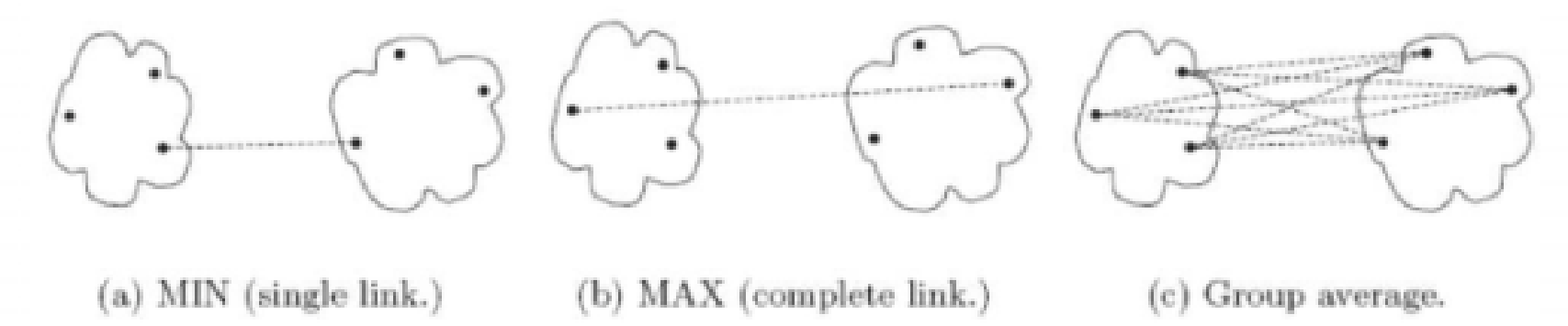
九、层次聚类
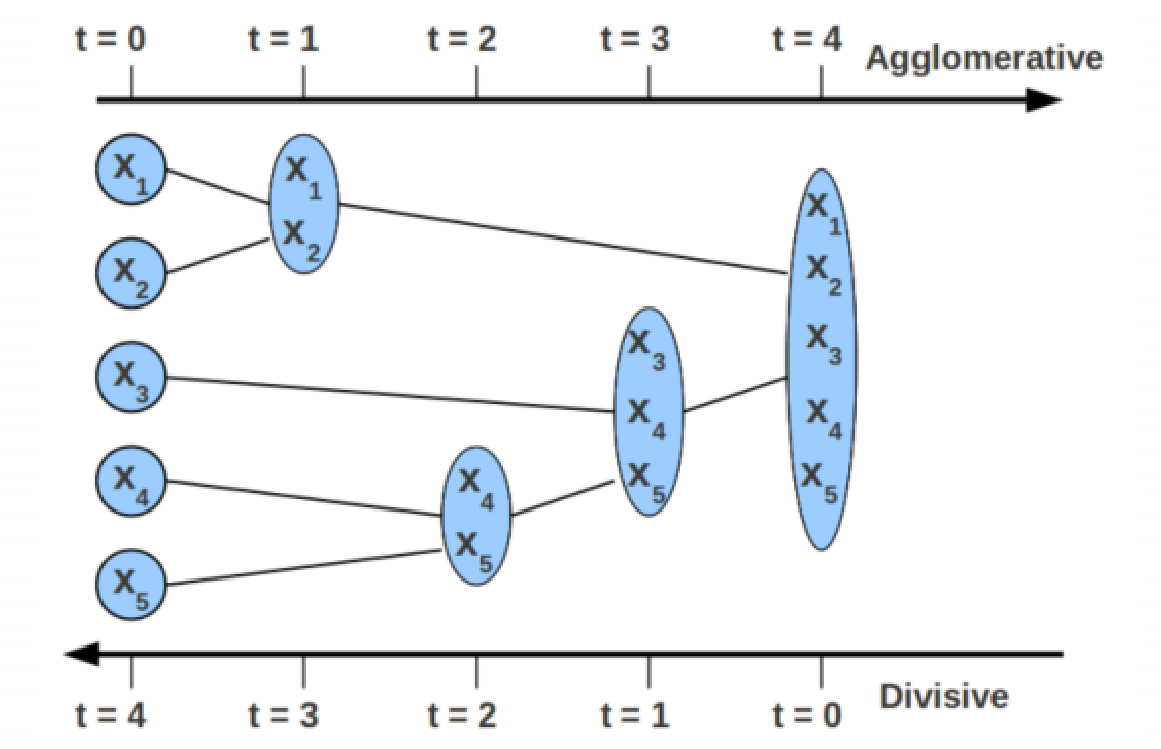
cluster R和cluster S之间距离怎么界定?

机器学习-Kmeans的更多相关文章
- 视觉机器学习------K-means算法
K-means(K均值)是基于数据划分的无监督聚类算法. 一.基本原理 聚类算法可以理解为无监督的分类方法,即样本集预先不知所属类别或标签,需要根据样本之间的距离或相似程度自动进行分类.聚 ...
- 机器学习——KMeans聚类,KMeans原理,参数详解
0.聚类 聚类就是对大量的未知标注的数据集,按数据的内在相似性将数据集划分为多个类别,使类别内的数据相似度较大而类别间的数据相似度较小,聚类属于无监督的学习方法. 1.内在相似性的度量 聚类是根据数据 ...
- 机器学习-kmeans的使用
import numpy as np import pandas as pd import matplotlib from matplotlib import pyplot as plt %matpl ...
- 机器学习——KMeans
导入类库 from sklearn.cluster import KMeans from sklearn.datasets import make_blobs import numpy as np i ...
- 机器学习--k-means聚类原理
“物以类聚,人以群分”, 所谓聚类就是将相似的元素分到一"类"(有时也被称为"簇"或"集合"), 簇内元素相似程度高, 簇间元素相似程度低. ...
- Python之机器学习K-means算法实现
一.前言: 今天在宿舍弄了一个下午的代码,总算还好,把这个东西算是熟悉了,还不算是力竭,只算是知道了怎么回事.今天就给大家分享一下我的代码.代码可以运行,运行的Python环境是Python3.6以上 ...
- 机器学习K-Means
1.K-Means聚类算法属于无监督学习算法. 2.原理:先随机选择K个质心,根据样本到质心的距离将样本分配到最近的簇中,然后根据簇中的样本更新质心,再次计算距离重新分配簇,直到质心不再发生变化,迭代 ...
- 09-赵志勇机器学习-k-means
(草稿) k-means: 1. 随机选取n个中心 2. 计算每个点到各个中心的距离 3. 距离小于阈值的归成一类. 4. 计算新类的质心,作为下一次循环的n个中心 5. 直到新类的质心和对应本次循环 ...
- 机器学习-K-means聚类及算法实现(基于R语言)
K-means聚类 将n个观测点,按一定标准(数据点的相似度),划归到k个聚类(用户划分.产品类别划分等)中. 重要概念:质心 K-means聚类要求的变量是数值变量,方便计算距离. 算法实现 R语言 ...
- 机器学习 - k-means聚类
k-means简介 k-means是无监督学习下的一种聚类算法,简单说就是不需要数据标签,仅靠特征值就可以将数据分为指定的几类.k-means算法的核心就是通过计算每个数据点与k个质心(或重心)之间的 ...
随机推荐
- [题解][YZOJ50113] 枇杷树
简要题意 \(m\) 个操作,每次操作都会产生一个树的版本 \((\)从 \(0\) 开始\()\). 一次操作把 \(x_i\) 版本的树的点 \(u\) 和 \(y_i\) 版本的树的点 \(v\ ...
- 为什么不建议给MySQL设置Null值?《死磕MySQL系列 十八》
大家好,我是咔咔 不期速成,日拱一卒 之前ElasticSearch系列文章中提到了如何处理空值,若为Null则会直接报错,因为在ElasticSearch中当字段值为null时.空数组.null值数 ...
- HttpResponse,render,redirect,静态文件配置,request对象方法,pycharm连接MySQL,django连接MySQL,django ORM
HttpResponse 主要用于返回字符串类型的数据 def index(request): return HttpResponse('index页面') 在页面中就会显示 index页面 rend ...
- linux篇-centos7安装DHCP服务器
1检查防火墙和selinux(关闭) 关闭防火墙和selinux,这边不多说 2检查DHCP状态 3安装DHCP软件包 4把系统默认的样例复制 5修改配置文件 option domain-name & ...
- 抽象数据类型(ADT)
抽象数据类型(Abstract Data Type,ADT)是指一个数学模型以及定义在这个模型上的一组操作.抽象数据类型的定义仅仅取决于它的一组逻辑特性,而与它在计算机中的表示和实现无关. 例如,in ...
- dpkg-DEB包管理器
dpkg是Deb系列发行版操作系统下.deb软件包管理器. 语法 dpkg [option] [package] 选项 -i 安装Deb软件包. -r 删除Deb软件包. -P 删除Deb软件包的同时 ...
- Redis快速度特性及为什么支持多线程及应用场景
转载请注明出处: 目录 1.Redis 访问速度快特性 2.Redis 6.0 为什么支持多线程? 3.Redis可以做什么 3.1.缓存 3.2.排行榜系统 3.3.计数器应用 3.4.社交网络 3 ...
- 开源流程引擎osworkflow、jbpm、activiti、flowable、camunda哪个好?
市场上比较有名的开源流程引擎有osworkflow.jbpm.activiti.flowable.camunda.其中:Jbpm4.Activiti.Flowable.camunda四个框架同宗同源, ...
- 认识一下什么是JSP
摘要:JSP,全称是Java Server Pages,即Java服务器页面,是由Sun Microsystems公司主导创建的一种动态网页技术标准. 本文分享自华为云社区<Java服务器页面- ...
- 前端ES6 特性兼容查询
ES6 http://kangax.github.io/compat-table/es6/ ES5 http://kangax.github.io/compat-table/es5/ ES 2016+ ...